Fatma retweetledi

one of the most important things I know about deep learning I learned from this paper: "Pretraining Without Attention"
this what I found so surprising:
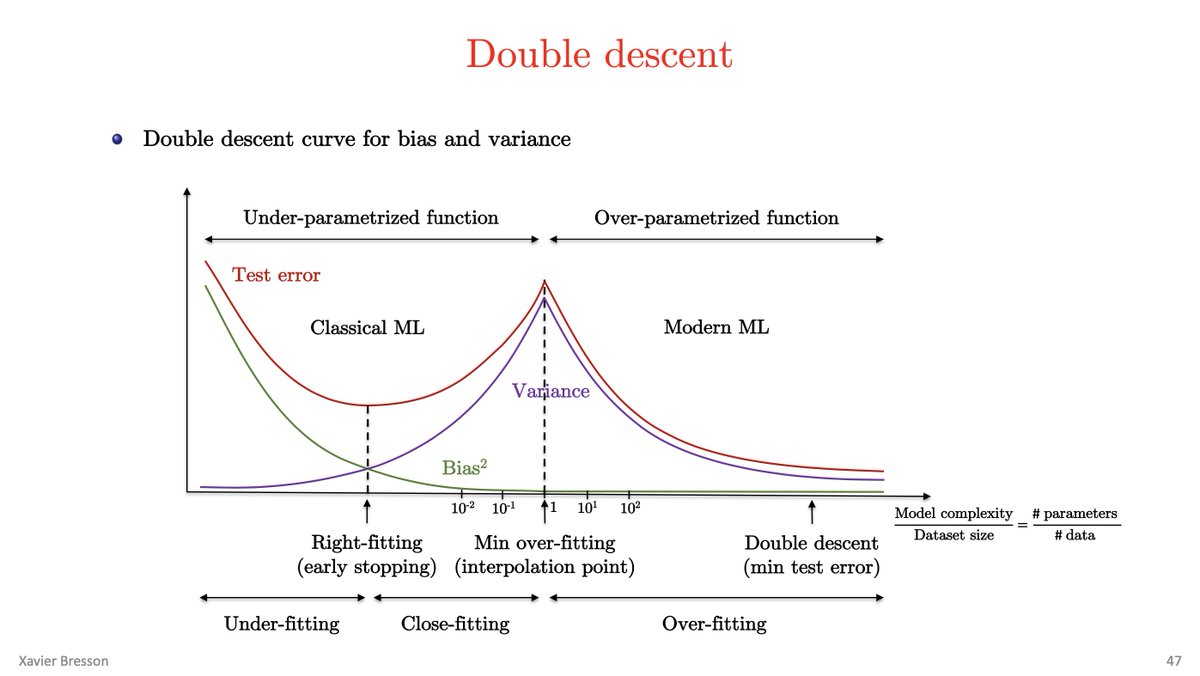
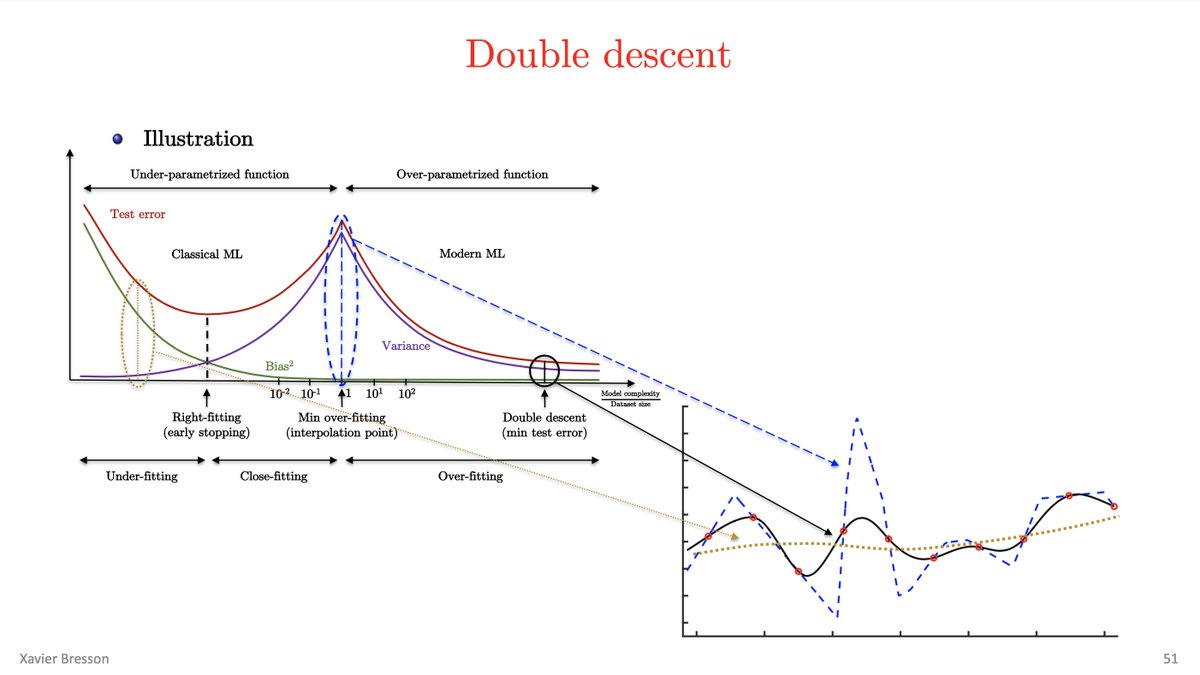
these people developed an architecture very different from Transformers called BiGS, spent months and months optimizing it and training different configurations, only to discover that at the same parameter count, a wildly different architecture produces identical performance to transformers
this may imply that as long as there are enough parameters, and things are reasonably well-conditioned (i.e. a decent number of nonlinearities and and connections between the pieces) then it really doesn't matter how you arrange them, i.e. any sufficiently good architecture works just fine
i feel there's something really deep here, and we may be already very close to the upper bound of how well we can approximate a given function given a certain amount of compute. so we should spend more time thinking about other questions, such as what that function should actually look like (what data? which objective function?) and how to make it more efficient

English