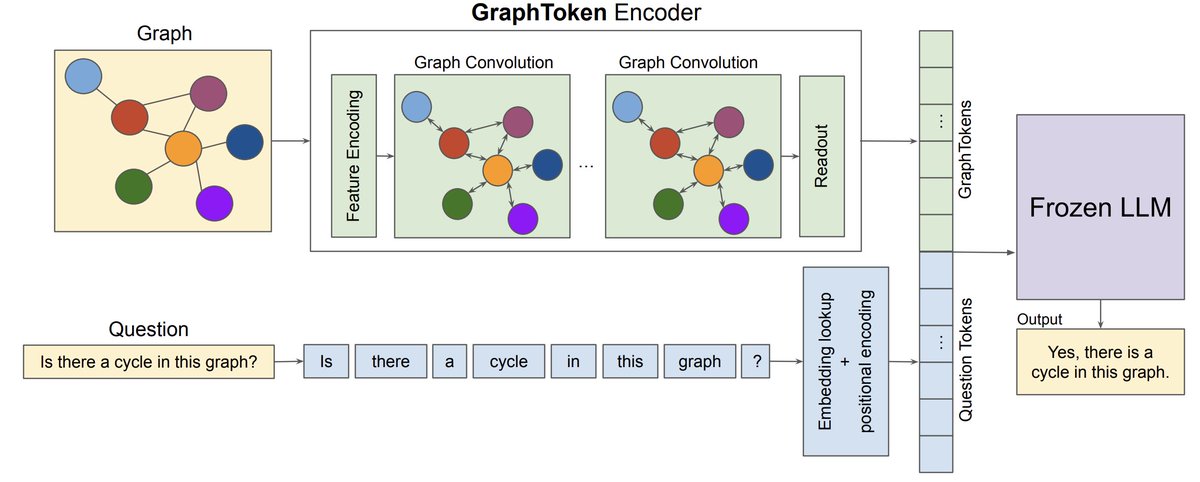
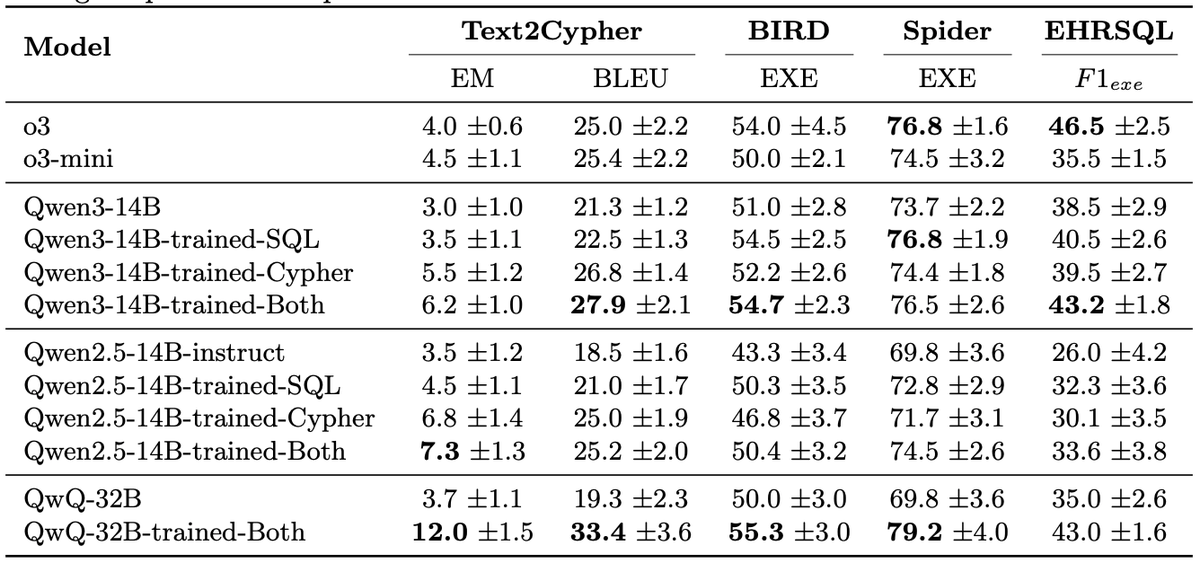
@__YuWang__ @zxlzr Someone might find interesting our analysis on structured memorization.
We analyze how LLMs memorize Knowledge Graphs like DBpedia and Wikidata and reuse them for solving downstream tasks like #TextToSPARQL.
Link: arxiv.org/abs/2505.15501
English