
IAmALurker
963 posts


@joelhedwards It’s all about timing. Bluffdale and Eagle Mountain predated the AI backlash. The last several months have seen a massive spike in anti-data center backlash. Drop either of those projects into April 2026 and the reaction looks identical to this.
English
The conversation around Stratos has gotten badly unmoored from the actual proposal, and it’s worth addressing the biggest misconceptions before the vote.
The loudest claim is that this project will draw more power than the entire state. True at full buildout. Beside the point, because Stratos generates its own power on site. It doesn't draw from the public grid. Last year the legislature passed SB 132 precisely for large private loads that build and operate their own generation off-grid. Utah's existing 4 GW stays where it is. Electricity bills won’t go up because of this project. The "more than the whole state" line sounds scary to some, but falls apart the second you dig in.
The water claim deserves more care than it's been getting. The water rights at issue are existing agricultural rights. Bar H Ranch is transferring 1,900 acre-feet currently used for irrigation. This is not new pressure on the basin, but a reallocation. The data center cooling itself is closed-loop. The gas plant will use some water for power generation, and we should want the developer to specify how much; that's a fair ask. But the framing that Stratos is "draining the lake" assumes new diversions that don't exist in the actual filings. The Great Salt Lake is in real trouble, and most of that trouble has names. Stratos isn't one of them.
The tax-giveaway argument frustrates me the most, because it imagines a counterfactual that doesn't exist and ignores the actual math. The reduced energy is the price of getting the project to land here instead of in Texas or Wyoming. Even at 0.5%, the county pulls in roughly $30M a year in Phase 1, and over $100M annually at full buildout. The state pulls in roughly $49M. The developer is prepaying the county $5.4M a year for the first three years to fund emergency services before tax revenue starts. The developer is paying for every road, sewer line, and stormwater system in the project area and deeding it to the county. If specialized fire equipment is needed, the developer pays for that too. Two thousand permanent jobs in a part of Utah that has been waiting a long time for a real employer. None of that exists if the answer is no.
And the site is the part of the case I keep waiting for someone to make. Hansel Valley is unincorporated, sparsely populated, sits on the Ruby Pipeline, and is adjacent to military infrastructure with strong reasons to want resilient on-site power. The land is doing nothing else. It has been, in policy terms, waiting for this.
I'll grant the strongest version of the critique. The process moved fast, and the commissioners felt blindsided. That's a real complaint and worth fixing in how these things come to the county next time. But the choice today isn't between this Stratos and a better Stratos. It's between this Stratos and the same project getting built somewhere else.
The country has decided, at the level of abstraction, that it wants to lead on AI. You don't get to keep saying yes to the abstraction and no to every concrete project that would make the abstraction real.
The Salt Lake Tribune@sltrib
Box Elder County commissioners are poised to cast a key vote that could clear the way for one of the biggest projects in Utah's history. sltrib.com/news/2026/05/0…
English
@phil_lyman There's a lot of space out in Sanpete county let's see if Cox will vouch for that.
English

This is a huge project that could permanently change Box Elder County and Utah. The project is on a scale that we have never seen before in this state.
Projects like this require FULL TRANSPARENCY and public input.
Sometimes that means the project may not go forward and that’s okay. It’s your community and you get to decide how it is developed.
I will be going to Box Elder on Monday to learn more about this project and see if MIDA is being transparent with the local community about the concerns being raised about water use, jobs, noise and light pollution, etc.
I’ll see you Monday!
English
@opencode Honest request you've done the 3x thing, but I used all my included usage before you started doing that, now I can't even try deepseek because it's not on Zen. Any relief for people like me?
English

@myxburneracct @FiredUpCoug @FiredUpCoug this is the most realistic non confrontational solution I've seen so far.
English

@FiredUpCoug A motion-activated sprinkler turret near where the dogs pee
English

My neighbor’s two large dogs are pooping/peeing in my yard, and the urine is killing patches of our grass.
We’ve already talked to their owner about it, but nothing has changed.
Has anyone dealt with this successfully?
Any advice to keep the dogs from doing this?
Not trying to start a neighbor war, or do anything that will harm the dogs, I just trying to protect our lawn and stop cleaning up after dogs that aren’t ours.

English
@donk8r @RnaudBertrand Do that and deepseek is still proportionally cheaper. This is just an example. But the pricing is based on I/O so the pricing moves with you no matter how much you use ...
English

@RnaudBertrand thats not normal usage, its a retrieval problem. better context selection cuts token burn 5-10x on any provider — the savings from fixing your pipeline dwarf the savings from switching models
English

Hard to calculate exactly without an input/output split but I did the math and for 831,962,136 tokens, Anthropic Opus 4.7 would cost:
- 100% input (floor, unrealistic): 831.96M × $5/M = $4,159.81
- 90/10 (typical for coding agents like opencode — most tokens are codebase context re-fed each turn): $3,743.83 + $2,079.91 = $5,823.74
- 80/20 (more conservative): $3,327.85 + $4,159.81 = $7,487.66
- 50/50 (worst plausible case): $2,079.90 + $10,399.53 = $12,479.43
So that $10.57 DeepSeek bill would probably become roughly $5,000–8,000 on Claude Opus 4.7.
In other words, DeepSeek is 500–700× cheaper, for similar-ish capabilities.
Now you start to understand why Anthropic is worried...
Khalid Warsame@KhalidWarsa
Is DeepSeek V4 Pro cheap? I consumed 831,962,136 tokens in under 2 days and paid $10 for it.
English
IAmALurker retweetledi

Imagine a woman fleeing an attacker—and her car won’t start because it thinks she’s impaired.
Imagine a farmer injured on the job—his truck won’t start because it thinks he’s drunk.
These are the unintended consequences of the Kill Switch mandate.
Kill the Kill Switch.
English
@hiarun02 I think you defined "better", at least for real world use, in your third sentence.
English

@ShamsCharania There's gonna be teams that never get out of being bad. This is dumb. Just get rid of the lottery.
English

The NBA has disclosed to its 30 GMs a singular new anti-tanking reform that expands the draft lottery to 16 teams, flattens odds, and have a relegation zone where the bottom 3 teams are penalized with fewer lottery balls for the No. 1 pick.
ESPN details: espn.com/nba/story/_/id…
English
@joshmanders You clearly haven't used bitbucket in a long time. It's falling behind badly. I just migrated to gitlab from bitbucket. 😂. There are a few UI quirks, but it's like WAY ahead of bitbucket. Bitbucket is in maintenance mode.
English

GitLab was designed by developers with no eye for design but think they do. The UX is atrocious as if they never used their own product.
I'd let GitHub lose another 5-10% uptime before I'd consider switching to BitBucket before I'd consider GitLab.
Sam Lambert@samlambert
@0xblacklight because its an ugly product
English
@thdxr @rcemandev I need it in Zen. Since I've long burned through go monthly... When Zen?
English

@aakashgupta Makes sense. Biggest take away is that society is much less "high trust".
English

BART spent $90 million on new fare gates. They're recovering about $10 million a year in fares.
That's a 9-year payback on paper. The actual return hit in six months.
Embarcadero station went from 112 hours of corrective maintenance in the six months before installation to 2 hours after. Daly City saved 109. Balboa Park saved 75. Across the system, 961 hours of cleanup work disappeared. Corrective maintenance is the term BART uses for graffiti, heavy soiling, vandalism, the damage that needs a crew not a janitor. At several stations it dropped to zero.
Crime fell 41% year over year. Riders who reported seeing fare evasion on their trip dropped from 22% to 10%. Citations issued by BART police went from 2,200 in January to under 1,000 in July, because there was nothing to cite.
The gates were a filtering project disguised as a revenue project.
Old BART gates were waist-high orange fins designed in the 1970s. You could hop them in under a second. That made the station effectively a public space, and the rider mix reflected that. The new gates are 72 inches of polycarbonate with 3D sensors that detect tailgating. You either pay or you don't enter. Once you don't enter, you also don't smoke on the platform, sleep in the elevator, or harass other riders.
BART tried hiring more police for years. Blitz operations at high-traffic stations. Increased patrols. Dedicated transit cops. None of it moved the numbers the way six feet of polycarbonate did.
The $10 million in recovered fares is the smallest line in the return. Fare revenue used to cover 70% of BART operations. After the pandemic it collapsed to 22%. The gates won't fix that gap directly. They fix the precondition for fixing it: a system that office workers, families, and tourists are willing to use again. Ridership growth at stations with new gates outpaced ungated ones before the rollout finished.
A $400 million annual deficit is heading to voters in November as a sales tax measure. Voters don't approve sales taxes for transit agencies they don't feel safe in. The $90 million on gates is buying BART the right to ask the public for more money.
That's the real return on six feet of polycarbonate.


English
@fiago7 Imagine your home city has no team. But you love the sport. You watch another team, become a fan. But then,a team is created in your city. Imagine that. Maybe you don't switch overnight. But one team is actually tied to your community.
English

Never in my life will I understand the concept of changing your team. But I guess Americans are never real fans of any sports team, they are fans of their city and that‘s fair. Just a completely different mentality.
B/R Open Ice@BR_OpenIce
Almost a THOUSAND people showed up to trade a Vegas Golden Knights jersey for a Utah Mammoth jersey before Utah's first home playoff game in franchise history tonight 😅 (via @vincesapienza)
English
@bowtiedmeathead Have the party. But like in the backyard or at a park. 😂
English

My 12 yr old son went to a bday party the other day for one of his friends in the neighborhood.
The party was at Top Golf. About 25 kids give or take.
They rented out 4 bays. Tons of food.
Everyone had a great time.
The previous week he went to a kids party at Dave and Busters. Same deal about 20 kids or so.
Maybe I’m a bit old school (and cheap lol) but we never threw a big group friend’s party like that for the kids.
We always told them they can invite 3-4 of their friends and we’ll take them out somewhere or we would have the entire family come over for cake and ice cream.
Now you got parents out doing one another on these elaborate and expensive bday parties.
Maybe it’s just my generation (I’m 46) with everyone trying to be an overachiever, but if you ask me it’s a bit excessive and over the top.
English
@emollick How does glm score so low on these, yet I trust it so much more than any other Chinese model?
English

I find that open weights models over-perform on benchmarks compared to actual real-world usage, and Kimi feels like no exception.
For example, a small amount of use will show that Kimi is not as good as Claude Opus 4.6, which it beats on the benchmarks.
Still a good model, tho!
Artificial Analysis@ArtificialAnlys
Moonshot’s Kimi K2.6 is the new leading open weights model. Kimi K2.6 lands at #4 on the Artificial Analysis Intelligence Index (54) behind only Anthropic, Google, and OpenAI (all 57) Key takeaways: ➤ Increase in performance on agentic tasks: @Kimi_Moonshot's Kimi K2.6 achieves an Elo of 1520 on our GDPval-AA evaluation, which is a marked improvement over Kimi K2.5’s Elo of 1309. GDPval-AA is our leading metric for general agentic performance, measuring the performance on knowledge work tasks such as preparing presentations and analysis. Models are given code execution and web browsing tools in an agentic loop via our open source reference agentic harness called Stirrup. This continues Kimi K2.6’s strength in tool use, maintaining a 96% score on τ²-Bench Telecom, placing it among other frontier models in this category. ➤ Low hallucination rate: Kimi K2.5 scores 6 on the AA-Omniscience Index, our knowledge evaluation measuring both accuracy and hallucination rate. This score is primarily driven by a comparatively low hallucination rate of 39% (reduced from Kimi K2.5’s 65%), indicating a greater capability to abstain rather than fabricate knowledge when the model is uncertain. Kimi K2.6’s low hallucination rate places it similarly to other models such as Claude Opus 4.7 (36%) and MiniMax-M2.7 (34%) ➤ High token usage: Kimi K2.6 demonstrates high token usage, but is in line with other frontier models in the same intelligence tier. To run the full Artificial Analysis Intelligence Index, Kimi K2.6 used ~160M reasoning tokens. This is slightly lower than Claude Sonnet 4.6 (~190M reasoning tokens) but much higher than GPT 5.4 (~110M reasoning tokens). ➤ Open weights: Kimi K2.6 is a Mixture-of-Experts (MoE) model with 1T total parameters and 32B active, same as the previous two generations of models Kimi K2 Thinking and Kimi K2.5. Kimi K2.6 again pushes the open weights frontier in intelligence. ➤ Third Party Access: Kimi K2.6 is accessible through Moonshot’s First Party API as well as third party API providers Novita, Baseten, Fireworks, and Parasail ➤ Multimodality: Kimi K2.6 supports Image and Video input and text output natively. The model’s max context length remains 256k. Further analysis in the threads below.
English

GLM 5-1 is not Opus 4.7
it's not even Opus 4.6
I see a lot of people claim that it's "just as good"
that's cope
but it's a solid model on a budget
might even be the best budget model right now
I've tried the model plenty and can confidently tell you that it's alright - but alright doesn't earn you a spot in the SOTA stack
English
@BenjaminDEKR Has more to do with survival for him imo. He spoke his truth, got to see behind the curtain, got iced and threatened. Basically he's under duress. Since he can't fix the problem that way (the sound money way) he's pivoting. Kind of two prongs I think explain some of his behavior.
English

I am genuinely curious what changed so dramatically that Elon went from "inflation and government spending will collapse America"
to "government should write endless checks to all Americans and this will create deflation" in, like, 14 months
The supposed reason is "AI" but that didn't suddenly emerge in the last year.
Yet his views on this have taken a full 180 in that same timeframe. To the point that it sounds like a different person entirely.
Still have not seen a coherent explanation.
English
@peter0x44 @KooKiz It isn't 3x better at anything. I Agree 😂.
English

@FreeThoughtFlow @KooKiz I didn't find claude opus 4.6 to be worth 3x, I doubt opus 4.7 will be any better value at those rates. But I'll still give it a try with a few prompts to see.
English

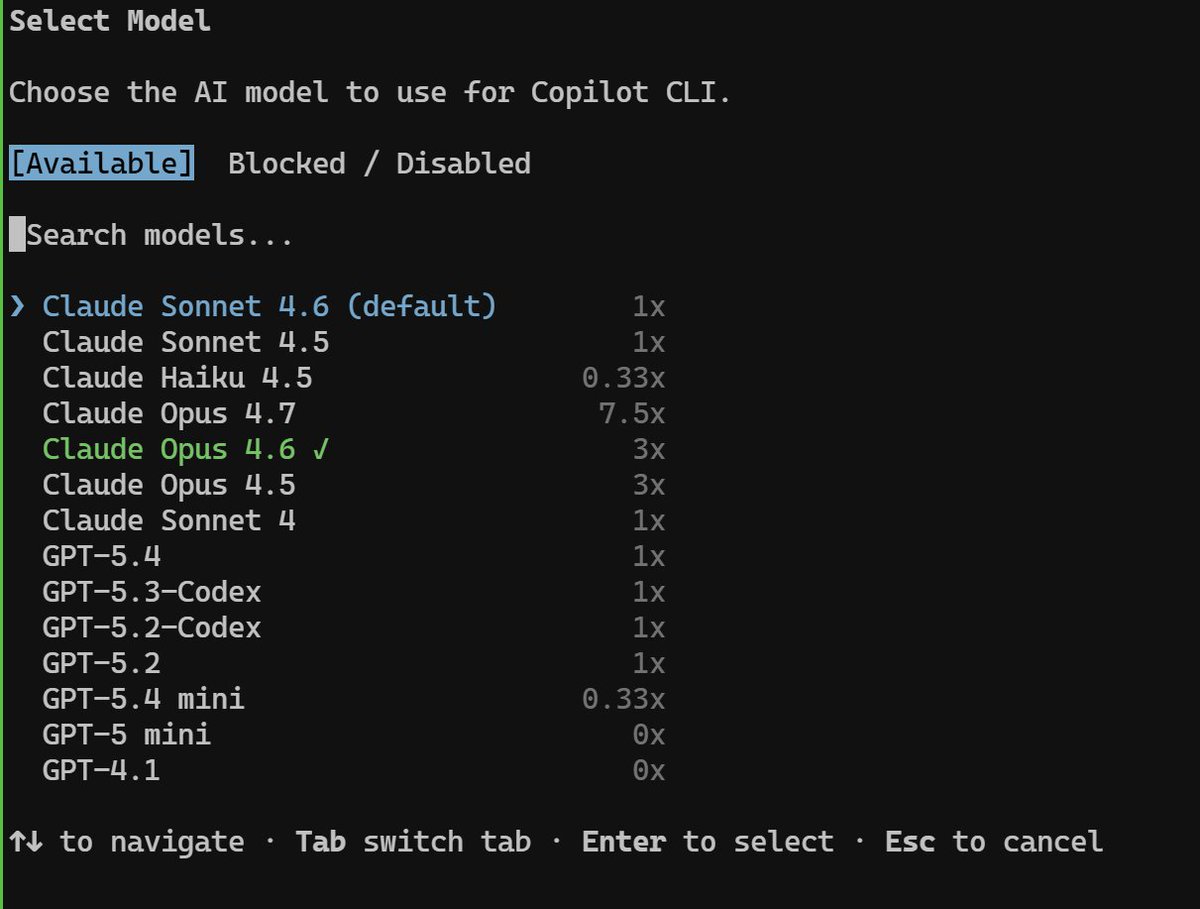
Claude Opus 4.7 is 7.5x on Copilot? Yeeaaah I'll stick to 4.6 for now 😵
English
@peter0x44 @KooKiz I'm pretty sure the underlying cost went up. Not per token. Copilot charges per request and opus 4.6 is reportedly 2x as chatty. Does that make sense?
English
@tvheidihatch For safety concerns? Isn't she the one that loved violence, not the people that were complaining...
English

BREAKING: UVU drops commencement speaker due to 'safety concerns' after intense backlash
"Due to increased safety concerns related to the speaker and in consultation with public safety professionals and Sharon McMahon, Utah Valley University has decided to proceed without a featured commencement speaker for this year’s ceremony," UVU officials said.

English

Liquid nitrogen tank going in at OSH Cut Factory 2.

English