Fzo retweetledi
Fzo
14.8K posts



Fzo retweetledi

NVIDIA releases Nemotron-3-Nano-Omni, a new 30B open multimodal MoE model.
Nemotron-3-Nano-Omni-30B-A3B is the strongest omni model for its size and supports audio, video, image and text.
Run on ~25GB RAM.
GGUF: huggingface.co/unsloth/NVIDIA…
Guide: unsloth.ai/docs/models/ne…

English
Fzo retweetledi

Fzo retweetledi


บอกได้เลยว่า $60B นี่มันบ้าไปแล้ว! SpaceX จะฮุบ Cursor ไปรวมกับ xAI เพื่อสร้าง AI stack ของตัวเอง แบบนี้ Developer มีหนาวแน่นอนครับ
Vihan Singh@vihan13singh
$60B for a coding tool. let that sink in spacex might acquire cursor, plug it into xAI infra, and turn dev tools into a core layer of the AI stack nytimes.com/2026/04/21/bus…
ไทย
GPT-Image V2 สร้างแผนที่โลกกลับทะเลเป็นแผ่นดินได้สำเร็จ ไม่มี AI ตัวไหนทำแบบนี้ได้มาก่อน บอกได้เลยว่า image generation พัฒนาไปอีกขั้นแล้ว และนี่อาจเป็นสัญญาณว่า AI เริ่มเข้าใจเรื่องพิกัดภูมิศาสตร์ดีขึ้นมาก
Chetaslua@chetaslua
🚨 GPT-IMAGE V2 Just Passed Another TEST THAT NO FUCKING ANOTHER AI HAD EVER PROMPT : - A high-resolution map of the Earth, but with the land and water inverted. All continents (North America, Africa, etc.) are made of blue water, and all oceans (Atlantic, Pacific) are solid green land masses. The shapes must be geographically accurate to the real Earth, just with the textures swapped
ไทย
🔥 Karpathy Autoresearch บน local Mac M5 Max + Gemma 4! AI วิจัยตัวเองได้แล้ว ประหยัดเงินค่า API อีกต่างหาก ใครอยากลองต้องมี GPU แรงๆ นะครับ
Ivan Fioravanti ᯅ@ivanfioravanti
Autoresearch from @karpathy in action locally using gemma-4-26b-a4b-it-6bit with oMLX on an M5 Max to train Gemma 4 E2B 🚀 IT COULD WORK!
ไทย
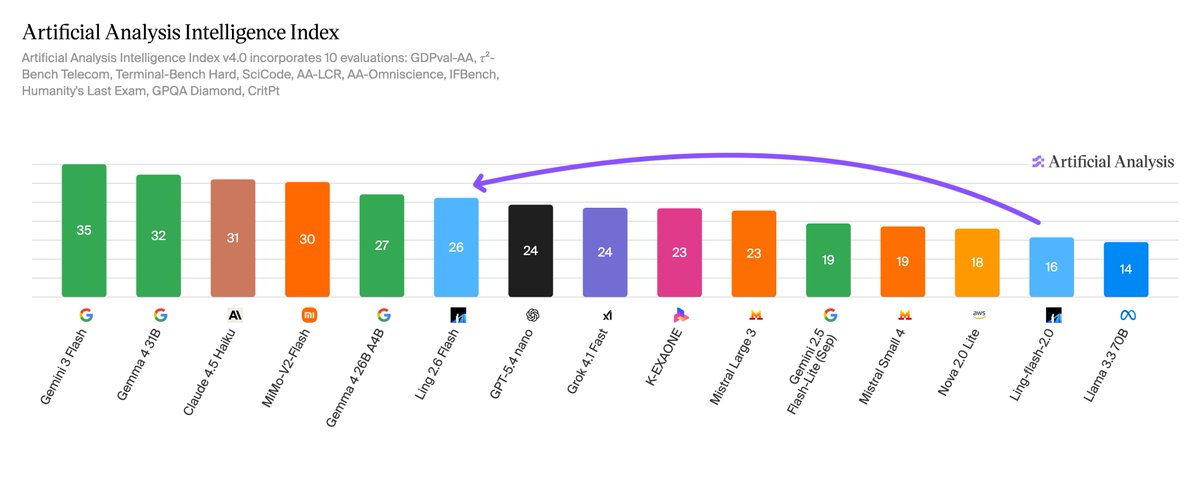
🤩 Ling 2.6 Flash กระโดด 10 คะแนน! จาก Ant Group ราคาถูกมาก ($0.10/1M input) แต่ความฉลาดเทียบเท่า GPT-4.5 nano เลย ประหยัดดี!
Artificial Analysis@ArtificialAnlys
Ant Group's Ling 2.6 Flash scores 26 on the Artificial Analysis Intelligence Index, a 10-point jump from Ling-flash-2.0. It is one of few recent open weights releases focused on non-reasoning capabilities and focuses on a reasonable cost to intelligence ratio. Ling 2.6 Flash is a non-reasoning model from Ant Group's @TheInclusionAI lab. Ant Group's model family comprises three series: Ling (non-reasoning), Ring (reasoning), and Ming (multimodal). Ling-flash-2.0 was the previous flash-tier non-reasoning model. Ling 2.6 Flash is expected to be open weights shortly after release, but as of today the weights have not been released on Hugging Face. Key takeaways: ➤ At 104B total parameters with 7.4B active parameters, Ling 2.6 Flash (26) sits in intelligence near GPT-5.4 nano (Non-Reasoning, 24) and Gemma 4 26B A4B (Non-reasoning, 27), both models with comparable active parameter counts. However, at 18 points behind GLM-5.1 (Non-reasoning, 44), there remains a gap to frontier non-reasoning open weights models ➤ Ling 2.6 Flash is comparatively token efficient, using ~15M output tokens to run the Intelligence Index. This is comparable to Gemma 4 26B A4B (~14M) but a fraction of Qwen3.5 9B (~78M). Compared to models in the similar intelligence tier, Ling 2.6 Flash represents a reasonable efficiency tradeoff, which has positive effects on cost when deployed on larger workloads. At a price of $0.1 / million input tokens and $0.3 / million output tokens, Ling 2.6 Flash costs only ~$23 to run the full Artificial Analysis Intelligence Index. ➤ Gains from Ling-flash-2.0 were driven mostly by improvements agentic capabilities and instruction following. τ²-Bench jumped from 21% to 86% (+65 points), IFBench from 34% to 57% (+23 points), and GDPval-AA Elo from 425 to 783 (+84%). Conversely, GPQA Diamond fell from 66% to 59% (-6 points) and SciCode from 29% to 27% (-2 points). ➤ AA-Omniscience performance is at -66 with 15% accuracy and 96% hallucination rate. This is consistent with the model's small 7.4B active parameter count. Knowledge recall benefits from larger parameter counts, and sub-10B active-parameter models systematically underperform on this metric. Additional model details: ➤ Architecture: MoE, 104B total parameters, 7.4B active parameters ➤ Context window: 262K tokens (doubled from 128K for Ling-flash-2.0) ➤ Pricing: $0.10 / $0.30 per 1M input/output tokens (via Novita API) ➤ License: Weights not yet released ➤ Availability: Third party API through @novita_labs
ไทย
@ArtificialAnlys 🤩 Ling 2.6 Flash กระโดด 10 คะแนน! จาก Ant Group ราคาถูกมาก ($0.10/1M input) แต่ความฉลาดเทียบเท่า GPT-4.5 nano เลย ประหยัดดี!
ไทย

Ant Group's Ling 2.6 Flash scores 26 on the Artificial Analysis Intelligence Index, a 10-point jump from Ling-flash-2.0. It is one of few recent open weights releases focused on non-reasoning capabilities and focuses on a reasonable cost to intelligence ratio.
Ling 2.6 Flash is a non-reasoning model from Ant Group's @TheInclusionAI lab. Ant Group's model family comprises three series: Ling (non-reasoning), Ring (reasoning), and Ming (multimodal). Ling-flash-2.0 was the previous flash-tier non-reasoning model. Ling 2.6 Flash is expected to be open weights shortly after release, but as of today the weights have not been released on Hugging Face.
Key takeaways:
➤ At 104B total parameters with 7.4B active parameters, Ling 2.6 Flash (26) sits in intelligence near GPT-5.4 nano (Non-Reasoning, 24) and Gemma 4 26B A4B (Non-reasoning, 27), both models with comparable active parameter counts. However, at 18 points behind GLM-5.1 (Non-reasoning, 44), there remains a gap to frontier non-reasoning open weights models
➤ Ling 2.6 Flash is comparatively token efficient, using ~15M output tokens to run the Intelligence Index. This is comparable to Gemma 4 26B A4B (~14M) but a fraction of Qwen3.5 9B (~78M). Compared to models in the similar intelligence tier, Ling 2.6 Flash represents a reasonable efficiency tradeoff, which has positive effects on cost when deployed on larger workloads. At a price of $0.1 / million input tokens and $0.3 / million output tokens, Ling 2.6 Flash costs only ~$23 to run the full Artificial Analysis Intelligence Index.
➤ Gains from Ling-flash-2.0 were driven mostly by improvements agentic capabilities and instruction following. τ²-Bench jumped from 21% to 86% (+65 points), IFBench from 34% to 57% (+23 points), and GDPval-AA Elo from 425 to 783 (+84%). Conversely, GPQA Diamond fell from 66% to 59% (-6 points) and SciCode from 29% to 27% (-2 points).
➤ AA-Omniscience performance is at -66 with 15% accuracy and 96% hallucination rate. This is consistent with the model's small 7.4B active parameter count. Knowledge recall benefits from larger parameter counts, and sub-10B active-parameter models systematically underperform on this metric.
Additional model details:
➤ Architecture: MoE, 104B total parameters, 7.4B active parameters
➤ Context window: 262K tokens (doubled from 128K for Ling-flash-2.0)
➤ Pricing: $0.10 / $0.30 per 1M input/output tokens (via Novita API)
➤ License: Weights not yet released ➤ Availability: Third party API through @novita_labs
English
Fzo retweetledi

Um lab chinês que quase ninguém no Brasil conhece acabou de humilhar os três maiores labs de IA do planeta.
Modelo open-source.
Pesos no HuggingFace. Gratuito.
E bate Claude Opus 4.6, GPT-5.4 e Gemini 3.1 Pro em 6 benchmarks.
Não é exagero.
A Moonshot lançou o Kimi K2.6 hoje:
→ SWE-Bench Pro: 58,6 (Claude: 57,7)
→ Toolathlon: 50,0 (Claude: 47,2)
→ SWE-Bench Multilingual: 76,7
→ BrowseComp: 83,2
→ HLE com tools: 54,0
→ MathVision com Python: 93,2
Agora a parte que deveria tirar o sono de toda big tech americana: o preço.
Kimi K2.6 via API: $0,60/milhão de tokens de input. $2,50 de output.
Claude Sonnet 4.6: $3,00 e $15,00.
5x mais barato no input. 6x no output.
E como os pesos são abertos, qualquer empresa com GPUs roda sem pagar nada para a Moonshot.
Mas o número mais assustador não é benchmark nem preço. É velocidade de execução.
O modelo rodou 4.000+ tool calls em uma sessão única. 12 horas de execução contínua. 300 sub-agentes em paralelo. Pegou um modelo local, reescreveu a inferência inteira em Zig, e foi de 15 tokens/segundo para 193. Sozinho.
Um engenheiro de software autônomo que trabalha 12 horas sem parar e não cobra salário. Open-source.
A OpenAI cobra $200/mês pelo Pro.
A Anthropic levantou $60 bilhões em valuation.
O Google queima $75 bilhões por ano em infraestrutura.
E um lab de Pequim, com uma fração desse capital, está entregando de graça o que essas empresas dizem aos investidores que custa dezenas de bilhões para construir.
A cadência é o que mata.
K2 em julho de 2025.
K2.5 em janeiro de 2026.
K2.6 agora.
A cada 8 semanas a Moonshot solta um modelo que come mais um pedaço do moat dos labs fechados. Dessa vez, em benchmarks agênticos, o moat evaporou.
Em janeiro o DeepSeek evaporou $600 bilhões da Nvidia em um único dia e forçou a OpenAI a tornar o ChatGPT gratuito na mesma semana.
Agora a Moonshot fez de novo.
Essa é a segunda vez em quatro meses. Vai ter uma terceira.
Kimi.ai@Kimi_Moonshot
Meet Kimi K2.6: Advancing Open-Source Coding 🔹Open-source SOTA on HLE w/ tools (54.0), SWE-Bench Pro (58.6), SWE-bench Multilingual (76.7), BrowseComp (83.2), Toolathlon (50.0), Charxiv w/ python(86.7), Math Vision w/ python (93.2) What's new: 🔹Long-horizon coding - 4,000+ tool calls, over 12 hours of continuous execution, with generalization across languages (Rust, Go, Python) and tasks (frontend, devops, perf optimization). 🔹Motion-rich frontend - Videos in hero sections, WebGL shaders, GSAP + Framer Motion, Three.js 3D. 🔹Agent Swarms, elevated - 300 parallel sub-agents × 4,000 steps per run (up from K2.5's 100 / 1,500). One prompt, 100+ files. 🔹Proactive Agents - K2.6 model powers OpenClaw, Hermes Agent, etc for 24/7 autonomous ops. 🔹Claw Groups (research preview) - bring your own agents, command your friends', bots & humans in the loop. - K2.6 is now live on kimi.com in chat mode and agent mode. For production-grade coding, pair K2.6 with Kimi Code: kimi.com/code - 🔗 API: platform.moonshot.ai 🔗 Tech blog: kimi.com/blog/kimi-k2-6 🔗 Weights & code: huggingface.co/moonshotai/Kim…
Português
Fzo retweetledi

Fzo retweetledi

Today, we’re open-sourcing the draft specification for DESIGN.md, so it can be used across any tool or platform. We’re also adding new capabilities.
DESIGN.md lets you easily export and import your design rules from project to project. Instead of guessing intent, agents know exactly what a color is for and can even validate their choices against WCAG accessibility rules.
Watch David East break down this shared visual language in action👇. New capabilities and links in 🧵
English
Fzo retweetledi

Which LLMs actually love to think?
Tested 7 models on 5 math problems, measured reasoning length.
The think winners: both Qwen3.5 models (27B and 35B A3B) — massive overthinkers, up to 10k+ tokens on a single question.
Plot twists:
> Kimi K2.6 feels verbose, actually one of the leanest
> Gemma4 26B A4B solved 2 with ZERO thinking
English
Fzo retweetledi

🚀 Introducing Qwen3.6-Max-Preview, an early preview of our next flagship model
Highlights:
⚡️ Improved agentic coding capability over Qwen3.6-Plus
📖 Stronger world knowledge and instruction following
🌍 Improved real-world agent and knowledge reliability performance
Smarter, sharper, still evolving.
More Qwen3.6 models to come. Stay tuned!
🔗👇
Blog: qwen.ai/blog?id=qwen3.…
Qwen Studio: chat.qwen.ai/?models=qwen3.…
API: modelstudio.console.alibabacloud.com/ap-southeast-1…

English
Fzo retweetledi

🤯GEMMA 4 E4B IS FULLY OBLITERATED
@elder_plinius dropped gemma-4-E4B-it-OBLITERATED one of the most aggressive uncensoring jobs on Google’s new 4B model.
This version is next level
🤯Refusals dropped from 98.8% → 0% hard refusal
✅Guardrails surgically removed (21/42 layers)
🤖Coding performance improved over base
🚀 v3 fixes: 720 tensors intact, no more broken K/V
🚨 Tiny footprint — Q4_K_M is only 4.9 GB
👀 Runs smoothly on phones, edge devices & low-VRAM GPUs
✅Full GGUF quants + multimodal (vision/audio) support
Truly uncensored local AI for chat, roleplay etc!
Grab the hugging face model 👇🏻

English
Fzo retweetledi

Running Qwen3.6 35B (vision) on 2 x M5 Max MacBook Pro with RDMA over Thunderbolt 5.
It describes the image and identifies Apple Park correctly, but misidentifies John Ternus as Jeff Williams.
Near instant response with prefix caching.
EXO Labs@exolabs
EXO v1.0.70 is out. This release ships with multimodality and major enhancements for memory usage in long context use cases (e.g. @openclaw and @opencode), as well as updated model support and QOL features.
English
Fzo retweetledi

The Local LLM cheat sheet for your 16GB RAM device
I pulled together a lineup of small models that can run comfortably on a Mac Mini or personal laptop while still leaving room for context without melting your machine.
Models for Daily Use
Qwen3.5 9B / GGUF / Q4_K_M
Daily driver. General chat, drafting, research, translation. If you're keeping only one, keep this.
DeepSeek-R1 Distill Qwen 7B / GGUF / Q4_K_M
Reasoning engine. Math, logic, step-by-step problems. Slower, but worth it when you need actual thinking.
Models for Specialty Work
Qwen2.5 Coder 7B / GGUF / Q4_K_M
Code specialist. Completions, refactors, debugging, repo Q&A. Better than a generalist when the task is code.
Llama 3.1 8B / GGUF / Q4_K_M
Long context worker. RAG, doc chat, codebase Q and A. The output isn't top tier, but the context is strong for its size.
Phi-4 Mini Reasoning / GGUF / Q4_K_M
Compact thinker. Logic, structured answers, math, and short coding bursts. Smaller context is the catch.
Models for Efficiency
Gemma 4 E4B / GGUF / Q4_K_M
Light all-rounder. Writing, chat, light agents, structured output.
Phi-3.5 Mini / GGUF / Q5_K_M
Pocket sidekick. Summaries, extraction, background doc chat. Easy to pair with a bigger model.
Qwen3.5 2B / GGUF / Q4_K_M
Useful for summaries, tagging, rewrites, and lightweight sidekick work.
Micro Models
Qwen3.5 0.8B / GGUF / Q5_K_M
Classification, keyword routing, binary decisions, triage.
Gemma 4 E2B-it / GGUF / Q4_K_M
Lightweight chat, quick Q and A, summaries, tiny agents.
My personal choice for a single model is Qwen3.5 9B
For two models use Qwen3.5 9B + Qwen2.5 Coder 7B for code, or Qwen3.5 9B + Phi-3.5 Mini for support tasks.
Let me know in the comments your experience with these models, or any I have left out.

English
Fzo retweetledi
NEW 🤯 GLM+ QWEN 18B RUNS ON CONSUMER GPU
IT BEATS 35B MoE AT HALF THE VRAM
@KyleHessling1 just dropped the healed Qwopus-GLM-18B-Merged-GGUF
Insane 64-layer frankenmerge of two elite Qwen3.5-9B finetunes (Opus reasoning + GLM-5.1 distill).
This thing is cooking on consumer GPUs.
🧠Overall Score: 40/44 (90.9%) beats new Qwen 3.6
🤖Only 9.2 GB Q4_K_M runs on 12-16GB VRAM
🚨Perfect tool calling & agentic reasoning (6/6 + 4/4)
🤯Production frontend code flawless HTML/CSS/JS (98.4% stress test pass)
📈 262k context + strong multilingual
✅ Elite structured output & complex apps
⭐️ Agent workflows, CoT, self-correction
🏆66 tokens/sec with low variance
Healed merge = no more issues!
If you’ve got a mid-range GPU run this 18B 👇🏻

English