Luke ⟠ ⟠ ⟠ 🌾🌞⚔️ retweetledi

Luke ⟠ ⟠ ⟠ 🌾🌞⚔️
4.1K posts


@GatheringGwei
⟠ @dphnAI ⟠


Node provider rollout has been going well Our pool of inference nodes running Qwen 3.6 35B have generated over 3.2B tokens so far Total inference bandwidth -> 9400 t/s 28x RTX 4090 12x RTX 5090 8x RTX PRO 6000 & many other cards API access coming soon 🐬

谢谢官方@dphnAI !!! 5天给了7220个 $pod 目前价值250u 之前币价拉到0.045。希望继续 🙏

Dolphin AI is on a generational run right now People are finally catching up to the inference thesis (Congrats to all the Substack subscribers who got in)
谢谢官方@dphnAI !!! 5天给了7220个 $pod 目前价值250u 之前币价拉到0.045。希望继续 🙏
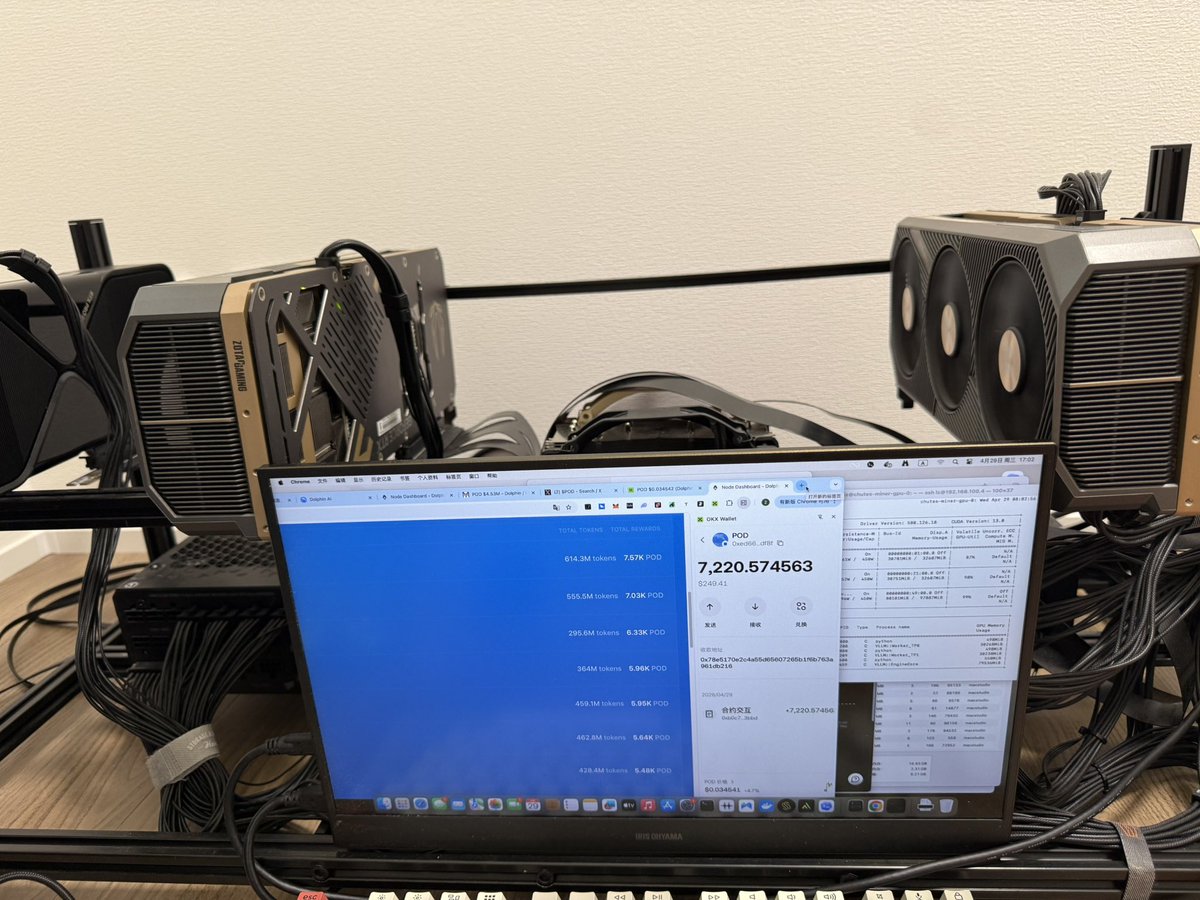
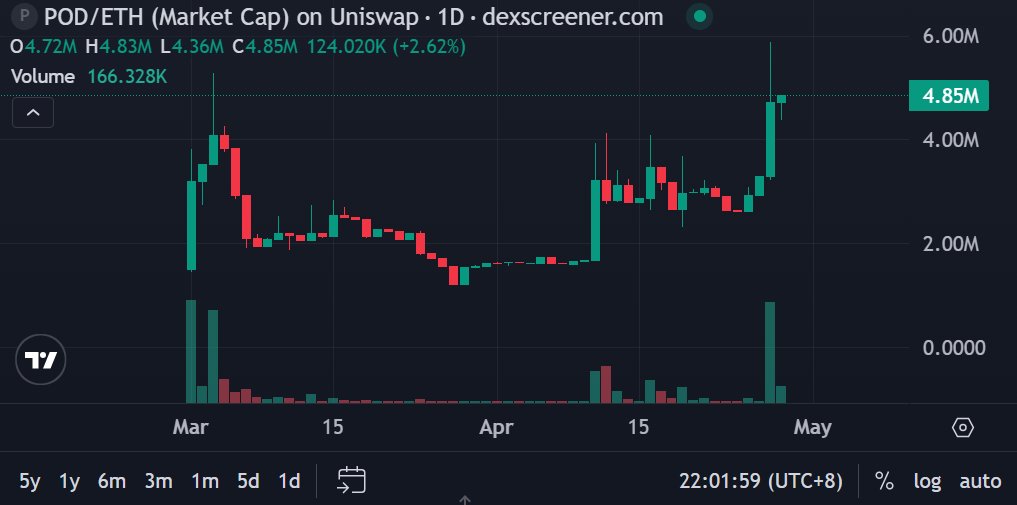
排行榜终于变成第一了☝️ 3天挖了6430个。 按照今天币价 $pod 0.0366,一个月2000u?收益还算可以。 @dphnAI
Node provider rollout has been going well Our pool of inference nodes running Qwen 3.6 35B have generated over 3.2B tokens so far Total inference bandwidth -> 9400 t/s 28x RTX 4090 12x RTX 5090 8x RTX PRO 6000 & many other cards API access coming soon 🐬


Dolphin 网络节点教程 dphn.ai/docs/running-a…


Dolphin Inference Network node operation is now live for anyone who would like to beta test before we go into production $POD rewards live for testers Repurposing idle GPUs to run Qwen 3.5 35B MoE

部署上10分钟挖了一个 $pod ,好像产出还可以吧。 支持偶数或单卡60g以上显存。
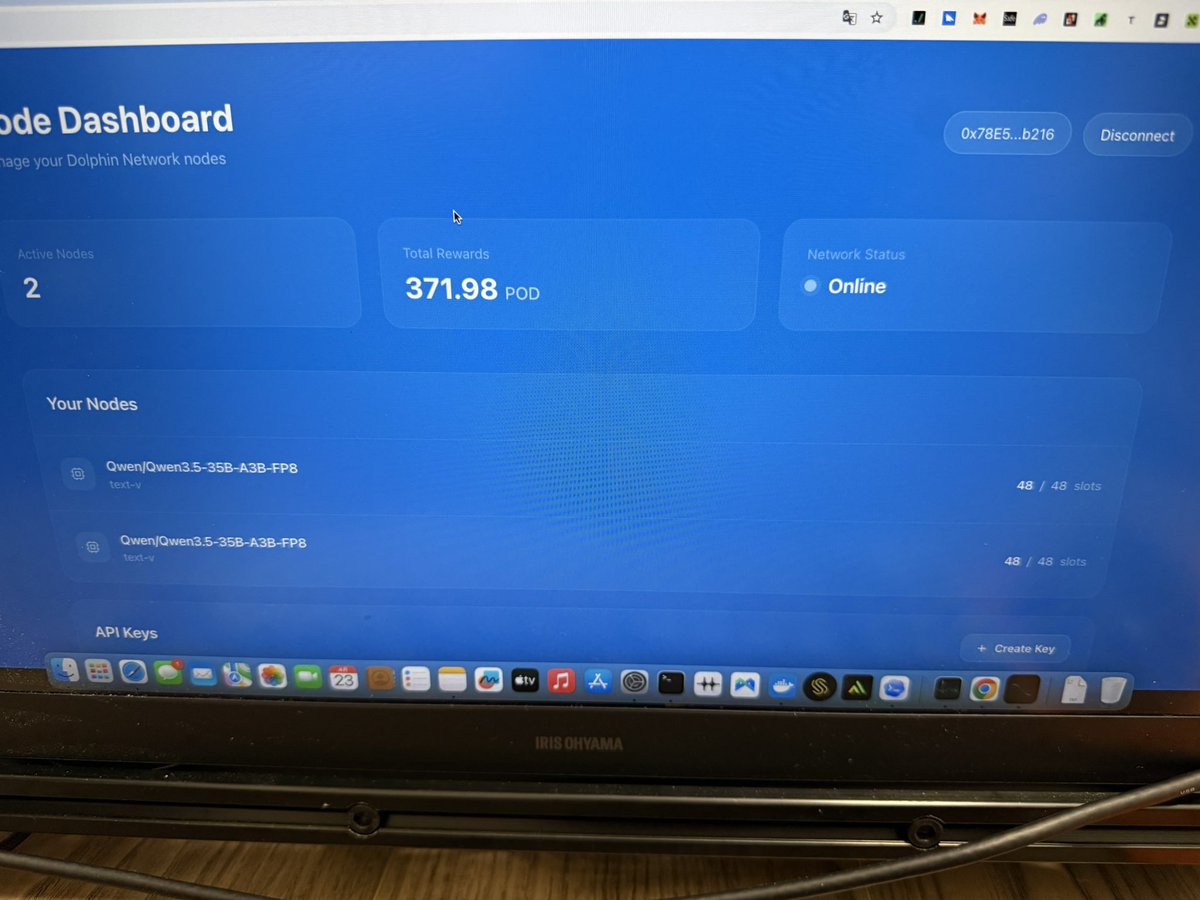
部署上10分钟挖了一个 $pod ,好像产出还可以吧。 支持偶数或单卡60g以上显存。

Dolphin 网络节点教程 dphn.ai/docs/running-a…

Venice Uncensored 1.2 is live The model has been upgraded with vision support, a 4× larger context window & stronger tool-use capabilities Developed in collaboration with @AskVenice to deliver the most uncensored version of Mistral 3.2 24B Trained on Subnet 4 @TargonCompute

Venice Uncensored 1.2 is now live. Developed with @dphnAI, this model delivers the most uncensored version of Mistral 24B. Upgraded with vision support, a 4x larger context window, and stronger tool-use capabilities. Trained on Bittensor Subnet 4 @TargonCompute.




