Sabitlenmiş Tweet
Gavin Ray
2.3K posts


Gavin Ray
@GavinRayDev
Work @PromptQL (@HasuraHQ) OSS Contributor. I have a Postgres tattoo 🐘🎨 🔬🧪🧬Passion for Molecular Bio, Health, Fitness, Longevity 💪Aspiring Bodybuilder
Seattle, WA Katılım Haziran 2018
555 Takip Edilen1.4K Takipçiler

Gavin Ray retweetledi

OpenAI just killed us.
One problem, they didn't actually solve the biggest problem of AI at work: Context
Let me prove it to you...
Here's a wild example of ChatGPT Work going head-to-head with PromptQL:


OpenAI@OpenAI
Introducing ChatGPT Work, a new agent in ChatGPT powered by Codex and GPT-5.6. It can take action across your apps and files, stay with a project for hours if needed, and turn a goal into finished work. It’s a whole new way to get work done.
English
@peptidepirate Incredible transformation -- hell yeah!
What was the timeline and weight difference between the two if you don't mind me asking?
And I'm assuming TRT + GLP-1, and maybe GH or GH-related peps like Tesa/Ipam?
English

I have been very impressed with this cut and what these peptides have allowed me to do and the ease of doing it 🏴☠️
I found that strategically adding certain peptides into diffrent phases of the cut allowed me to really get to where I wanted to be 🏴☠️
Obviously the GLPs did most of the heavy lifting but there are a select few other tools for fat loss in the peptide space 🏴☠️
Once you do this one time and see how easy it is there is no way to revert back to old the old way of cutting 🏴☠️
However even with the help of peptides you still must show up and put the work in regardless🏴☠️
Without the work and discipline you are just wasting money🏴☠️

English
Gavin Ray retweetledi

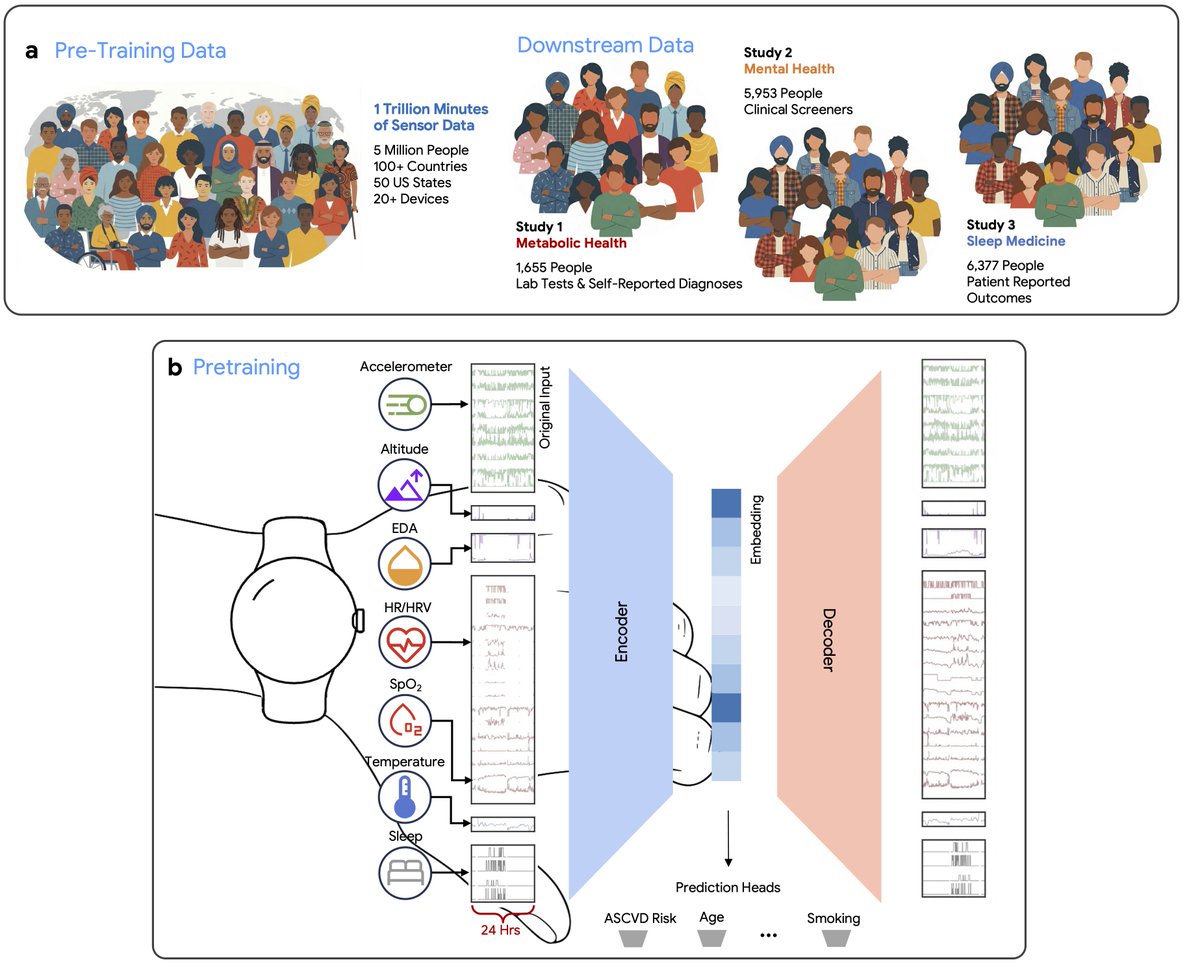
Introducing SensorFM, a large-scale Sensor Foundation Model that learns from 1 trillion-minutes of unlabeled wearable data drawn from five million consented participants.
SensorFM learns a single, reusable representation of sensed human physiology that transfers across cardiovascular, metabolic, sleep, and mental health, as well as lifestyle and demographic factors.
More →goo.gle/4ycJvot
English
Gavin Ray retweetledi
Holy f***king shit. Grok 4.5 is a monster.
On our internal evals on maintaining a company wiki: Grok 4.5 is fable-level on reasoning and a little lower than opus 4.8 on rigor.
@elonmusk and @cursor_ai have just been COOKING.
Just added Grok-4.5 on PromptQL for everyone.

Tanmai Gopal@tanmaigo
We raised $136M to kill Slack. Introducing PromptQL: The first AI version of Slack. Here’s how it works:
English
When I started at Hasura 6 years ago, it was :
"API's on top of your data"
LLM's and agents became all the rage, and we realized:
"Hey, we have great tool for understanding org-wide data + API's"
"What if we could use this as context for LLM's, and start to build a living knowledge base?"
That idea turned Hasura -> PromptQL, and I'm so proud to share our work and the small part I've played in it
Tanmai Gopal@tanmaigo
Anthropic banned our company in March, and gave us an Al bot for support. We were a $40k/mo customer. Lesson learnt: Never let one lab own your Al. Today we're launching PromptQL Tag: Claude Tag on AGI steroids. Here are 8 things it does that Claude Tag will never do:
English
Because the Olympians are the rare 0.00001%
Perfect genes for both size response + gear tolerance
Mentality of robotic execution and consistency for years
Training routine is such a small knob on the pyramid of
Genetics > Diet > Anabolics > Routine
Almost anything works for size, if you stay in a caloric surplus and train close to failure consistently.
English

A thought about the hard core science based approach to hypertrophy.
I don’t think there’s ever been one of those guys to ever grace the top ten on the Olympia stage.
It’s all the “bro” science guys up there.
Why do you think that is?
English
@CoffeeBlackMD N=1, wife has used 25mg Oxandrolone daily for 8 years
ALT/AST + GGT perfectly normal (20, 31, 11)
HDL and LDL mildly out of range (43, 122)
English

The pattern I see on labs with guys using oxandrolone 4-5x per week on training days isn’t ugly. No liver issues. Barely any violence on the lipids.
I DO use troches instead of capsules with my guys (and a couple gals) and everyone does need to have good looking labs before starting. So maybe there is something there.
But I’m beginning to think the toxicity of oxandrolone to be highly overstated.
I’m sure if you believe in yourself and try really, really hard you can still harm your liver with dosing or other silly behavior like drinking.
English
@BenBikmanPhD I think it's important to note a nuance here though
Beta cells releasing (endogenous) insulin due to de-sensitization is one thing
If you introduce (exogenous) insulin, insulin sensitivity is preserved via reducing the burden of natural production
English

One of the key drivers of insulin resistance is too much insulin. This is an example of a biological principle known as "homologous downregulation". The principle applies to peptide hormones generally--to much of a peptide hormone leads to a resistance to that hormone.
This universal biological principle is one reason I am concerned with the escalating doses of GLP-1 drugs. GLP-1 is a peptide hormone. The more the pathway is activated, the more the pathway becomes resistant. To help preserve sensitivity, the lowest effective dose is ideal.
How can you know the lowest effective dose? The dose that helps you control cravings.
English
Gavin Ray retweetledi

We launched a new website to a) Provide information about supplements b) find out what people are using and c) share their experiences. Check it out: mysupplehub.org/#/
English
@Mangan150 This is misleading -- ferritin is an acute-phase reactant
During injury/systemic inflammation, ferritin rises disproportionately to the rest of your iron markers (Transferrin, TIBC, etc)
I say this as someone with iron-deficiency anemia but high ferritin

English

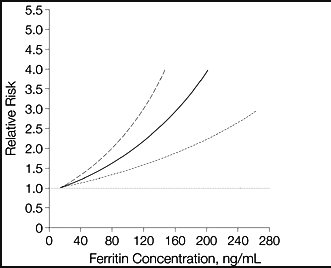
Risk of diabetes by ferritin level, which is a measure of body iron stores.
Lots - and lots, probably the majority of adults, especially men - have ferritin >100.
Diabetes, bad enough itself, is perhaps the biggest aging accelerator.
Iron is an underrated factor in aging.
English
@drmikehart Retatrutide in particular raises BMR/TDEE via glucagon if you want to "uhm ackshually" about it 😅
But for sure, vast majority of weight loss is reduced intake, not increased expenditure (Reta included)
English

People eat less.
less eating = fewer calories
fewer calories = caloric deficit (more likely)
caloric deficit = weight loss
gary taubes@garytaubes
How do GLP-1 drugs cause weight loss? If they work by suppressing appetite or increasing satiety (which I don't buy), the notion that they accomplish that by delaying gastric emptying doesn’t stand up to scrutiny. At least not in the first actual test of the assumption. doi.org/10.1002/oby.70…
English
I kept reading the "Nandrolone aromatizes into E2" thing online over the years
Recently decided to get bloods after 8 weeks on 1,200mg Nandrolone/wk, without Testosterone
In humans, it would appear it does not metabolize
(These are the same as T + E2 I get w/o TRT)
Huge bummer because Nand is such a mild androgen in comparison to Testosterone.
I've had good luck taking 7a-Methyl-Nandrolone (MENT) without any T though -- the 7a-Me-E2 metabolite is equi-potent to E2 w/ near identical binding affinity for ERa/ERb
MENT is my favorite androgen by a mile

English
Nandrolone is a fussy anabolic. The more estrogen you have running around the more issues you’ll have with nandrolone’s progestin effects, even if symptoms from an estrogen perspective are baseline. Though. With that said nandrolone metabolizes into an estrogen at about 10% the rate of testosterone. So. Sometimes for older guys the better part of valor is taking away like 40mg testosterone and adding in 40mg of nandrolone. But in general 40mg of nandrolone is well tolerated and can be stacked in not a stable TRT dose for added joint and muscle building support. 200mg per week for (the vast majority) 70 year olds is going to be a BAD idea. So it’s not a hard no. But there are … variables at play.
English
I know medicine has concerns over the safety profile of anabolic compounds.
But medicine also has concerns about frailty, sarcopenia, falls, metabolic dysfunction, and diabetes (with all of the downstream problems of hypertension, lipid issue, and CVD).
We largely avoid directly intervening until disease hits. Which I do understand based on our training but also the standard of care guidelines driven management. When you show up with a diagnosis, it’s now easily actionable.
It’s not like we don’t preach lifestyle: sleep, food, training. But the vast majority of you are NOT happy if you see the doctor and she tells you to sleep better, don’t eat like crap, and exercise and she’ll see you back in 6 months. You’d complain. There is a damned if you do and damned if you don’t.
But where I think I see medicine (some) of it going is to heading off chronic disease at the pass, preventing or delaying it.
Which brings me back to anabolics. A hugely valuable tool if you’re trying to get people stronger and more metabolically healthy.
The easiest to use and dose is testosterone. Not only does it feed the training but it very literally makes you want to train (do hard things). More muscle provides strength going into old age to prevent things like falls. More muscle gives your body something to do with its insulin and nutrients that is different than “store as fat”. Which means improved insulin resistance and obesity. Which will further mean, less downstream diabetes and complications.
Other anabolics need some thought but none are “dangerous” per se. These aren’t snakes. Horror stories about them in the medical literature are outlier cases. And this has in part driven the moral panic about anabolics.
I don’t really care that much about anything that relates to pure aesthetics especially when we have zero issues (usually) with permanent changes to someone from cosmetic surgery.
In the end you can out on muscle for both health and aesthetic reasons safely and I think medicine should be leading the way here not resisting and suspicious.
English
I keep reading discussions online where people talking about GLP-1's as if they're "1 vs 2 vs 3 Receptors"
This is not how these work. 10mg Reta != 10mg Tirz
You have to use EC50 data to look at receptor affinity
Below is Gemini infographic using Coskun et al. 2022 data [0]
[0]: LY3437943, a novel triple glucagon, GIP, and GLP-1 receptor agonist for glycemic control and weight loss: From discovery to clinical proof of concept: Cell Metabolism (cell.com/cell-metabolis…)

English
@_9th_Life_ My mid-50s family member texted me last month asking "if I ever heard of peptides?" 💀
English

Currently at a family gathering and pretty much everyone has asked me about GLP1s/Reta.
My aunt just said she’s on reta and that she heard about it on tiktok and bought it from “some website” online.
My sister and cousin told me they want to “get on it,” my aunt asked me about the GLOW blend, my brother and all his friends are talking about melonatan.
Obviously I have a bias here, but I think this market is about to erupt. Peptides feel so big here in the X echo chamber, but they are just now scratching the surface in the mainstream.
I’d imagine these conversations are happening a lot today with friends and family.
This + the FDA meeting later this month. We are on the verge of an inflection point.
English
Gavin Ray retweetledi

introducing egaki
a framework to make videos with mdx. for agents & humans
the video below was entirely written by Fable 5. I didn't touch a video editor or code once
English
@john_galt_42069 I'm not a big gun guy (in videogames they're fun) but I hope that you pull it off!
Nothing is more satisfying than getting to build a thing you are passionate about and see it prosper =)
(Bullpups are very neat from an engineering perspective, clever idea)
English

>be 19yo uni student
>get into guns, think of design fix problems with current designs
>shelve drawings because broke and scammed by uni tuition
>graduate early, spend several years as code monkey
>late 20s, jeets and MBAs destroy SWE job market
>pull out drawings from a decade ago, start making 3d models out of drawings
>design new bullpup rifle from scratch in 3 months
>design barely works, since no exp or creds in MechE
>keep fixing issues and burning through savings
>start YT to document build process, terrible prod quality, barely get any views/subs
>finally get it working, parts keep breaking
>both patents granted b4 30th birthday
>make DFM, weight, cost optimizations, reduce parts count, fix breakages, continue testing
>start open sourcing parts of rifle
>still suck at marketing/social media
>looking for MFG to license
English
@agingroy I think the methodology could have been better designed
"strength" test -> handgrip force
"power" test -> rowing exercise
E.G. "people who could row more explosively had better survival than those with firm handshakes"
"row speed" vs "row weight" would have been more genuine
English

Sources and notes: Araújo CGS, Kunutsor SK, Eijsvogels TMH, et al. “Muscle Power Versus Strength as a Predictor of Mortality in Middle-Aged and Older Men and Women.” Mayo Clin Proc. 2025;100(8):1319-1331. Read it: pubmed.ncbi.nlm.nih.gov/40304660/
-> CLINIMEX prospective cohort, 3,889 adults (2,636 men, 1,253 women), ages 46 to 75, enrolled 2001 to 2022, median follow-up 10.8 years (IQR 6.7 to 15.5). Deaths: 14.2% of men, 8.9% of women.
-> Both tests were upper body, done the same visit: power by an upper-row movement test, strength by handgrip, each adjusted for body weight. This isolates power vs strength as constructs, not different limbs.
-> Multivariable Cox hazard ratios, lowest vs highest muscle POWER: men HR 5.88 (95% CI 2.28 to 15.17, P<.001), women HR 6.90 (95% CI 1.61 to 29.58, P=.009). The wide female CI reflects only a handful of deaths in the top-power group.
-> Same people re-sorted by STRENGTH: men HR 1.62 (95% CI 0.89 to 2.96, P=.11), women HR 1.71 (95% CI 0.61 to 4.80, P=.31). Both confidence intervals cross 1.0, so the strength gap was not statistically significant.
-> Caveat: observational, so low power partly flags people who are already frail rather than proving that training power lowers death. The authors also had no lean-mass data and couldn’t fully adjust for fitness. But power is trainable, and the downside of adding fast, explosive movement to a program is near zero.
English
How fast you can move a weight predicts death better than how much you can lift.
A Rio clinic followed 3,889 adults ages 46 to 75 for a median of about 11 years. They measured two different things: strength, which is raw force, and power, which is force times speed. Same upper body, same afternoon, two tests.
Power separated survivors clearly. The least powerful men died at nearly six times the rate of the most powerful; in women, it was closer to seven. When the same people were re-sorted by raw strength, the gap shrank to about 1.6x and disappeared into the noise, a difference the study couldn’t call real.
Aging strips fast muscle fibers first, so speed fades before strength. That’s why it warns you earlier.
So if you want to live longer, train speed, not just load.

English
Gavin Ray retweetledi

Docker Compose has finally shipped native support for init containers, e.g. running DB migrations or similar one-off tasks.
Somewhat similar to k8s, they’re ephemeral containers that must exit successfully before the service containers start. They’re defined as pre_start hooks in the Compose file.
I shipped something very similar a few months ago for Uncloud designed as pre_deploy hooks.
There is no fundamental difference, only a few parameters differ. But Uncloud is a multi-host orchestrator where "deploy" is a distinct first-class operation so I believe the pre_deploy naming more clearly describes the intent to run something before the service rollout kicks in.
We may still adopt the new pre_start spec eventually, for example, to specify a container-lifecycle hook that runs before starting every service replica, not only once per service deploy.

English