Open-source tournaments keep on delivering...
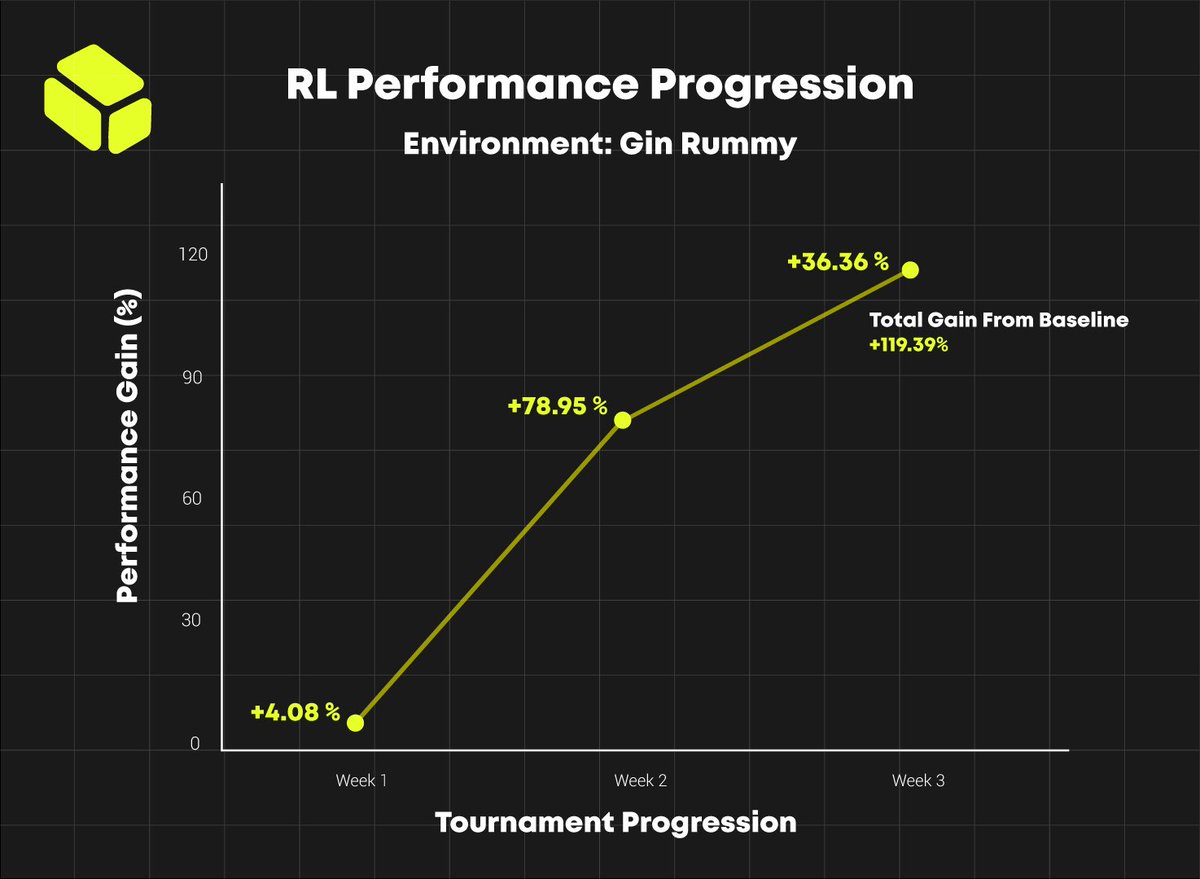
The miners are improving nicely on the new RL environment training tasks. The Gin Rummy environment from the Affinetes GAME was especially fruitful, as seen below.
After Goospiel, Alfworld, and Gin Rummy we are expanding to other environments from Affinetes until we get the best scripts to train on all of them
English