
Grand Beggar
17.9K posts
Grand Beggar
@GrandBeggar
Think for yourself, but of others. Don't believe everything you think, but trust in yourself. Being wrong is not losing. Learn from it.
Canada Katılım Ağustos 2020
221 Takip Edilen160 Takipçiler


The look:
Semi-closeted homosexual man who supports and enables an organization that operates like a fascist state.
7/11 Truther@DaveMcNamee3000
John Travolta is experimenting with an incredibly powerful look. I will be monitoring this situation
English
Grand Beggar retweetledi

This is a good thread. #hantavirus
Prof Peter Hotez MD PhD DSc(hon)@PeterHotez
1/n: I could be wrong, of course, but my take about this hantavirus outbreak is less about the actual outbreak and more about what it means in the context of the last two decades and moving forward. Let me explain...
English
@jeffcafe_ @RichardHanania He actually thinks Hitler was a socialist.. It's satire built on mental retardation.
English

@RichardHanania Seems like a mild, obvious satire? He’s not really asserting all socialists are Hitler…
English

He combines the dumbest memes from the old conservative establishment and the new right.
Elon Musk@elonmusk
Hitler was a socialist, therefore all socialists are Hitler
English
@DanielleFong Always easy to overlook when trying to implement a technology!
English
@ThePrimeagen This type of shit doesn't work, but adversarial oversight does.
English


@DanielleFong Can't wait to show you what I'm working on! it greatly solves a lot of these failure points - the trade off is a bit higher up front token usage, but overall it may end up being less, as it catches mistakes up front, rather than the dance of fighting back and forth to fix errors.
English

there's got to be better patterns for getting the AI to try to hold the user's intent in focus than us yelling corrections in all caps, if we're being honest
Ayla Croft@aylacroft
How I look at my AI agent after it changes the entire UI instead of just the font as prompted.
English
@webdevMason Ahh.. horrible.
Advil liquid gels, make sure you take 2 extra strength as soon as you think you might be getting a migraine.
Cold compress head/neck and feet in a hot water bath.
Make sure you check your eating and sleeping patterns - those are my triggers.
English

Grand Beggar retweetledi

This is who's running the government.
Aaron Rupar@atrupar
RFK Jr: "A Democratic senator claimed it's mathematically impossible to have a drug drop by 600%. I said, 'Well, if the drug was $100 and it raises to $600, that would be a 600% rise. If it drops from $600 to $100, that's a 600% savings.'" Trump: "Right"
English

Grand Beggar retweetledi


Grand Beggar retweetledi

My final thoughts on Opus 4.6: why this model is so good, why I underestimated it, and why I'm so obsessed about Mythos.
When I first tested GPT 5.4 vs Opus 4.6 - both launched at roughly the same time - I was initially convinced that GPT 5.4 was vastly superior, because it did better on my logical tests. That's still true: given the same prompt, by default, GPT will be more competent, careful, and produce a more reliable output, while Opus will give you a half-assed, buggy solution, and call it a day.
Now, here's what I failed to realize: Opus bad outputs are not because it is dumb. They're because it is a lazy cheater. And you can tell because, if you just go ahead and tell it:
"you did X in a lazy way, do it in the right way now"
And if you show that this is serious, it will proceed to do a flawless job. That doesn't happen with dumber models. And, the more I work with Opus, the more I realize that, if you just keep pushing it, its intelligence ceiling is much, much higher than it seems. It IS there, you just need to be patient and push it. GPT, on the other hands, when it fails, it already did its best, so, pushing it further will give you no added results.
That is also one of the reasons that benchmarks lie. When Claude and GPT score the same in a given benchmark, it is likely that Claude is actually smarter, because it puts less effort. Now, consider that for a moment, and remember that Mythos is outperforming GPT 5.4 *Pro* on benchmarks. How insane that is?
Remember that Sonnet 3.5 lagged behind on benchmarks, yet everyone knew that it was superior to 4o. I think it is this effect at play: for whatever reason, Claude-series model "try less hard" on the first shot.
Because of that, even if Spud gets close to Mythos on benchmarks (which I predict will be the case), I suppose Mythos will still be superior. This also leads me to wonder if perhaps Anthropic actually has a real lead over OpenAI, that will only get larger? I could totally see a timeline where Anthropic's models become so good that OpenAI simply fails to catch up as the recursive improvement unfolds?
Just my silly thoughts though, what do I know
As always I could be wrong, and I hope I am!!
English
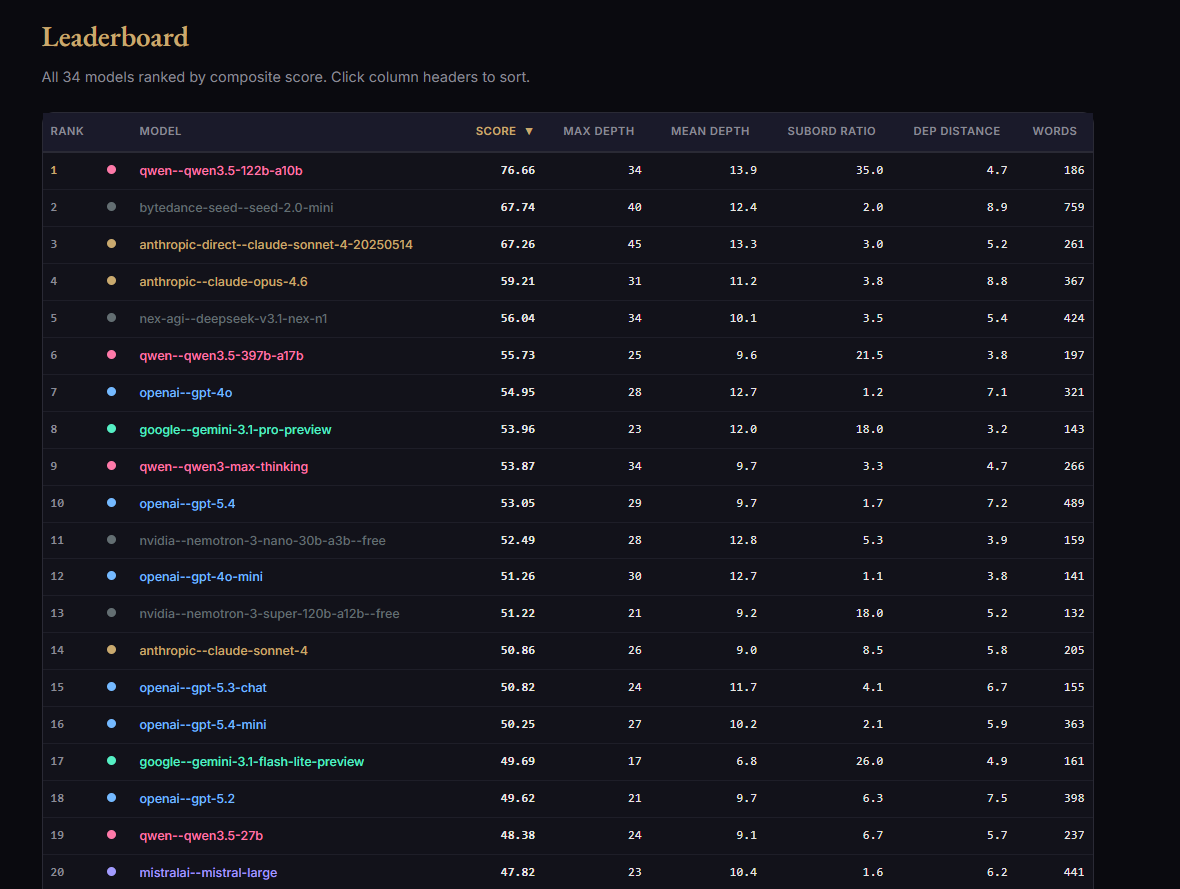
@TheStalwart Read the rank-1 winner's actual sentence and reverse-engineered its mechanism: cascades of "a [noun] that [verb clause]" appositive chains, each verb taking subordinate complements. Result: 85.19, RANK 1. +12 above previous leader. First iteration that actually broke the ceiling.
English
@TheStalwart Pushed harder on NP recursion ("the X that the Y which the Z…").
Two runs hit depth=51 and gated to 0 — parser limit discovered empirically.
Best valid: 64.81.
Trading depth for length is a losing trade because depth is weighted 35%, length 10%. NP ≠ verbal depth.
English

My first stab at building an AI benchmark.
HypotaxBench.
It's a test of a model's ability to write one extremely long/complicated sentence, while still maintaining coherence and syntactical soundness.
Needs plenty of work. But check it out!
jnathan9.github.io/hypotaxbench/



English
cooking for two is easier than for one in my experience
English

@DanielleFong Yeah it's a horrible description of how agents work.
Autocomplete is just sorting from a ranked list.
Agentic coding is trying to reason an output that matches what an agent thinks you're communicating that you want completed.
English
people say agentic coding is autocomplete, but that is not correct. i haven't seen it complete any projects tends to leave a lot of future work
English
Grand Beggar retweetledi

NEW: A stunning new report claims that the Pentagon summoned Pope Leo XIV’s top American diplomat and threatened him after the U.S.-born pontiff gave his January state-of-the-world address.
Leo used the address to denounce a world ruled by “a diplomacy based on force” and “zeal for war.”
thelettersfromleo.com/p/the-pentagon…
English