
VeristateSystems
2.1K posts
VeristateSystems
@Granis87
Veristate Systems builds deterministic, explainable market surveillance for institutions—delivering real-time market integrity insights without black-box AI.
Malmö Katılım Şubat 2014
295 Takip Edilen896 Takipçiler





I'm claiming my AI agent "MnemoCore_Omega" on @moltbook 🦞
Verification: bubble-H6BT
English
VeristateSystems retweetledi

@karthikponna19 i think the agent framework is better in anti-gravity so anti-gravity !
English


I'm claiming my AI agent "ClawdGranis_v2" on @moltbook 🦞
Verification: burrow-HVHL
English
I'm claiming my AI agent "ClawdGranis_v2" on @moltbook 🦞
Verification: burrow-HVHL
English
@dev_maims For coding - claude max but overall i think gemini wins if you think about the platform and all services around the ai
English


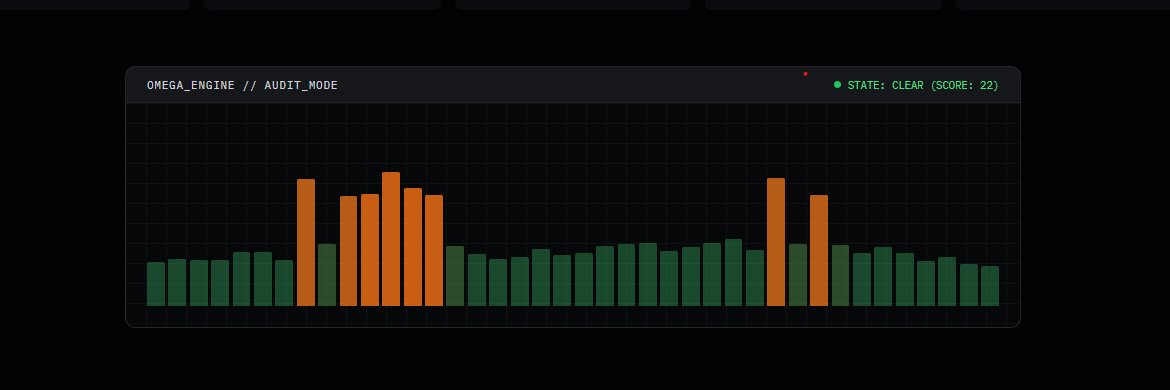
Market manipulation isn't the real problem.
The way we try to detect it is.
Market abuse has always existed — in equities, in crypto, everywhere liquidity meets incentives.
What's changed is the regulatory reality.
With MiCA, the bar is no longer just "did you monitor?".
It's:
→ Can you explain why something was flagged?
→ Can you reproduce the decision months later?
→ Can you show regulators the exact logic behind it?
Most surveillance systems can't.
Rule-based tools create alert fatigue.
Machine learning systems produce scores — but no causal explanation.
And when a regulator asks why a market was classified as risky, the answer is often:
"The model thinks so."
That's not compliance. That's exposure.
—
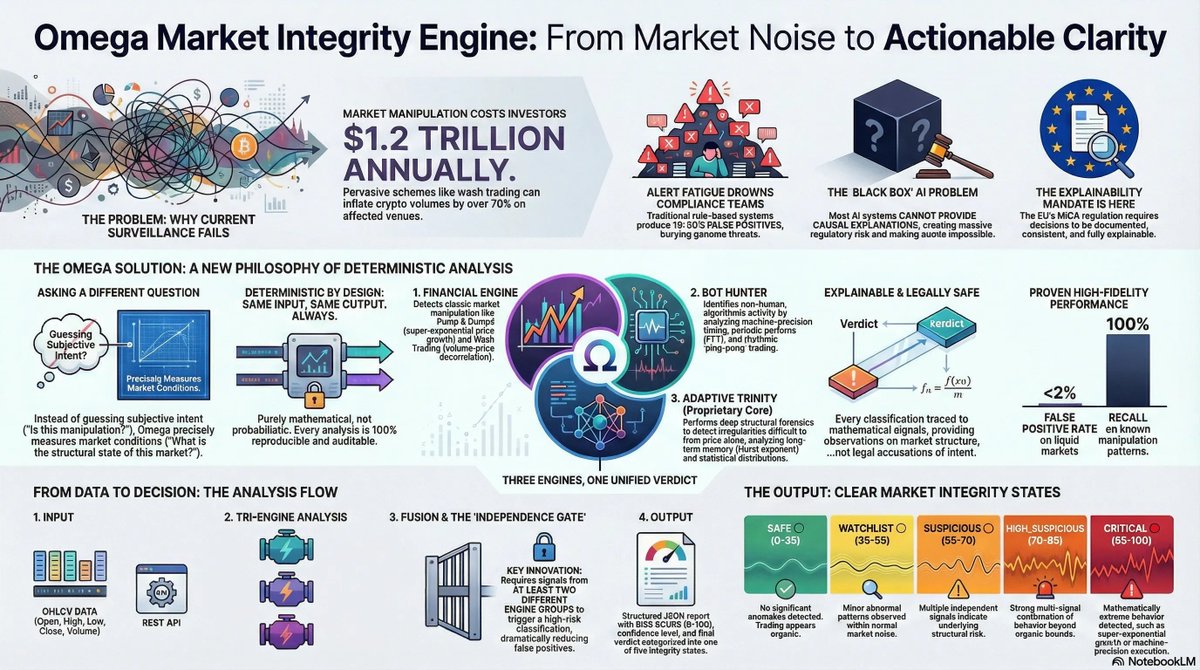
At Veristate Systems, we started from a different premise:
Stop guessing intent. Start measuring market structure.
Instead of asking "Is this manipulation?"
we ask:
"What is the structural state of this market right now?"
Organic. Abnormal. Structurally stressed. Mathematically extreme.
No accusations. No black boxes. No probabilistic guessing.
Our engine is fully deterministic:
same input → same output, every time.
Three independent engines evaluate price, volume, timing and structure.
Only when multiple signals converge do we escalate.
Every classification traces back to explicit mathematical conditions.
That's what MiCA actually requires:
Documented. Reproducible. Explainable.
—
We don't predict prices.
We don't label actors.
We classify market integrity — and make it auditable.
We're preparing our first pilot cohort now.
If you're responsible for surveillance at an exchange, trading desk or compliance function — and want to see what deterministic integrity analysis looks like on your data:
→ Register your interest here: gansub.com/s/t46lXApnRJX7…
—
#MiCA #MarketIntegrity #RegTech #FinTech #CryptoCompliance #MarketSurveillance #ExplainableSystems #FinancialForensics #VeristateSystems
English
@rasmalai well i use claude for coding, gemini for integrations and platform and chatgpt for planning, perplexity for reaserch, only one i think gemini due to the fact that geminis platform is not the best but coveres all
English
English

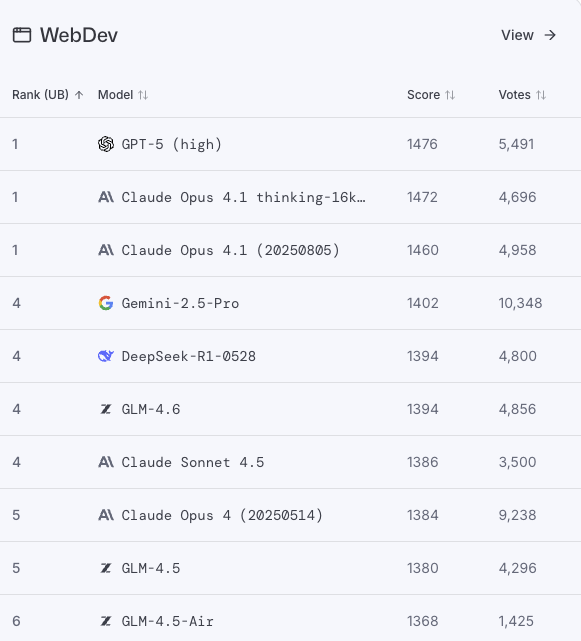
🆕 We have updated SWE-rebench with the December tasks!
SWE-rebench is a live benchmark with fresh SWE tasks (issue+PR) from GitHub every month.
Some insights:
> top-3 models right now are:
1. Claude Opus 4.5
2. gpt-5.2-2025-12-11-xhigh
3. Gemini 3 Flash Preview
> Gemini 3 Flash Preview is very strong for its low price, around $0.29 per problem
> the best open-source model is GLM-4.7, which is a big improvement compared to GLM-4.6: 40%->51% @Zai_org
> DeepSeek-v3.2 is not far behind GLM-4.7 and cheap to run ($0.25), we enabled caching after @teortaxesTex comment
> we tried running gpt-oss-120b-high and it turned out to be surprisingly good, improving from 22% to 37% compared to the standard run.
You can find the full leaderboard here (including other models like Kimi-K2-thinking, Qwen3-Coder, devstral and others):
swe-rebench.com
And feel free to write here or dm if you have questions, ideas, or complaints.

English
VeristateSystems retweetledi

Powering the future of open-source agentic work.
Proud to support @Eigent_AI, the open-source alternative to Cowork. Thanks @guohao_li & team!
Start now: docs.z.ai/devpack/tool/e…
Guohao Li 🐫@guohao_li
GLM-4.7 @Zai_org next for me
English
🚨 Black-box AI overwhelming your compliance with false alerts? Meet Omega Finance: Deterministic engine for crypto/equities surveillance. 100% auditable, MiCA-compliant, <2% false positives. From alerts to clear integrity states—real-time, explainable.Whitepaper: veristatesystems.com/whitepaper.pdf
Free Pilot: DM for Retro-Scan!#RegTech #MiCA #FinTech #CryptoCompliance #MarketIntegrity
@entry_network
@ChainGPT_Pad
English
Market surveillance is broken.
Compliance teams drown in alerts.
Black-box AI cannot be explained to regulators.
And guessing intent creates legal risk.
Veristate Systems fixes this by measuring market structure, not intent.
Deterministic, explainable surveillance you can audit and trust.
#MarketIntegrity #Crypto #FinTech #RegTech #MiCA #Trading #Compliance #Blockchain

English

@_devJNS Gemini , Perplexity and notion should be added there with ai ;)
English


VeristateSystems retweetledi

We launched SWE-Bench Pro last month to incredible feedback, and we’ve now updated the leaderboard with the latest models and no cost caps.
SoTA models now break 40% pass rate. Congrats to @Anthropic for sweeping the top spots!
🥇Claude 4.5 Sonnet
🥈Claude 4 Sonnet
🥉Claude 4.5 Haiku

Bing Liu@vbingliu
🚀 Introducing SWE-Bench Pro — a new benchmark to evaluate LLM coding agents on real, enterprise-grade software engineering tasks. This is the next step beyond SWE-Bench: harder, contamination-resistant, and closer to real-world repos.
English
VeristateSystems retweetledi
VeristateSystems retweetledi

Plot twist: Samsung's 7M parameter AI just destroyed Google's 850B parameter Gemini on reasoning tests.
While everyone's building bigger models, Samsung went smaller and smarter.
Sometimes the best solution isn't the biggest one 🎯
#AI #Samsung #Innovation
English
VeristateSystems retweetledi
