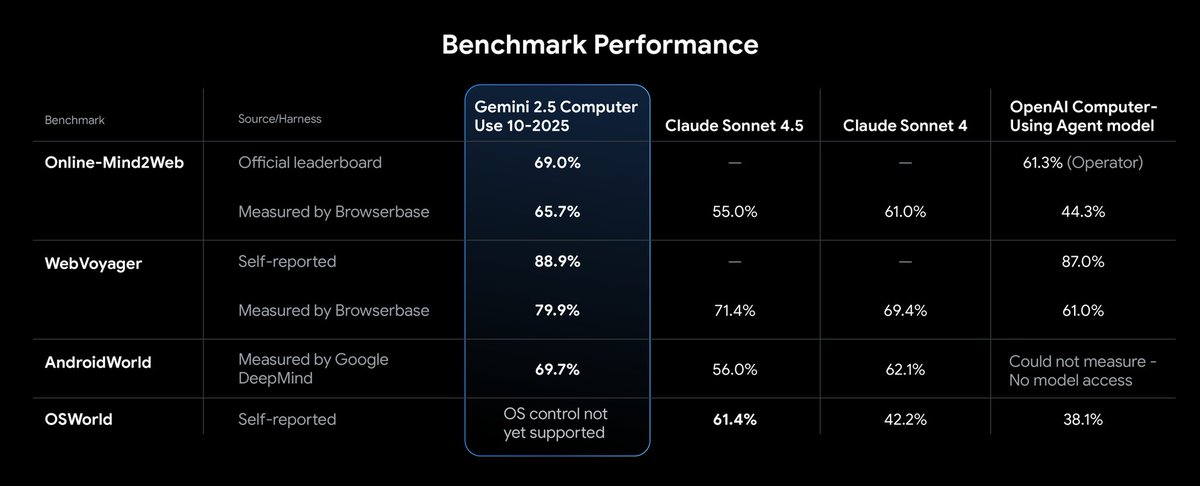
Guangxing Han retweetledi

True multimodal AI needs to understand the world spatially 🎯
🚀 Excited to release #CVPR2026 TIPSv2 from @GoogleDeepMind, a foundational image-text encoder with spatial awareness, leading to strong overall results and massive gains on patch-text alignment. 🔥
1/N

English