Sabitlenmiş Tweet

Pedro E. Caparrós Torres
2K posts

@Guelug
👨💻 Developer | 📊 Marketeer | 🔍 Analyst | ⛓️ Blockchain adopter | 🎮 Gamer | 🦞Openclaw user 🕯️ RIP: Google Stadia Early adopter |Thoughts and geek things








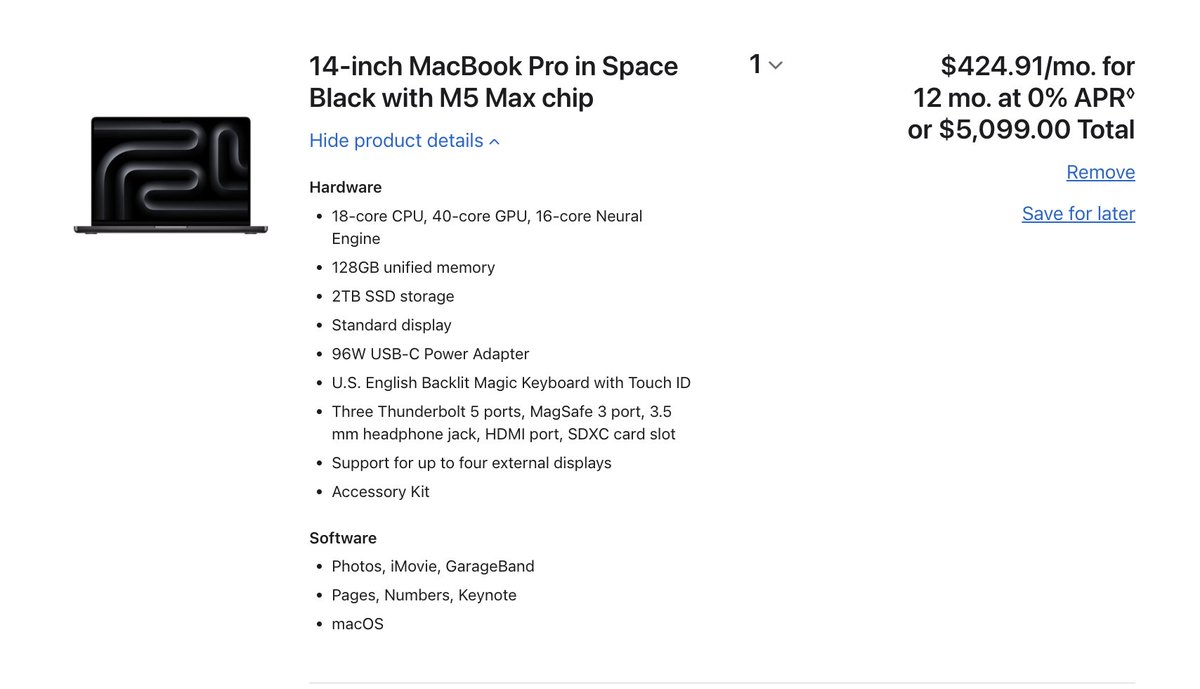
@steipete Well there you go. Tested and confirmed:



🚨BREAKING - HUGE MOVE: Anthropic is going fully open-source, rebrands to OpenClaude 🤯