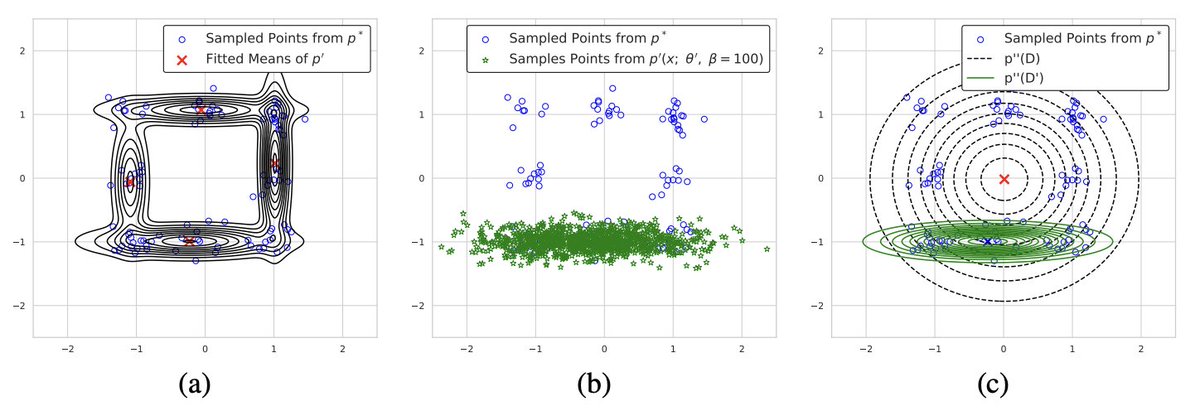
Gullal S. Cheema retweetledi

Gullal S. Cheema
700 posts

@Gullal7
Research Assistant @l3s_luh Previously Marie Sklodowska Curie ESR (PhD) @TIBHannover, Germany MUWS Workshop: https://t.co/XrHoXlMWsx Views are personal.



We are releasing 📄 FinePDFs: the largest PDF dataset spanning over half a billion documents! - Long context: Documents are 2x longer than web text - 3T tokens from high-demand domains like legal and science. - Heavily improves over SoTA when mixed with FW-EDU&DCLM web copora.








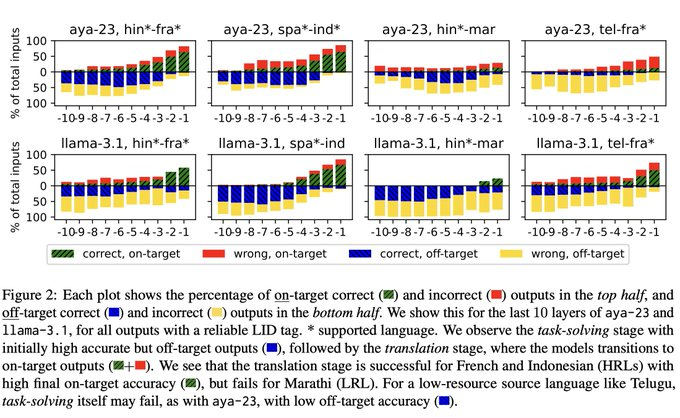
📢When LLMs solve tasks with a mid-to-low resource input/target language, their output quality is poor. We know that. But can we pin down what breaks inside the LLM? We introduce the 💥translation barrier hypothesis💥 for failed multilingual generation. arxiv.org/abs/2506.22724



i left my phd before joining openai working in industry demands more rigor – you don’t just need to convince reviewer 2 with a nice graph and an ego-cite, it better actually work if it’s underwriting billions in research investment not saying it always pans out that way in practice. yolo culture is pervasive and “research-quality code” abounds. i certainly don’t have a clean conscience there but some of the best breakthroughs come from people without academic preconceptions, with the discipline to build things that actually work