Sabitlenmiş Tweet

I’m happy to share that I’m starting a new position as Research Scientist at Meta!


English
Sungmin Cha
691 posts
@_sungmin_cha
Research Scientist at Meta | Formally Faculty Fellow @nyuniversity | PhD @SeoulNatlUni



‘몬티 홀 문제’의 정답을 수학자들이 해설과 시뮬레이션으로 보여줘도 사람들이 믿지 못하는 문제를 ”’몬티 홀 문제‘ 문제“라고 부르는건 어떨까요

We are seeking a highly motivated postdoctoral researcher to work on fundamental challenges toward AGI, particularly in reasoning, abstraction, and world modeling. The position also offers potential opportunities for co-advising with Yoshua Bengio (Mila) and/or Mengye Ren (NYU). Research areas include: • World Model Learning & Planning • Compositional Generalization & Neuro-Symbolic World Learning • Causal Discovery, Reasoning, and Abstraction This position is supported by the InnoCORE Fellowship Program 2026, with: • Competitive salary of KRW 90M+ (~USD 60K+) • Renewable yearly contract For more information and recent publications: mlml.kaist.ac.kr If you are interested, please send me your CV by email.

⏰ The CoLLAs abstract deadline is only 10 days away! We invite researchers to explore all facets of ML adaptation, from incorporating new capabilities during continuous training to efficiently removing outdated or harmful data. - 𝗔𝗯𝘀𝘁𝗿𝗮𝗰𝘁 𝗗𝗲𝗮𝗱𝗹𝗶𝗻𝗲: April 10, 2026 - 𝗦𝘂𝗯𝗺𝗶𝘀𝘀𝗶𝗼𝗻 𝗗𝗲𝗮𝗱𝗹𝗶𝗻𝗲: April 15, 2026 - 𝗖𝗼𝗻𝗳𝗲𝗿𝗲𝗻𝗰𝗲 𝗗𝗮𝘁𝗲𝘀: Sep 14–17, 2026 📚 Accepted papers will be published in the Proceedings of Machine Learning Research (PMLR). 🔗 𝗙𝗼𝗿 𝗳𝘂𝗹𝗹 𝗱𝗲𝘁𝗮𝗶𝗹𝘀 𝗼𝗻 𝘁𝗵𝗲 𝗖𝗮𝗹𝗹 𝗳𝗼𝗿 𝗣𝗮𝗽𝗲𝗿𝘀: lifelong-ml.cc/Conferences/20…


We’re releasing SAM 3.1: a drop-in update to SAM 3 that introduces object multiplexing to significantly improve video processing efficiency without sacrificing accuracy. We’re sharing this update with the community to help make high-performance applications feasible on smaller, more accessible hardware. 🔗 Model Checkpoint: go.meta.me/8dd321 🔗 Codebase: go.meta.me/b0a9fb


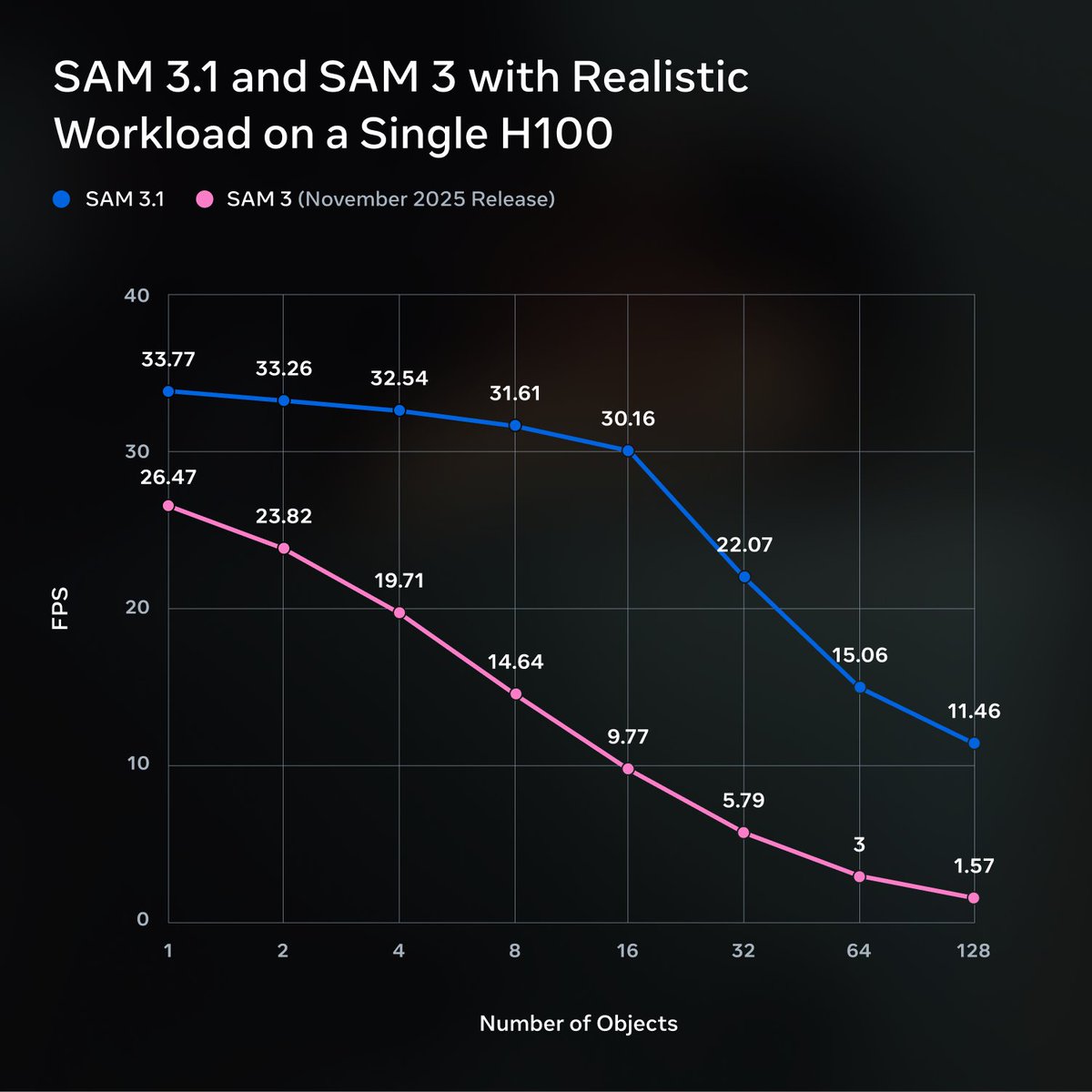

We’re releasing SAM 3.1: a drop-in update to SAM 3 that introduces object multiplexing to significantly improve video processing efficiency without sacrificing accuracy. We’re sharing this update with the community to help make high-performance applications feasible on smaller, more accessible hardware. 🔗 Model Checkpoint: go.meta.me/8dd321 🔗 Codebase: go.meta.me/b0a9fb
Today we're introducing TRIBE v2 (Trimodal Brain Encoder), a foundation model trained to predict how the human brain responds to almost any sight or sound. Building on our Algonauts 2025 award-winning architecture, TRIBE v2 draws on 500+ hours of fMRI recordings from 700+ people to create a digital twin of neural activity and enable zero-shot predictions for new subjects, languages, and tasks. Try the demo and learn more here: go.meta.me/tribe2





조깅 3일차. 타임라인에 열번쯤 올라온 TurboQuant arXiv 논문을 넣고 AO 만들어서 퇴근길, 빨래설거지, 조깅에 거쳐서 들어봤는데 어렵기도 하고 신기하기도 했다. 압축률이 Theoretical lower bound에 근접한다고? 시끌시끌할만 하구나 싶었다


This is massive. Google released TurboQuant, advanced theoretically grounded quantization algorithms - massive compression for LLMs. Tackles one of the nastiest costs in long-context LLMs: the KV cache, which stores small memory vectors for every past token and keeps growing as the prompt gets longer. The usual fix is quantization, where each number is stored with far fewer bits, but most methods quietly add bookkeeping data, so the real memory savings are smaller than they seem. Google’s idea is a 2-stage compressor that keeps the useful geometry of those vectors while stripping out most of that hidden overhead. PolarQuant first randomly rotates the vector, then rewrites pairs of coordinates as a length and an angle, which makes the data easier to pack tightly without storing extra per-block constants. That captures most of the signal, and then QJL uses just 1-bit signs on the tiny leftover error so the final attention score stays accurate instead of drifting. A simple way to picture it is this: PolarQuant stores the main shape of the memory, and QJL stores a tiny correction note almost for free. The other smart part is that this works without retraining or fine-tuning, so it can sit under an existing model rather than forcing the whole system to learn a new format. In Google’s tests, TurboQuant cut KV cache memory by at least 6x, reached 3-bit storage with no accuracy drop on long-context benchmarks, and showed up to 8x faster attention scoring at 4-bit on H100 GPUs. That is a big deal because long prompts are often bottlenecked not by raw compute, but by the cost of moving huge amounts of memory around. Overall, the real advance is not just better compression, but compression that attacks hidden overhead directly, which is why the speed gains look unusually strong for something this lightweight.


Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: goo.gle/4bsq2qI

Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: goo.gle/4bsq2qI

Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: goo.gle/4bsq2qI