@TheAhmadOsman Alternative? x.com/i/status/20506…
luthira@luthiraabeykoon
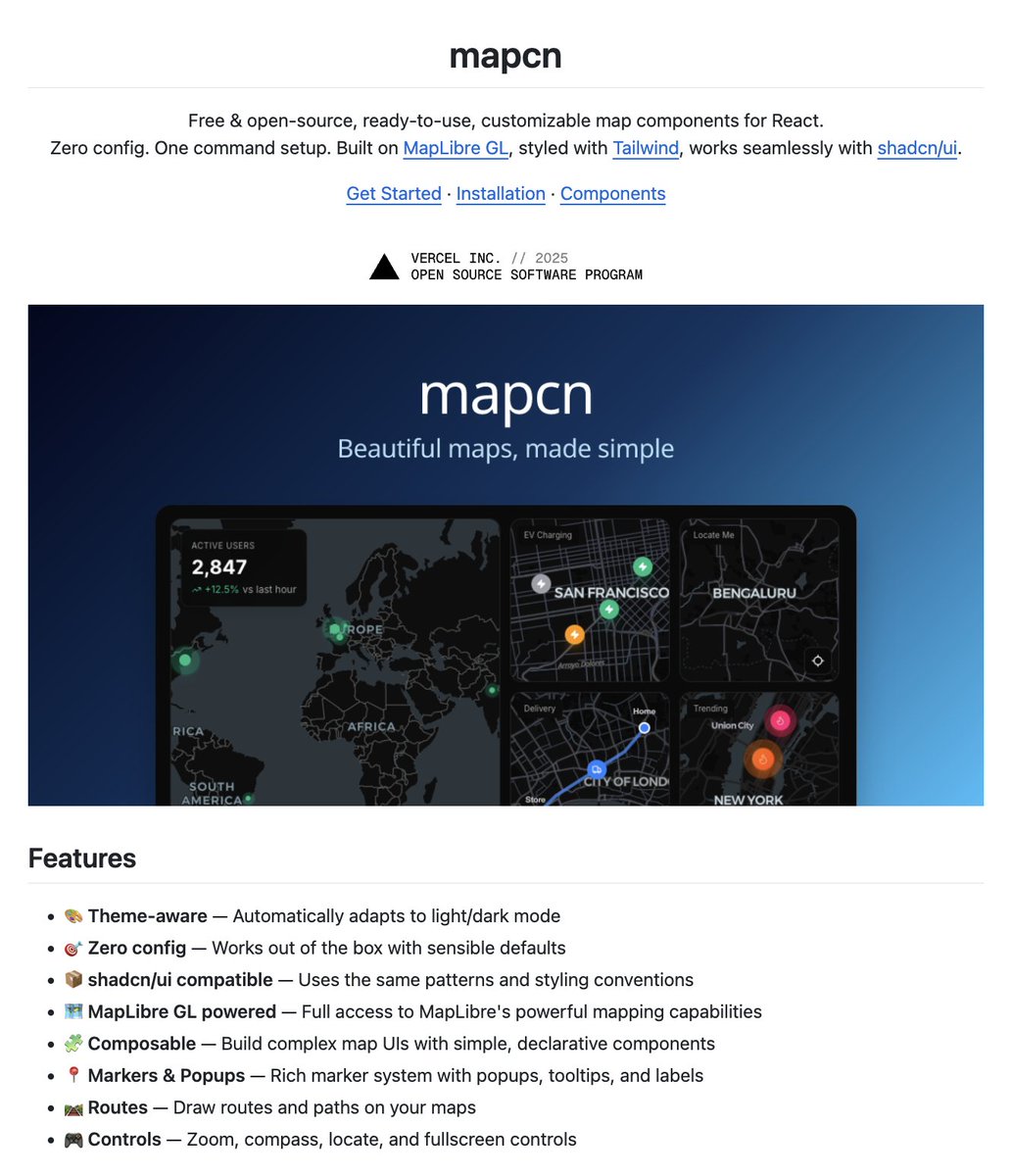
We implemented @karpathy 's MicroGPT fully on FPGA fabric. No GPU. No PyTorch. No CPU inference loop. Just a transformer burned into hardware, generating 50,000+ tokens/sec. The model is small, but the idea is not: inference does not have to live only in software 👇
English