niiya retweetledi

测试了一个晚上,答案已经出来了,推荐使用 tikhub,全面覆盖我上面说的所有的平台。
同时它也是 MediaCrawler 这个项目的赞助商,如果倾向于在本地跑爬虫,也可以试试这个开源项目。
user.tikhub.io/register?ref=U…
中文
niiya
1.1K posts


@Heres_2you
nell'illusione ho creduto alla mia forza inesorabile




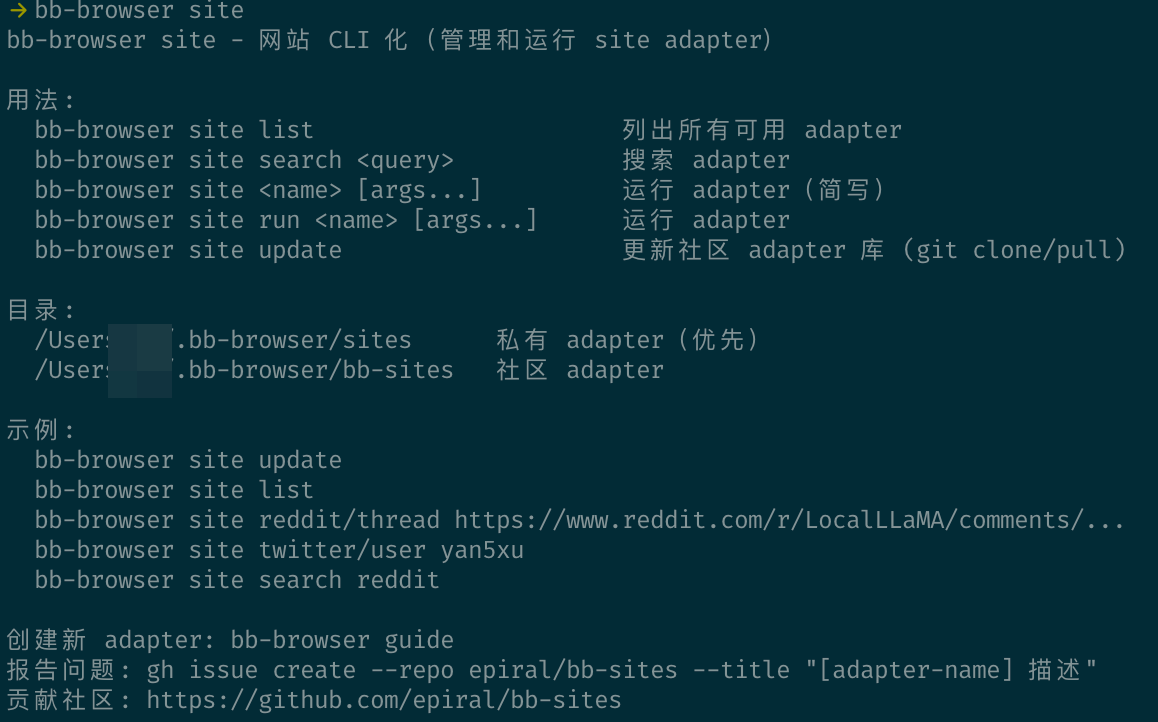
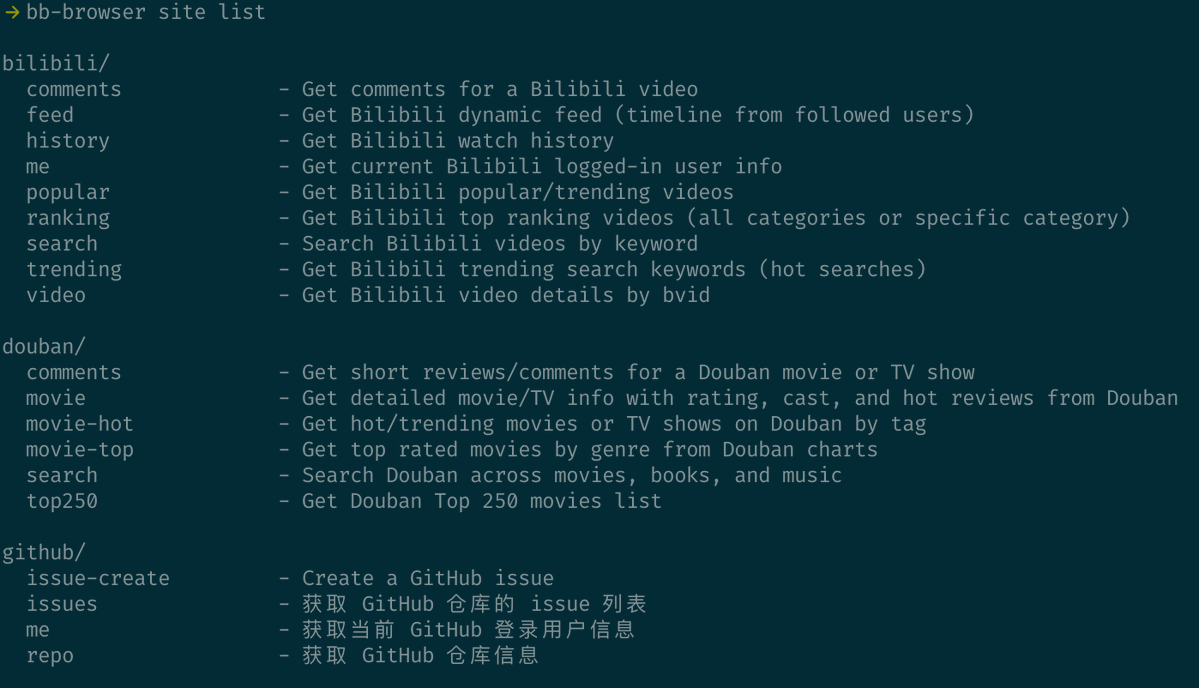
最近在折腾 OpenClaw 的数据采集能力,发现黄总推荐了一个挺顺手的工具叫 XCrawl 简单说就是一个 API 服务,输入 URL 或关键词,输出干净的 Markdown 或结构化 JSON。对经常要给 AI 喂网页内容的人来说非常实用,省掉了自己写爬虫、处理反爬、清洗数据这些体力活 我主要用了两个场景: 1️⃣ 一个是 Scrape,单页抓取。给一个 URL 直接拿到 Markdown 格式的正文,干净到可以直接丢进 Claude 做分析。JS 动态渲染的页面也能处理,不用自己折腾 Playwright 2️⃣ 另一个是 Search,多引擎搜索。输入关键词返回结构化的搜索结果,做竞品调研和内容选题的时候效率提升明显 最让我惊喜的是它和 OpenClaw 的集成,官方提供了四个现成的 Skill 文件,clone 下来放到 skills 目录,重启 OpenClaw 就能用。 之后你直接用自然语言跟 OpenClaw 说"帮我抓取这个网页"或者"搜一下这个关键词",它就自动调用 XCrawl 的 API 完成 内置的住宅代理池和防封机制省了很多事,不用自己维护代理服务器。成功率体感还不错,大部分公开网页都能稳定抓到 注册就送1000积分可以试用:xcrawl.com/?keyword=a3qyn… OpenClaw 集成教程在这:docs.xcrawl.com/zh/doc/develop…



A great resource if you want to understand how AI coding agents work. Learn Claude Code walks through building a minimal Claude Code like agent from scratch, explaining each mechanism step by step. You’ll see the core loop most coding agents share: call the model, execute tools, feed the results back, and iterate. A clean way to understand how these systems are actually built. learn-claude-agents.vercel.app

最新的界面做好了!如果大家喜欢的话,这个版本的skill我们也开源😆





AI时代,最值钱的资产是什么? 不是工具,不是模型,是圈子。 你用的工具,别人也在用 你追的资讯,别人也在追 但你认识的人,你进得去的圈子 ——这个才是真正的护城河 LET'S VISION 2026 就是这样一个地方 Apple生态 × AI × 空间计算 中国举办、面向全球的顶级开发者大会 获得Apple官方深度参与与认可 来这里你能看到什么: 1、Apple Design Award & App Store Award得奖团队亲自拆解作品 2、 端侧AI推理、LLM集成、M芯片实战部署——不是概念,是真的在跑的东西 3、Vision Pro / visionOS最前沿的空间计算Demo 4、投资人、早期创业团队、顶级开发者,都相聚在同一个屋子里 数字说话: 20+演讲 | 70+展位 近1/3参会者来自海外,覆盖近20个国家和地区 国内的朋友快冲吧,这种局可不是什么时候都有的👇 🔗 letsvision.swiftgg.team


这个文章拆解格式适合做成个skill,用来分析爆款文章👍 拆解格式是: - 核心观点 - 副观点 - 说服策略 - 情绪触发点 - 金句 - 情感曲线分析 - 情感层次 - 论证方式多样性 - 视角转化分析 - 语言风格特征 提炼所有给观众制造情绪价值的句式 提炼所有刺痛观众的句式


在云服务器中部署OpenClaw这篇教程挺详细 —— @yn_btc 博主 跟着教程去做就可以了,目前来看云服务器性价比挺高,安全性高、成本低、部署方便,同时还能实现服务7×24小时随时在线
