
Orionlee
49 posts



@myanTokenGeek 感觉纯软件层面,大模型都会越来越强的,几乎没啥门槛,还得去做硬件相关的,搓个可爱的皮套做AI公仔还得有审美和动手能力
中文

大家觉得 AI 时代技能方面有没有什么门槛?我感觉好像相关技能都很简单,系统学习也就是几天的学习量,这样的话大家都差不多了,拉不开差距啊。各位怎么看?
中文

hey anon if you're starting in local AI and confused between a 5090 and a 3090 GPU, save yourself and go with the 3090.
best value card for local inference right now. invest the remaining in a scalable node architecture, more pcie slots, ram, better psu. that foundation will thank you later when you start adding more GPUs.
i get this question a lot so this is my answer. if you're confused about which hardware to choose drop your budget below or DM me. i'll point you in the right direction, i work with setups from 8GB of VRAM to 700GB+.
алгусь@BrainOfMine
@sudoingX hello @sudoingX ! is it even worth to buy 5090 or 3090 would be enough?
English

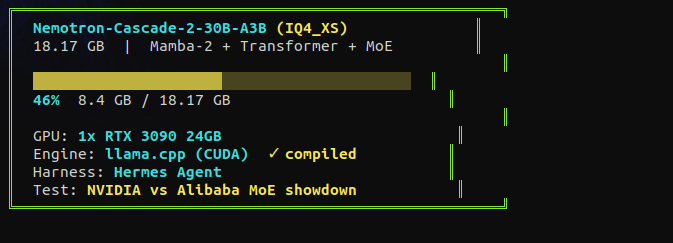
if you're about to download nvidia's nemotron cascade 2 at Q4_K_M for a single RTX 3090, stop. save yourself the frustration i went through last night.
Q4_K_M is 24.5GB. your 3090 has 24GB VRAM. the model loads, no room for KV cache, no room for context, no room for compute buffer. it will not run. this is a MoE architecture where the expert weights don't compress well at standard Q4. every quant table online lists it as "recommended" without checking if it fits consumer VRAM.
the fix: bartowski IQ4_XS at 18.17GB. imatrix quantization that's smarter about which weights need precision and which don't. same 4-bit tier, 6GB smaller because it doesn't blindly keep every expert at the same precision. leaves you 5.4GB of headroom for KV cache and context.
downloading it now on the same RTX 3090 i ran qwen 3.5 35B-A3B on at 112 tok/s. same machine, same node, same everything.
first up is context scaling sweep from 4K to 262K to see how mamba-2 handles long context compared to qwen's deltanet. then speed benchmarks at each context level. then i'm pointing hermes agent at it for autonomous coding sessions to see how it handles tool calls, file creation, and multi-step builds over long sessions.
nvidia vs alibaba. mamba vs deltanet. same hardware, different architectures. i'll report back with exact flags, exact numbers, exact VRAM breakdowns. no theory, no spec sheets. tested data from a real card.
Sudo su@sudoingX
the hype around this model settled fast. good. now i can test it without the noise. NVIDIA released nemotron cascade. 30B total, 3B active. fits on a single RTX 3090. hybrid mamba MoE. gold medal on the international math olympiad with only 3 billion active parameters. they say it beats qwen on math, code, and reasoning. i tested qwen 3.5 35B-A3B on a single 3090 at 112 tok/s. now same card, same tests, different architecture. mamba vs deltanet. nvidia vs alibaba. receipts incoming tonight.
English
@ixiaowenz kimi的agent集群功能还是不能调用,这个用来搜集信息真的太好用了,我偶尔就是用它的网页端的调取100个agent帮我搜索一些繁琐信息
中文

Kimi 199 Tier,一周的份额,跑一份最完整的报告大概需要一周份额的 20%-30%。
按照价格来均摊,大概 RMB 10-12 元左右。
真是不贵的。
Xiaowen@ixiaowenz
这是我在和朋友一起调试的商业模式分析工具,类似专注于商业分析场景的 Deep Research。 这篇文章是一个 Short Summary。背后是 7 个不同视角(宏观到微观,经济到运营)的独立分析报告,然后逻辑上整合浓缩到一起的超简单版(也有 6000 字左右)。 不同于单纯的使用正向 Deep Research 工具甚至只是 Web Search 然后让 AI 来分析并输出结果,这套 Agent 有比较严格的幻觉控制机制,对每个分析框架都固定了推理逻辑细节,并有逆向的逻辑对抗审核机制,这样实测在多个 Ralph Loop 后可以比较有效的推高整个报告的质量,产生有一些真的务实视角的洞察。(为了省钱,我自己的样例报告不会循环太多次,平衡成本问题) 对我个人来说,可以让我快速的了解一个感兴趣的陌生企业和行业,对我的部分创业者朋友来说,有了一些启发。 似乎就足够了。 我大概会在不断迭代和修改的过程中,经常的发我感兴趣的企业的商业分析,也可以让大家了解不同行业企业的一些皮毛商识。 但如果有特别不正确的或者冒犯的,请告知,我随时删除。 博君一笑。
中文



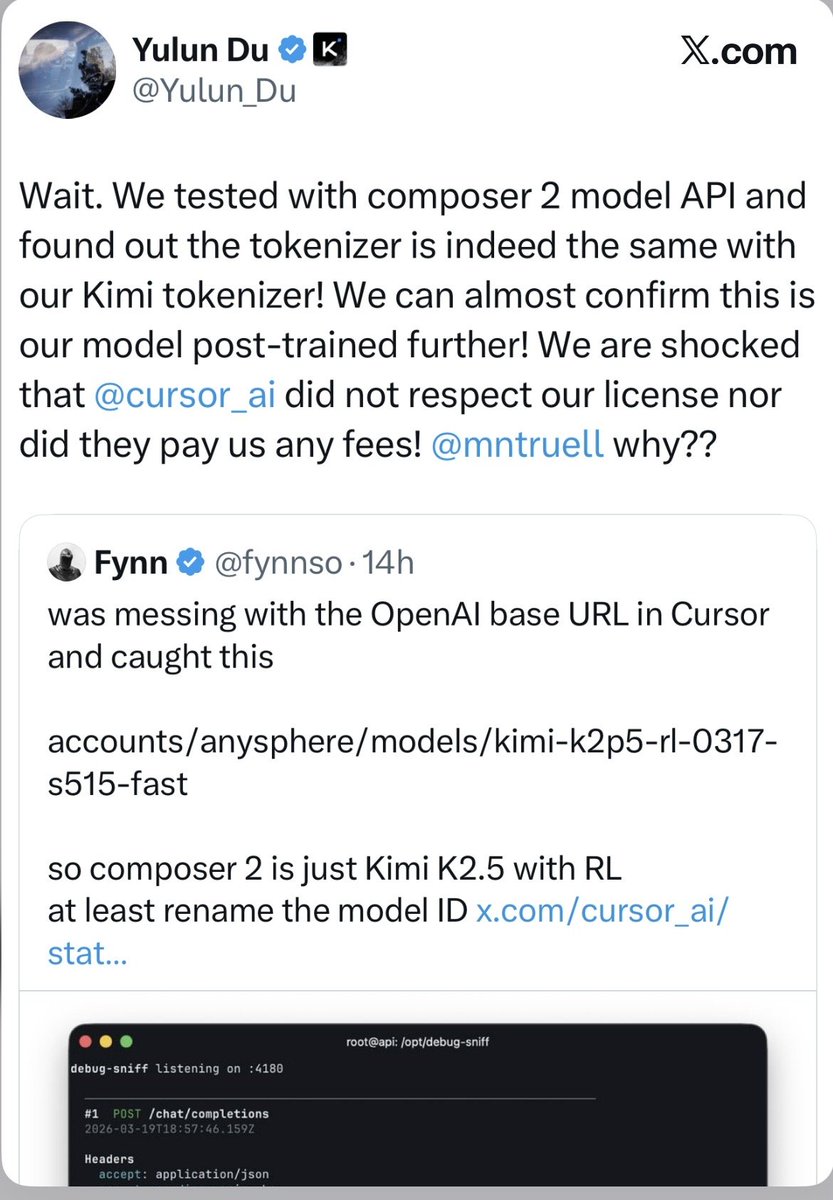
Cursor 上线 Composer 2 不到 24 小时,就被开发者扒出了底裤。
(以下内容 Claude 辅助生成)
一个叫 Fynn 的开发者在调试 Cursor 的 API 时,发现返回的模型 ID 赫然写着:kimi-k2p5-rl-0317-s515-fast。翻译成人话:这就是月之暗面(Moonshot AI)的 Kimi K2.5,加了一层强化学习(RL)微调。
Moonshot AI 预训练负责人 Yulun Du 随即在 X 上发帖确认,经测试 Composer 2 的 tokenizer 和 Kimi 的完全一致,并直接 @ 了 Cursor 联合创始人 Michael Truell,质问为什么不遵守许可证、也没有支付任何费用。另外两名 Moonshot 员工也发帖证实,不过三条帖子后来都被删除了。
而 Cursor 在 3 月 19 日发布 Composer 2 时,只提到性能提升来自"对基座模型的持续预训练加强化学习",全程没有提到 Kimi K2.5。这两件事并不矛盾,持续预训练和 RL 本来就是在某个基座模型上做的,Cursor 只是没说基座是谁的。
这不是第一次了
去年 10 月 Cursor 发布 Composer 1 时,多国开发者发现生成的代码中频繁出现中文。Alley Corp 合伙人 Kenneth Auchenberg 当时贴出截图,直言这是"铁证",认为 Composer 1 就是基于中国开源模型微调的。KR-Asia 和 36Kr 后来证实,Cursor 和 Windsurf 都在使用中国开源模型,其中 Windsurf 承认用的是智谱的 GLM。Cursor 从来没有公开披露 Composer 1 的底层模型,后来悄悄发了 Composer 1.5 就翻篇了。
许可证才是核心问题
Kimi K2.5 使用的是修改版 MIT 许可证,里面有一条专门为这种场景设计的条款:如果使用该模型(包括衍生作品)的商业产品月活超过 1 亿或月收入超过 2000 万美元,必须在产品界面上醒目展示"Kimi K2.5"字样。
Cursor 今年 2 月的年化收入已经突破 20 亿美元,换算成月收入大约 1.67 亿美元,是许可证门槛的 8 倍多。但 Cursor 的界面上只写着"Composer 2",没有任何 Kimi 的标识。
与此同时,Cursor 正在跟投资人谈一轮新融资,估值目标约 500 亿美元,相比去年 11 月的 293 亿美元估值几乎翻倍。而 Moonshot AI 上一轮估值据报道约 43 亿美元。一个估值是对方 12 倍的公司,拿了对方的模型包装成自研技术,用来支撑"前沿实验室"的叙事去融资。
截至目前,Cursor 没有做出任何公开回应。
这件事的后续走向,对整个开源 AI 生态有标杆意义。如果 Moonshot 不对一家年收入 20 亿美元的公司执行许可证,那以后所有开源模型的署名条款就成了摆设。每家 AI 实验室都会算同一笔账:为什么要开源自己的模型,让分发能力更强的公司去掉署名、包装成自研、然后以 12 倍于你的估值去融资?
Aakash Gupta@aakashgupta
Cursor is raising at a $50 billion valuation on the claim that its “in-house models generate more code than almost any other LLMs in the world.” Less than 24 hours after launching Composer 2, a developer found the model ID in the API response: kimi-k2p5-rl-0317-s515-fast. That’s Moonshot AI’s Kimi K2.5 with reinforcement learning appended. A developer named Fynn was testing Cursor’s OpenAI-compatible base URL when the identifier leaked through the response headers. Moonshot’s head of pretraining, Yulun Du, confirmed on X that the tokenizer is identical to Kimi’s and questioned Cursor’s license compliance. Two other Moonshot employees posted confirmations. All three posts have since been deleted. This is the second time. When Cursor launched Composer 1 in October 2025, users across multiple countries reported the model spontaneously switching its inner monologue to Chinese mid-session. Kenneth Auchenberg, a partner at Alley Corp, posted a screenshot calling it a smoking gun. KR-Asia and 36Kr confirmed both Cursor and Windsurf were running fine-tuned Chinese open-weight models underneath. Cursor never disclosed what Composer 1 was built on. They shipped Composer 1.5 in February and moved on. The pattern: take a Chinese open-weight model, run RL on coding tasks, ship it as a proprietary breakthrough, publish a cost-performance chart comparing yourself against Opus 4.6 and GPT-5.4 without disclosing that your base model was free, then raise another round. That chart from the Composer 2 announcement deserves its own paragraph. Cursor plotted Composer 2 against frontier models on a price-vs-quality axis to argue they’d hit a superior tradeoff. What the chart doesn’t show is that Anthropic and OpenAI trained their models from scratch. Cursor took an open-weight model that Moonshot spent hundreds of millions developing, ran RL on top, and presented the output as evidence of in-house research. That’s margin arbitrage on someone else’s R&D dressed up as a benchmark slide. The license makes this more than an attribution oversight. Kimi K2.5 ships under a Modified MIT License with one clause designed for exactly this scenario: if your product exceeds $20 million in monthly revenue, you must prominently display “Kimi K2.5” on the user interface. Cursor’s ARR crossed $2 billion in February. That’s roughly $167 million per month, 8x the threshold. The clause covers derivative works explicitly. Cursor is valued at $29.3 billion and raising at $50 billion. Moonshot’s last reported valuation was $4.3 billion. The company worth 12x more took the smaller company’s model and shipped it as proprietary technology to justify a valuation built on the frontier lab narrative. Three Composer releases in five months. Composer 1 caught speaking Chinese. Composer 2 caught with a Kimi model ID in the API. A P0 incident this year. And a benchmark chart that compares an RL fine-tune against models requiring billions in training compute without disclosing the base was free. The question for investors in the $50 billion round: what exactly are you buying? A VS Code fork with strong distribution, or a frontier research lab? The model ID in the API answers that. If Moonshot doesn’t enforce this license against a company generating $2 billion annually from a derivative of their model, the attribution clause becomes decoration for every future open-weight release. Every AI lab watching this is running the same math: why open-source your model if companies with better distribution can strip attribution, call it proprietary, and raise at 12x your valuation? kimi-k2p5-rl-0317-s515-fast is the most expensive model ID leak in the history of AI licensing.
中文

@_FORAB 国家财富分配制度的两级差异,体现在公司薪资也是一样的。
反而我认为日本这个分配相对公平些,也有可持续发展。
中文

挺有趣的视角,日本经济新闻的英文周刊,统计的各国核心技术 IT 岗位的薪资水平。
比如 IT 总监这个岗位区间上限
新加坡: 4200 万日元,约 182 万人民币年薪
中国:4000 万日元,约 173 万人民币年薪
香港:3900 万日元,约 169 万人民币
马来:2800 万日元,约 121 万
日本:2500 万日元,约 108 万
值得注意的是,马来西亚在科技企业 CTO、IT 总监、电子研发总监这三类核心岗位上的年薪,首次整体超过日本。
而中国是东亚最高水平梯队,想起了大厂那些百万年薪的技术组长和总监们,尤其是在半导体、AI 浪潮加速的背景下。
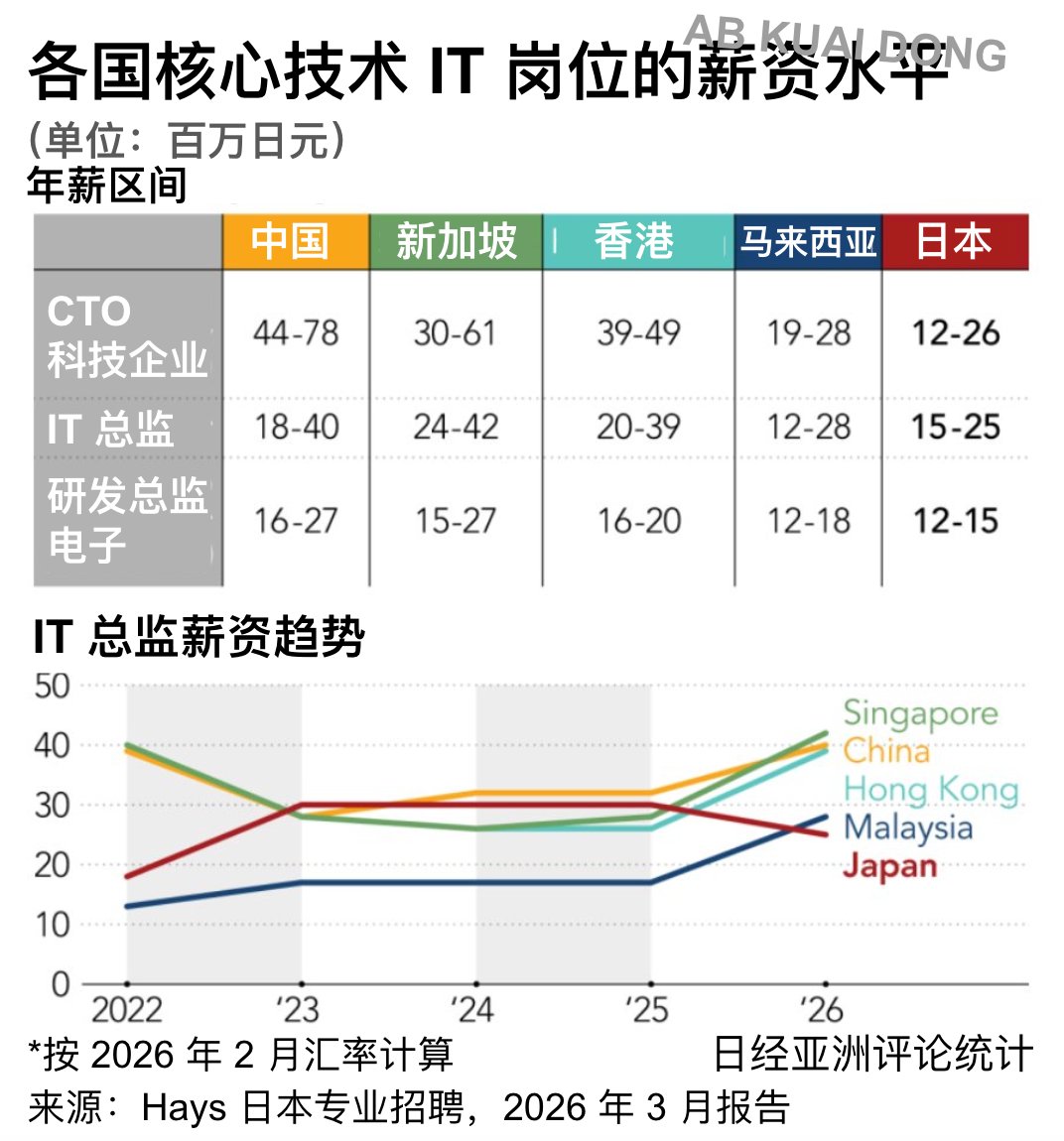
Nikkei Asia@NikkeiAsia
Malaysia has overtaken Japan in salaries for key technology roles for the first time, driven by rising investment in the booming semiconductor industry and intensifying competition in digital sectors. s.nikkei.com/40D2o4E
Minato-ku, Tokyo 🇯🇵 中文


@Hayami_kiraa kimi和qwen做的应用确实没有豆包好,这是事实,但kimi和qwen的大模型能力也确实好,从大模型到应用,中间有大堆工程要做
中文

@wangwatchworld 想多了,关于台湾的真实舆情,TK/抖音/小红书,都比民调靠谱得多,以北京的定力,只要等待台湾新一代年轻人上台就行
中文



