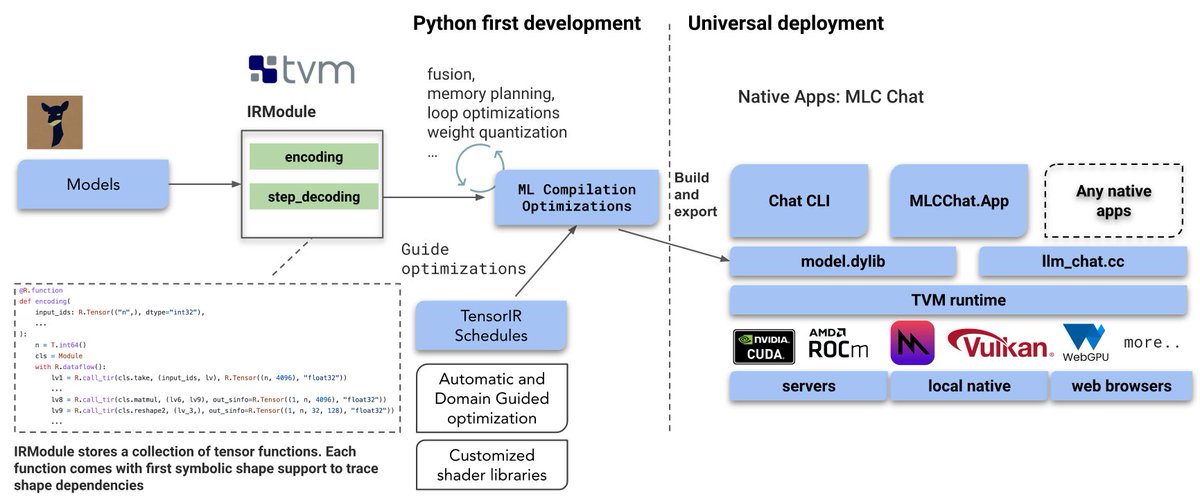
Hongyi Jin retweetledi

🤔 Can AI optimize the systems it runs on?
🚀 Introducing FlashInfer-Bench, a workflow that makes AI systems self-improving with agents:
- Standardized signature for LLM serving kernels
- Implement kernels with your preferred language
- Benchmark them against real-world serving workloads
- Fastest kernels get day-0 integrated into production
First-class integration with FlashInfer, SGLang (@lmsysorg ), and vLLM (@vllm_project ) at launch🙌
Blog post: flashinfer.ai/2025/10/21/fla…
Leaderboard: bench.flashinfer.ai

English