Andrew retweetledi
Andrew
857 posts



@The_AI_Investor I'm pretty sure OpenAI and Anthropic will have 1-2T in revenue by 2030. Maybe more)
English

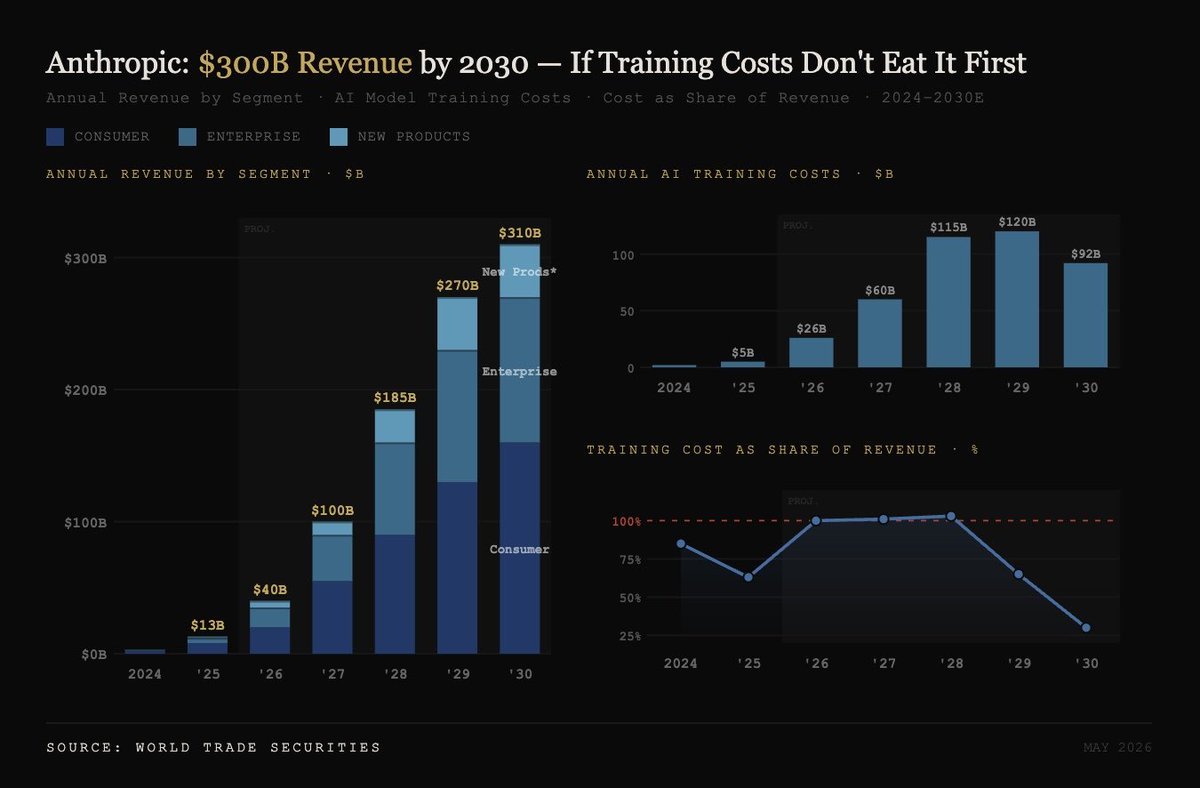
If Anthropic reaches around $300B in revenue by 2030, with inference gross margins of about 70%, it could generate roughly $210B in inference gross profit.
If training compute costs are around $100B and ex-compute operating expenses are about $20B, Anthropic could produce roughly $90B in operating profit.
This company could be worth a few trillion dollars in future.
English
Andrew retweetledi

“After AGI there will always be jobs for humans”
If there exists a job that a human can perform but an AI cannot, then we don’t have AGI. We either achieve AGI and there are no jobs left for humans, or we never achieve AGI and there is still a need for humans.
English

@petrroyce AGI has been achieved already.
ASI will be achieved within 3-6 months from now.
What happens after ASI is anyone's guess.
English

there will be AGI announced in H1 2027
it just won't be what you expect now but it will be first version of AGI
so i'm saying hello already
English
Andrew retweetledi

The fact that OpenAI is going to review every single applicant for the GPT-5.5 event with Codex and also cover flights and hotel shows how much they actually care about their users
They don't care about your financial situation or your follower count, they just want people who are genuinely passionate about Codex. I love that
English
@davidpattersonx But what about 10% this year and 20-30% next year?
x.com/davidpatterson…
David Scott Patterson@davidpattersonx
@PeterDiamandis @elonmusk That would be impossibly slow growth. I expect 10% this year, 20-30% next year, and more thereafter. It's the singularity. People need to start acting like they believe it.
English

Economic growth over the next few years will look something like this:
2026 - 5%
2027 - 15%
2028 - 30%
2029 - 50%
It starts slow because AGI won't arrive until the end of the year.
By 2030, AI will reach the optimal limit - able to do all jobs and perfect at everything.
English
Andrew retweetledi

xAI has launched Grok 4.3, achieving 53 on the Artificial Analysis Intelligence Index with improved agentic performance, ~40% lower input price, and ~60% lower output price than Grok 4.20
The release of Grok 4.3 places @xAI just above Muse Spark and Claude Sonnet 4.6 on the Intelligence Index, and a 4 points ahead of the latest version of Grok 4.20. Grok 4.3 improves its Artificial Analysis Intelligence Index score while reducing cost to run the benchmark suite.
Key Takeaways:
➤ Grok 4.3 improves on cost-per-intelligence relative to Grok 4.20 0309 v2: it scores higher on the Intelligence Index while costing less to run the full benchmark suite. Grok 4.3 costs $395 to run the Artificial Analysis Intelligence Index, around 20% lower than Grok 4.20 0309 v2, despite using more output tokens. This makes it one of the lower-cost models at its intelligence level
➤ Large increase in real world agentic task performance: The largest single benchmark improvement is on GDPval-AA, where Grok 4.3 scores an ELO of 1500, up 321 points from Grok 4.20 0309 v2’s score of 1179 Grok 4.3, surpassing Gemini 3.1 Pro Preview, Muse Spark, Gpt-5.4 mini (xhigh), and Kimi K2.5. Grok 4.3 narrows the gap to the leading model on GDPval-AA, but still trails GPT-5.5 (xhigh) by 276 Elo points, with an expected win rate of ~17% against GPT-5.5 (xhigh) under the standard Elo formula
➤ Grok 4.3’s performs strongly on instruction following and agentic customer support tasks. It gains 5 points on 𝜏²-Bench Telecom to reach 98%, in line with GLM-5.1. Grok 4.3 maintains an 81% IFBench score from Grok 4.20 0309 v2
➤ Gains 8 points on AA-Omniscience Accuracy, but at the cost of lower AA-Omniscience Non-Hallucination Rate of 8 points, so Grok 4.20 0309 v2 still leads AA-Omniscience Non-Hallucination Rate, followed by MiMo-V2.5-Pro, in line with Grok 4.3
Congratulations to @xAI and @elonmusk on the impressive release!

English

If AGI is almost here, why does YouTube not know what I want to watch
and Spotify not know what I want to hear?
English
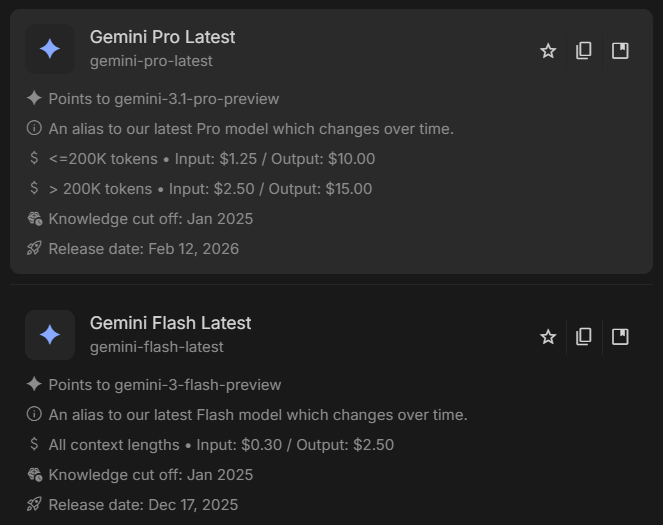
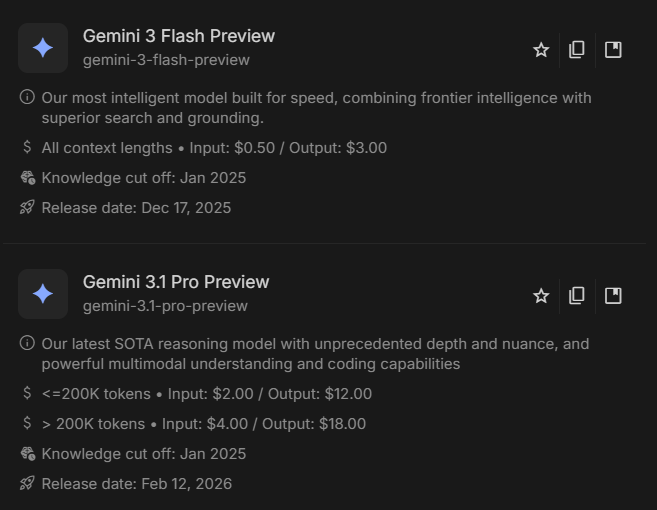
Just noticed Google removed the "New" label and mark 3.1 as "Pro Latest" in @GoogleAIStudio. I have a feeling we'll get Gemini 4.0 pro instead of 3.2/3.5 by Google I/O.
English
Andrew retweetledi

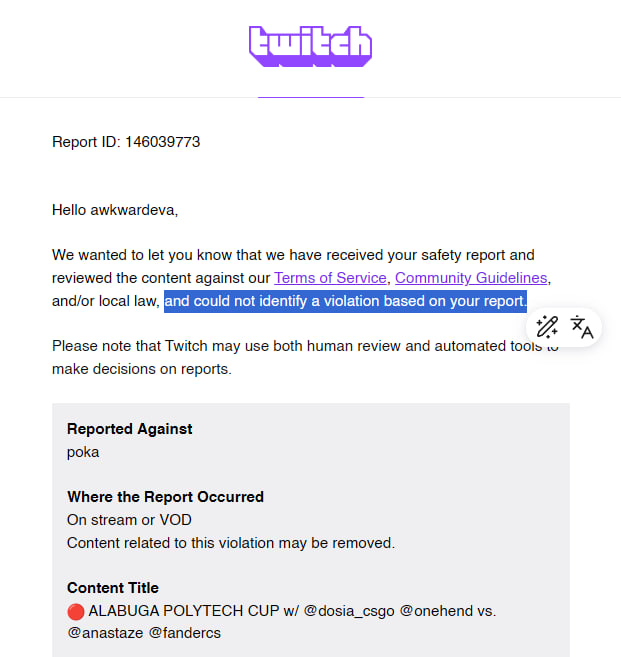
“Alabuga,” an entity under sanctions imposed by the US, EU, and UK due to its direct involvement in the production of military drones, is hosting and sponsoring an esports tournament on @Twitch, while the platform ignores violations and responds that no rules were broken

English

Breaking news, all major labs having new models being prepared for release.
English
It'll be very cool if @deepseek_ai , @Kimi_Moonshot, @Zai_org, @Alibaba_Qwen and @MiniMax_AI merge into 1 lab by EOY. Just like in AI 2027. It'd be super cool if they'd share all of their secrets, data and compute and train a 6-10T model to accelerate the race.
English
Andrew retweetledi

Andrew retweetledi
DeepSeek V4 Pro is the #1 open weights model on GDPval-AA, our agentic real-world work tasks evaluation
@deepseek_ai has released V4 Pro (1.6T total / 49B active) and V4 Flash (284B total / 13B active). V4 is DeepSeek's first new size since V3, with all intermediate models (V3.1, V3.2, R1, R1 0528) sharing the V3 family's 685B total / 37B active parameter MoE design. V4 Pro is also the largest open weights model released to date, surpassing Kimi K2.6 (1T total / 32B active) in both total and active parameter counts.
V4 Pro is released mostly in FP4 precision, putting total model size at ~865GB, comparable to Kimi K2.6 (INT4, ~500GB). GLM-5.1 is BF16 (~1.49TB) natively and typically served in FP8 or FP4. Both models are hybrid thinking/non-thinking, and we tested the reasoning variants at Max Effort and High Effort. We are currently running the full suite of evaluations in the Artificial Analysis Intelligence Index and will share updates imminently.
Key takeaways from evaluating GDPval-AA:
➤ V4 Pro leads all open weights models on GDPval-AA. V4 Pro (Reasoning, Max) scores 1554, ahead of GLM-5.1 (Reasoning, 1535), MiniMax-M2.7 (1514), and Kimi K2.6 (1484). V4 Flash (Reasoning, Max) scores 1388 well ahead of DeepSeek V3.2 (Reasoning, 1203) despite being a smaller model with fewer active and total parameters. V4 Pro (Reasoning, High, 1558) and V4 Flash (Reasoning, High, 1414) are effectively tied with their Max counterparts within the confidence interval
➤ V4 Pro is a significant upgrade on V3.2 in agentic capabilities. V3.2 (Reasoning) scored 1203 on GDPval-AA; V4 Pro (Reasoning, Max) scores 1554, a ~355 Elo point uplift. V4 Flash (Reasoning, High) scores 1414, a ~210 Elo point uplift over V3.2 (Reasoning) at a smaller and faster model size
➤ Output token usage varies materially across the V4 family on GDPval-AA. V4 Pro (Reasoning, High) used 8M output tokens on GDPval-AA and V4 Pro (Reasoning, Max) used 11M, in line with leading open weights peers Kimi K2.6 (10M) and MiniMax-M2.7 (7M). V4 Flash (Reasoning, Max) used 15M output tokens for a score of 1388, the highest token usage of any open weights peer on this benchmark. Notably, V4 Flash (Reasoning, High) scored higher at 1414 using only 7M output tokens
Key model details:
➤ Size: V4 Pro 1.6T total / 49B active, V4 Flash 284B total / 13B active ➤ Architecture: First new DeepSeek architecture since V3 (V3 family was 685B total / 37B active MoE)
➤ Modality: Text input and output only, equivalent to V3.2
➤ Context window: 1M tokens, an 8x expansion on V3.2's 128K context window
➤ Precision: Available as a mix of FP4 and FP8, or FP8 only
➤ License: MIT
➤ Availability: Available on DeepSeek's first-party API. As of writing, we expect many third-party providers to host the mode
➤ Pricing (DeepSeek first-party API): V4 Pro $1.74 / $3.48 per 1M input/output tokens, V4 Flash $0.14 / $0.28 per 1M input/output tokens. Cache hit input token pricing is $0.145 (V4 Pro) and $0.028 (V4 Flash) per 1M tokens

English

Kimi K2.6, for comparison.
Honestly don't know why the gap is so large.


English
My first two TiKZ Sparks unicorns from DeepSeek v4.
(Expert mode, from the DeepSeek site, which is supposed to be v4 Pro according to the release)
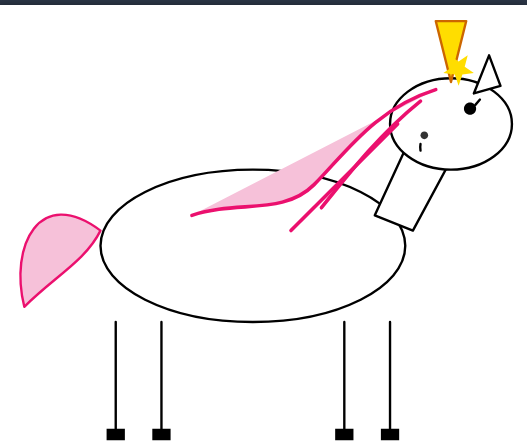
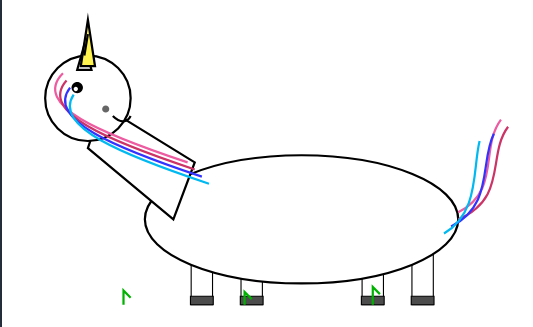
English