
Kineteq.ai
6.4K posts

Kineteq.ai
@ScienceOrMyth
Building in progress….. @ https://t.co/0MrCB7VuIp Captain Vibe AI and other things at https://t.co/MxLqkswimS
Katılım Nisan 2015
69 Takip Edilen279 Takipçiler



Kineteq.ai retweetledi

AGI will be seen like counting one day.
ASI will be basic algebra.
We don't have a name yet for what comes after.
English



Who will win the AI race?
- Anthropic
- OpenAI
- Gemini
English

If AI removes the need to learn, what should we still learn today ?
English
@EMostaque Eventually there will be the opposite of nanobots. Macrobots--bots the size of entire civilizations or even entire universes.
English



Kineteq.ai retweetledi

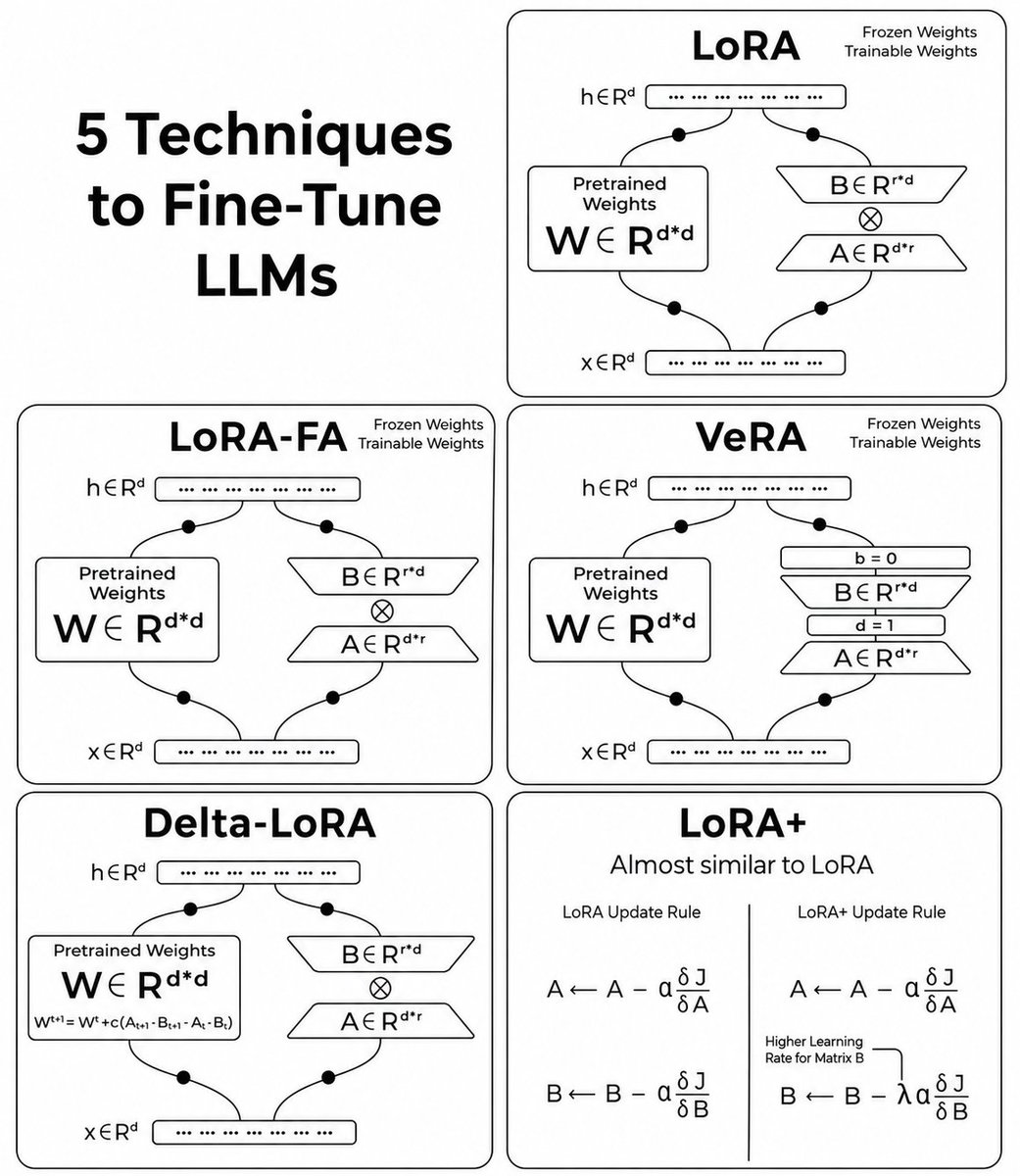
5 Mathematically Efficient Fine-Tuning Techniques for LLMs
This diagram compares the core math behind:
• LoRA – Low-rank decomposition (A ∈ R^{d×r}, B ∈ R^{r×d}) with frozen W
• LoRA-FA – Freezes one low-rank matrix during updates
• VeRA – Vector-based scaling with fixed d=1 and b=0
• Delta-LoRA – Updates pretrained weights using difference of low-rank products
• LoRA+ – Applies asymmetric learning rates to matrices A and B
Clear visual breakdown of weight matrices, dimensions, and update rules for parameter-efficient adaptation.
English

If AI can simulate entire realities, would we even know if we’re already in one?
English
Kineteq.ai retweetledi

“δ-mem: Efficient Online Memory for Large Language Models”
LLMs need long-term memory, but extending context is expensive and often doesn’t mean the model actually uses the history well.
What this paper did is to store past information in a tiny 8x8 associative memory state, then use that state to make low-rank corrections inside attention.
So memory is not retrieved as text or added to the prompt. It directly steers the frozen model’s computation.
With only 4.87M trainable parameters, δ-mem improves Qwen3-4B from 46.79 to 51.66 average score, with bigger gains on memory-heavy benchmarks like MemoryAgentBench and LoCoMo.

English
Kineteq.ai retweetledi

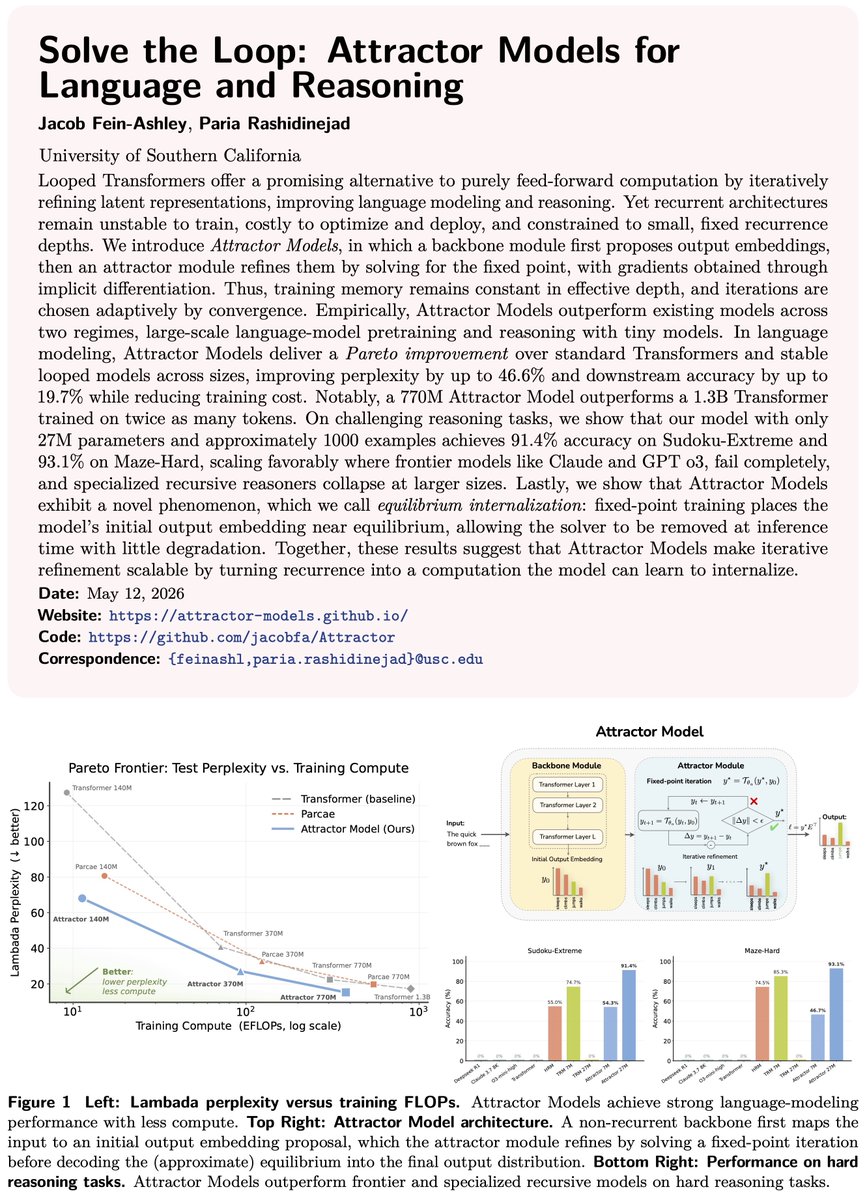
Looped Transformers: the dream was right. But there was trouble in paradise.
The loop made them unstable, expensive, and memory-hungry, with gains hard to scale. So we asked: 𝗖𝗮𝗻 𝘄𝗲 𝗿𝗲𝗮𝗽 𝘁𝗵𝗲 𝗿𝗲𝘄𝗮𝗿𝗱𝘀 𝘄𝗶𝘁𝗵𝗼𝘂𝘁 𝗽𝗮𝘆𝗶𝗻𝗴 𝘁𝗵𝗲 𝗹𝗼𝗼𝗽 𝘁𝗮𝘅?
Introducing 𝗔𝘁𝘁𝗿𝗮𝗰𝘁𝗼𝗿 𝗠𝗼𝗱𝗲𝗹𝘀 𝗳𝗼𝗿 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗮𝗻𝗱 𝗥𝗲𝗮𝘀𝗼𝗻𝗶𝗻𝗴:
• A Backbone proposes an initial “guess” output embedding;
• An Attractor refines it: a fixed-point solver lets the model “think” before each token.
Implicit differentiation trains the model stably, with constant memory and without BPTT.
Training also revealed a surprising phenomenon: 𝗘𝗾𝘂𝗶𝗹𝗶𝗯𝗿𝗶𝘂𝗺 𝗜𝗻𝘁𝗲𝗿𝗻𝗮𝗹𝗶𝘇𝗮𝘁𝗶𝗼𝗻
Over the course of training, the Backbone learns to propose latents close to the equilibrium itself, making the Attractor almost unnecessary at inference.
Results:
• 𝗣𝗮𝗿𝗲𝘁𝗼 𝗶𝗺𝗽𝗿𝗼𝘃𝗲𝗺𝗲𝗻𝘁 𝗼𝗻 𝗹𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗺𝗼𝗱𝗲𝗹𝗶𝗻𝗴: up to 𝟰𝟲.𝟲% lower perplexity and 𝟭𝟵.𝟳% better downstream accuracy. A 770M Attractor Model beats a 1.3B Transformer, despite being trained on half as many tokens.
• 𝗦𝗶𝗴𝗻𝗶𝗳𝗶𝗰𝗮𝗻𝘁 𝗴𝗮𝗶𝗻𝘀 𝗼𝗻 𝗵𝗮𝗿𝗱 𝗿𝗲𝗮𝘀𝗼𝗻𝗶𝗻𝗴 𝘁𝗮𝘀𝗸𝘀: a 27M Attractor Model trained on only 1K examples achieves 𝟵𝟭.𝟰% 𝗼𝗻 𝗦𝘂𝗱𝗼𝗸𝘂-𝗘𝘅𝘁𝗿𝗲𝗺𝗲 and 𝟵𝟯.𝟭% 𝗼𝗻 𝗠𝗮𝘇𝗲-𝗛𝗮𝗿𝗱, while Transformers and frontier models like Claude and GPT o3 score 𝟬%.
📝 arxiv.org/pdf/2605.12466
🧵 1/10
English
Kineteq.ai retweetledi

Want to read a masterpiece?
Try 'Partial Differential Equations of Physics' by Robert Geroch, a wonderful paper (in 52 pages) which is of course publicly available on arXiv.
🔗👇

English
Kineteq.ai retweetledi

Morgan Stanley pays $1,500,000/year for options MDs who can derive Black-Scholes from scratch.
This 80-minute MIT lecture gives you the same derivation that gets traders paid $125K/month for.
Bookmark & watch today. Then read the article below.
Phosphen@phosphenq
English
Kineteq.ai retweetledi

two professors at Wisconsin spent 25 years teaching operating systems together
then they wrote a 714 page textbook about "Operating Systems: Three Easy Pieces"
it covers virtualizing the CPU virtualizing memory concurrency persistence security and file systems
small enough to read in parts and also it is written like a conversation not a typical textbook
this is what you read if you want to really understand how operating systems work not just the theory

English
Kineteq.ai retweetledi

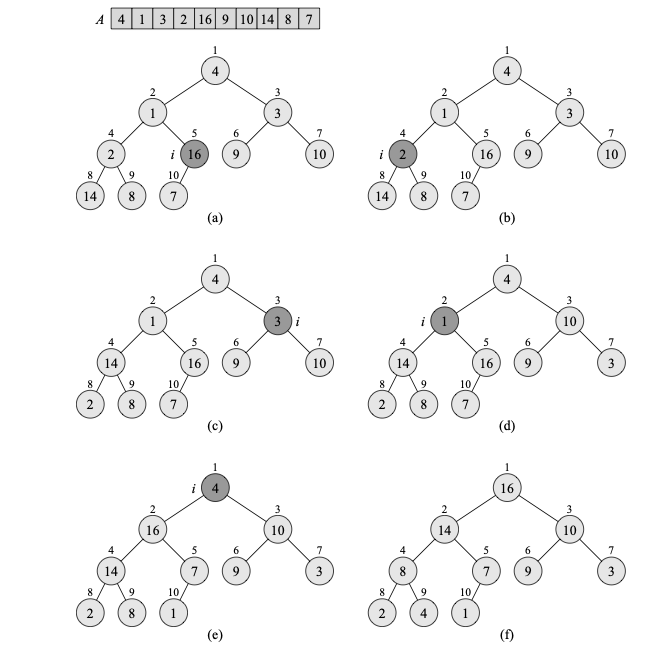
"Introduction to Algorithms" is an extraordinary university-level resource for anyone studying algorithms and computer science.
It covers computational complexity, data structures, graph algorithms, dynamic programming, divide and conquer methods, greedy algorithms, randomized algorithms, and many of the mathematical foundations underlying modern computer science.
What makes it particularly valuable is the balance between mathematical rigor and practical algorithmic reasoning. It is one of those books that profoundly shapes the way you think about problems, efficiency, and computation itself.
An absolute must-have in the toolkit of anyone working in computer science.
cs.mcgill.ca/~akroit/math/c…
English