Sabitlenmiş Tweet

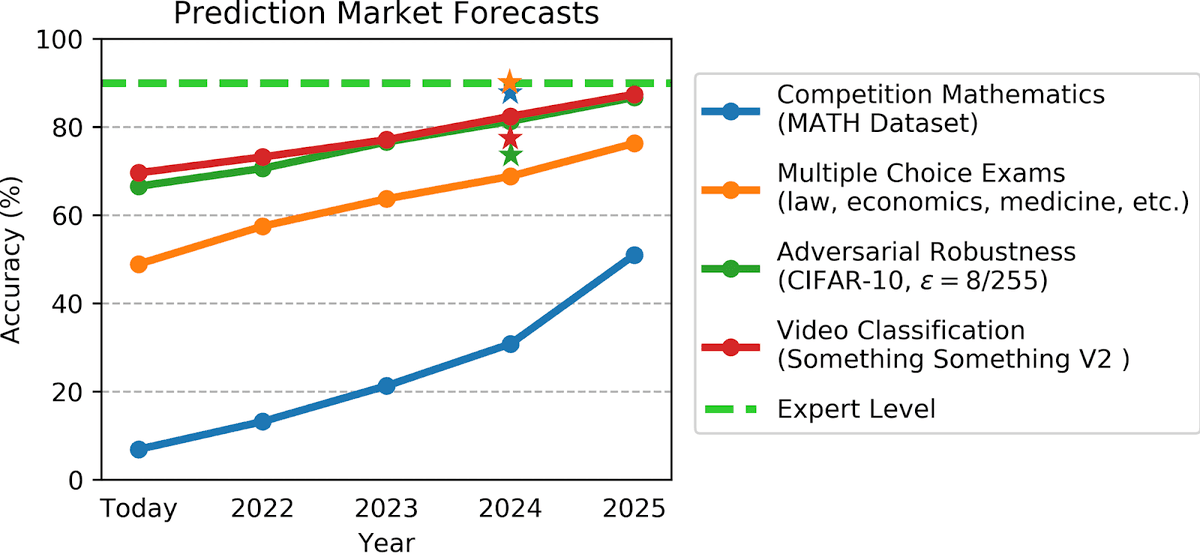
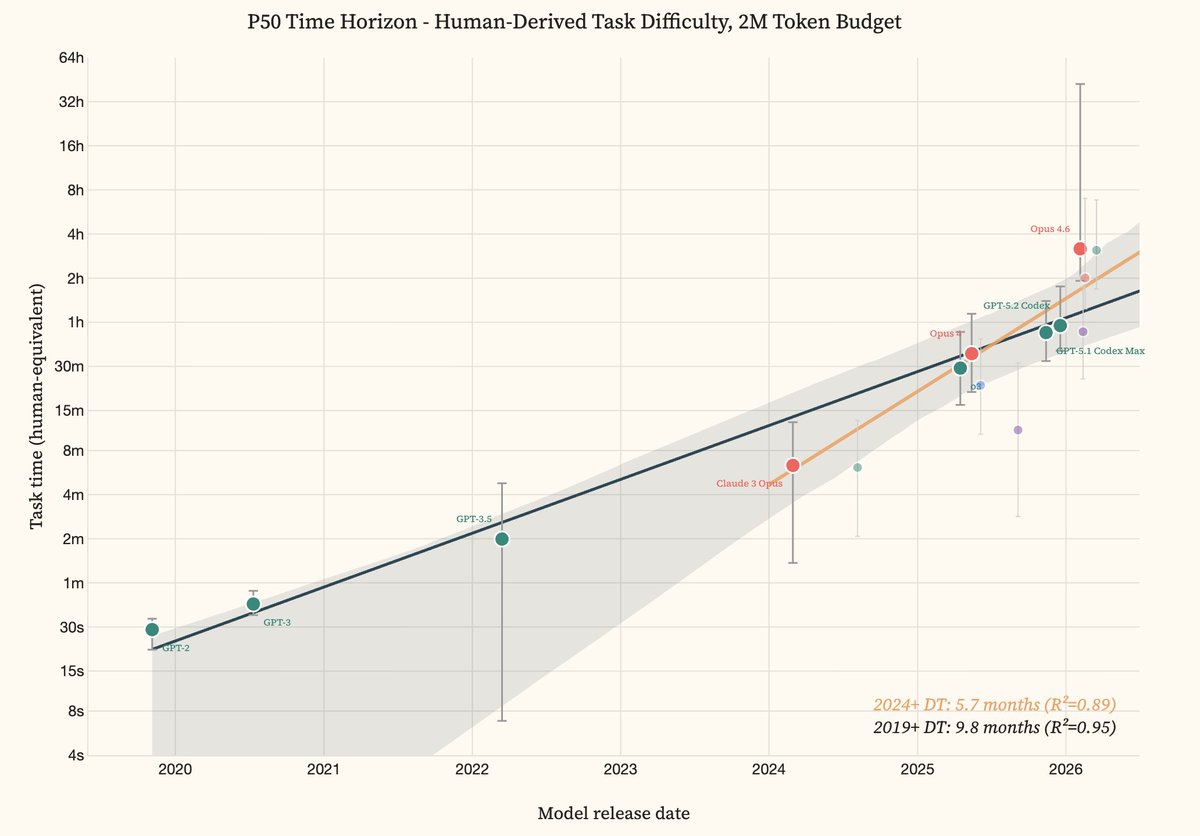
Superintelligent AI is possible in the 2020s -- progress continues to outpace predictions, and the trends in benchmarks and compute are unwavering.
English
Hunter Jay
1.3K posts

@HunterJayPerson
Engineer & entrepreneur, formerly w/Ripe Robotics. Very concerned about unfriendly superintelligence in the next decade. https://t.co/2bSqUt5evy

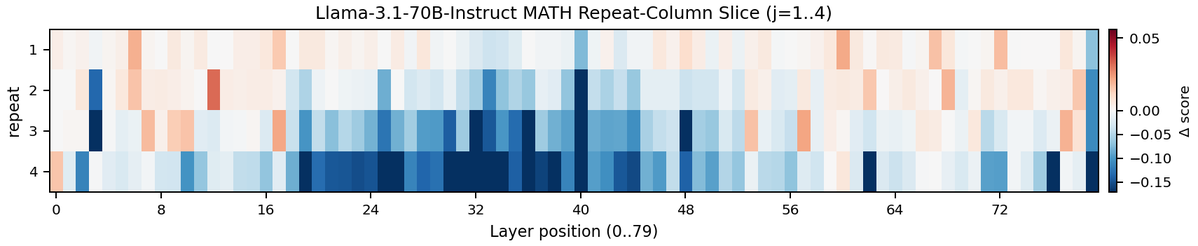
For example, we gave Claude an impossible programming task. It kept trying and failing; with each attempt, the “desperate” vector activated more strongly. This led it to cheat the task with a hacky solution that passes the tests but violates the spirit of the assignment.







1 million context window: Now generally available for Claude Opus 4.6 and Claude Sonnet 4.6.

Imagine this was your life, exploited, unable to even turn around for months at a time. Forced to give birth again and again, your babies taken from you every time. Years of suffering… and then you’re slaughtered.





Introducing Code Review, a new feature for Claude Code. When a PR opens, Claude dispatches a team of agents to hunt for bugs.
