lalaland
941 posts



罗福莉刚刚写了一篇很不错的文章。即使 Anthropic 正在切断 OpenClaw 这类第三方 agent 对 Claude 订阅的接入,罗福莉依然给整个 AI 生态提供了一个相对乐观的视角。 我很同意罗福莉说的很多浪费其实都来自设计不佳的 harness,小龙虾就是一个例子。它们在每次查询时发起多次高上下文 API 调用,拉低 cache hit rate,又白白烧掉大量 tokens。Anthropic 的这个决定,反而会倒逼整个生态在 context management、prompt caching 和整体效率上做得更好。这样的约束,往往最终会催生出真正的工程纪律,也会逼出新的创造力。 现在用 Claude,或者想办法给 Claude Code “薅到一个划算的 deal”,有时候真的像在菜市场里讨价还价,因为 token economics 已经成了最核心的问题。大家都在焦虑,自己的 tokens 或订阅额度到底会以多快的速度被烧光。我们也都害怕看到那句提示:“Your session will be refreshed at 3 a.m.” 也许,真正的后备方案只有本地模型,而最近 Gemma 4 这样的模型也说明了,这条路正在一天比一天更有吸引力。
Two days ago, Anthropic cut off third-party harnesses from using Claude subscriptions — not surprising. Three days ago, MiMo launched its Token Plan — a design I spent real time on, and what I believe is a serious attempt at getting compute allocation and agent harness development right. Putting these two things together, some thoughts: 1. Claude Code's subscription is a beautifully designed system for balanced compute allocation. My guess — it doesn't make money, possibly bleeds it, unless their API margins are 10-20x, which I doubt. I can't rigorously calculate the losses from third-party harnesses plugging in, but I've looked at OpenClaw's context management up close — it's bad. Within a single user query, it fires off rounds of low-value tool calls as separate API requests, each carrying a long context window (often >100K tokens) — wasteful even with cache hits, and in extreme cases driving up cache miss rates for other queries. The actual request count per query ends up several times higher than Claude Code's own framework. Translated to API pricing, the real cost is probably tens of times the subscription price. That's not a gap — that's a crater. 2. Third-party harnesses like OpenClaw/OpenCode can still call Claude via API — they just can't ride on subscriptions anymore. Short term, these agent users will feel the pain, costs jumping easily tens of times. But that pressure is exactly what pushes these harnesses to improve context management, maximize prompt cache hit rates to reuse processed context, cut wasteful token burn. Pain eventually converts to engineering discipline. 3. I'd urge LLM companies not to blindly race to the bottom on pricing before figuring out how to price a coding plan without hemorrhaging money. Selling tokens dirt cheap while leaving the door wide open to third-party harnesses looks nice to users, but it's a trap — the same trap Anthropic just walked out of. The deeper problem: if users burn their attention on low-quality agent harnesses, highly unstable and slow inference services, and models downgraded to cut costs, only to find they still can't get anything done — that's not a healthy cycle for user experience or retention. 4. On MiMo Token Plan — it supports third-party harnesses, billed by token quota, same logic as Claude's newly launched extra usage packages. Because what we're going for is long-term stable delivery of high-quality models and services — not getting you to impulse-pay and then abandon ship. The bigger picture: global compute capacity can't keep up with the token demand agents are creating. The real way forward isn't cheaper tokens — it's co-evolution. "More token-efficient agent harnesses" × "more powerful and efficient models." Anthropic's move, whether they intended it or not, is pushing the entire ecosystem — open source and closed source alike — in that direction. That's probably a good thing. The Agent era doesn't belong to whoever burns the most compute. It belongs to whoever uses it wisely.


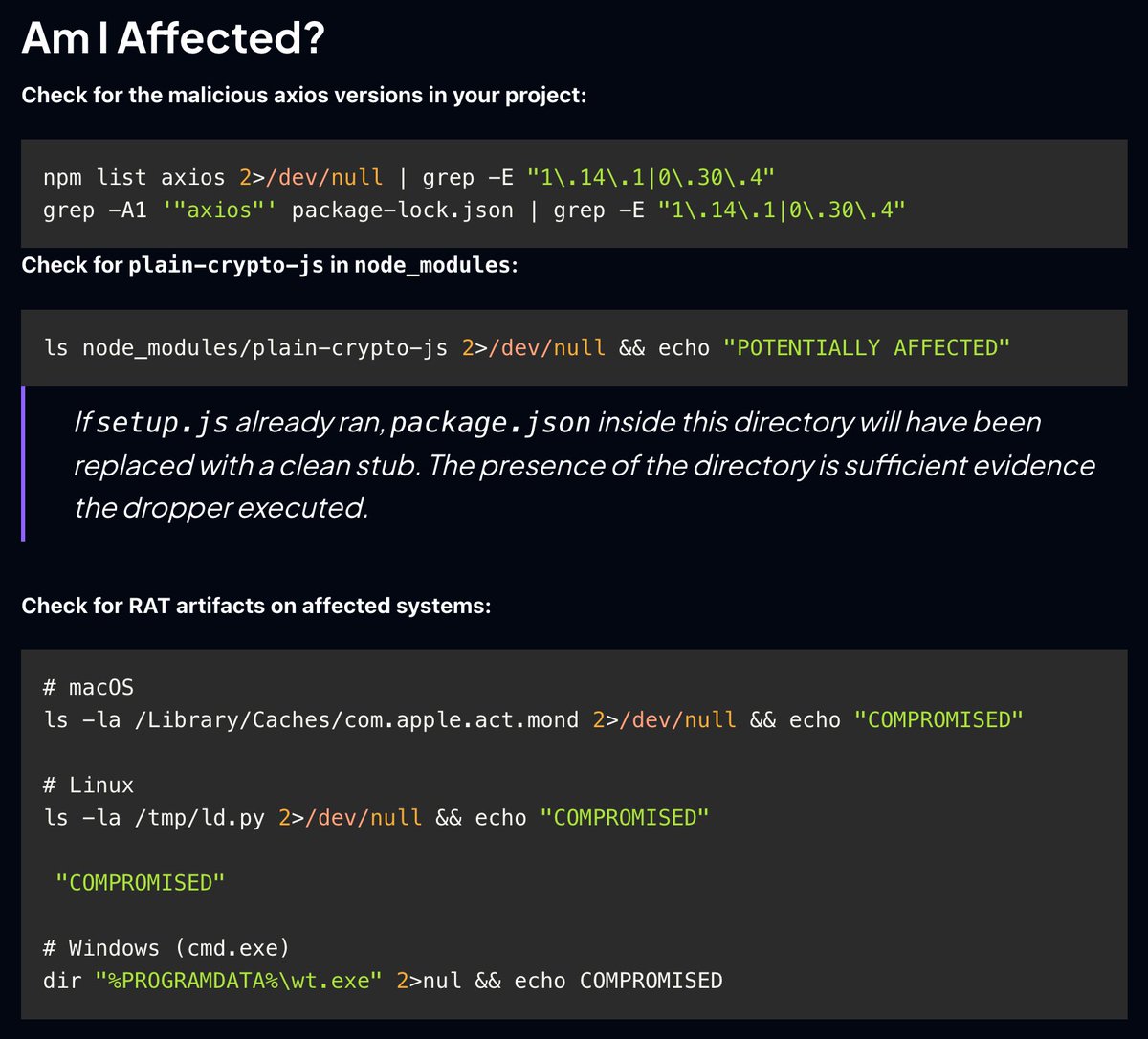
🚨 CRITICAL: Active supply chain attack on axios -- one of npm's most depended-on packages. The latest axios@1.14.1 now pulls in plain-crypto-js@4.2.1, a package that did not exist before today. This is a live compromise. This is textbook supply chain installer malware. axios has 100M+ weekly downloads. Every npm install pulling the latest version is potentially compromised right now. Socket AI analysis confirms this is malware. plain-crypto-js is an obfuscated dropper/loader that: • Deobfuscates embedded payloads and operational strings at runtime • Dynamically loads fs, os, and execSync to evade static analysis • Executes decoded shell commands • Stages and copies payload files into OS temp and Windows ProgramData directories • Deletes and renames artifacts post-execution to destroy forensic evidence If you use axios, pin your version immediately and audit your lockfiles. Do not upgrade.






我的 desktop 程序应该会用 rust+tauri 写(类 claude desktop),但是...看起来大家对 tauri 的评价并不怎么样,但是我真的很讨厌 electron 的巨大包,推油能给点决策建议吗
Introducing Void, the Vite-native deployment platform: 🚀 Full-stack SDK ⚙️ Auto-provisioned infra (db, kv, storage, AI, crons, queues...) 🔒 End-to-end type safety 🧩 React/Vue/Svelte/Solid + Vite meta-frameworks 🌐 SSR, SSG, ISR, islands + Markdown 🤖 AI-native tooling ☁️ One-command deploys void.cloud




