Sabitlenmiş Tweet

📄🚨 New!
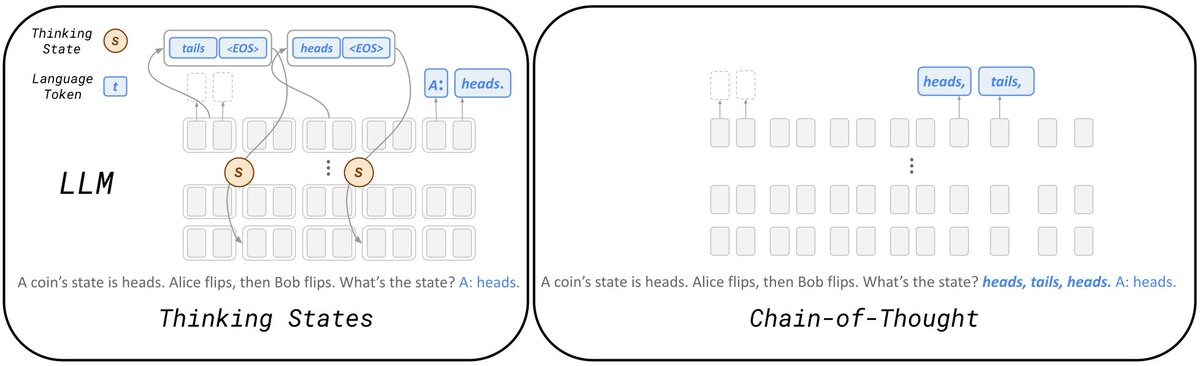
Tired of waiting minutes for LLMs to "think"?
Test-time scaling (O3, DeepSeek-R1) lets LLMs reason before answering — but users are left clueless, with no progress or control.
Not anymore!
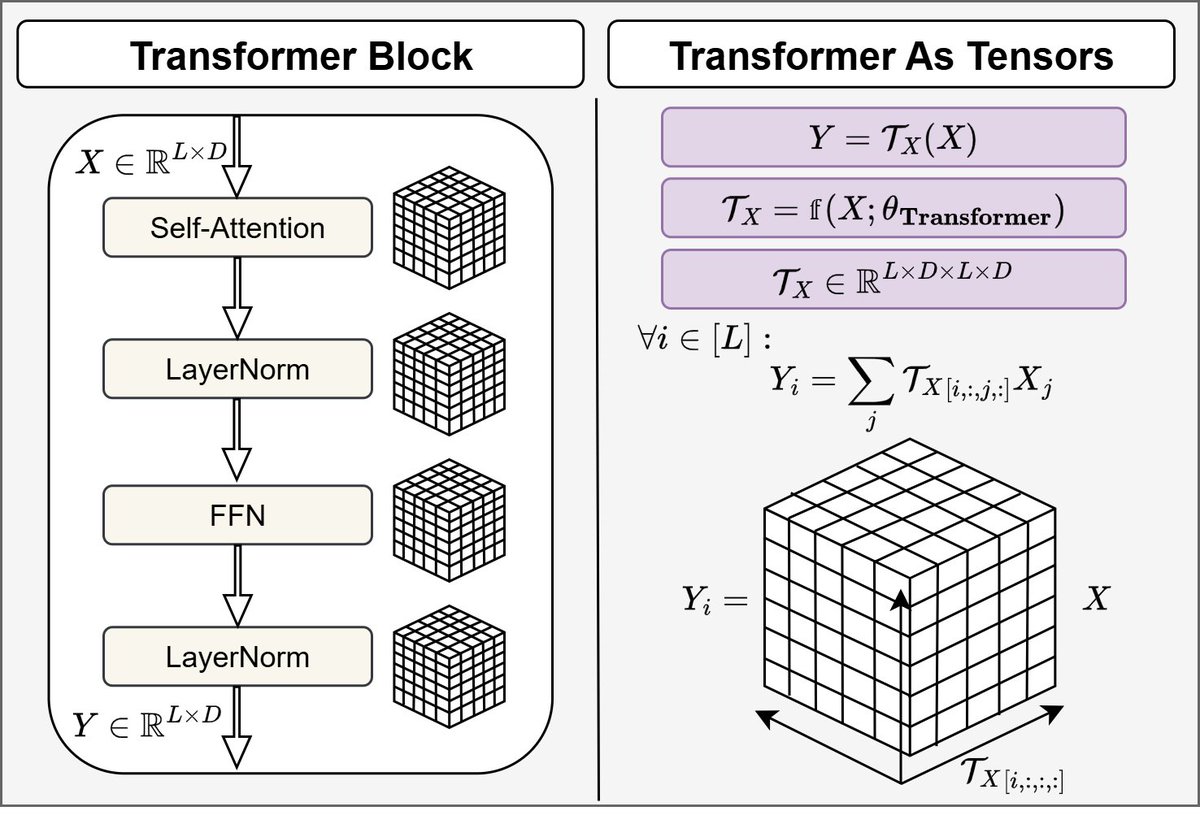
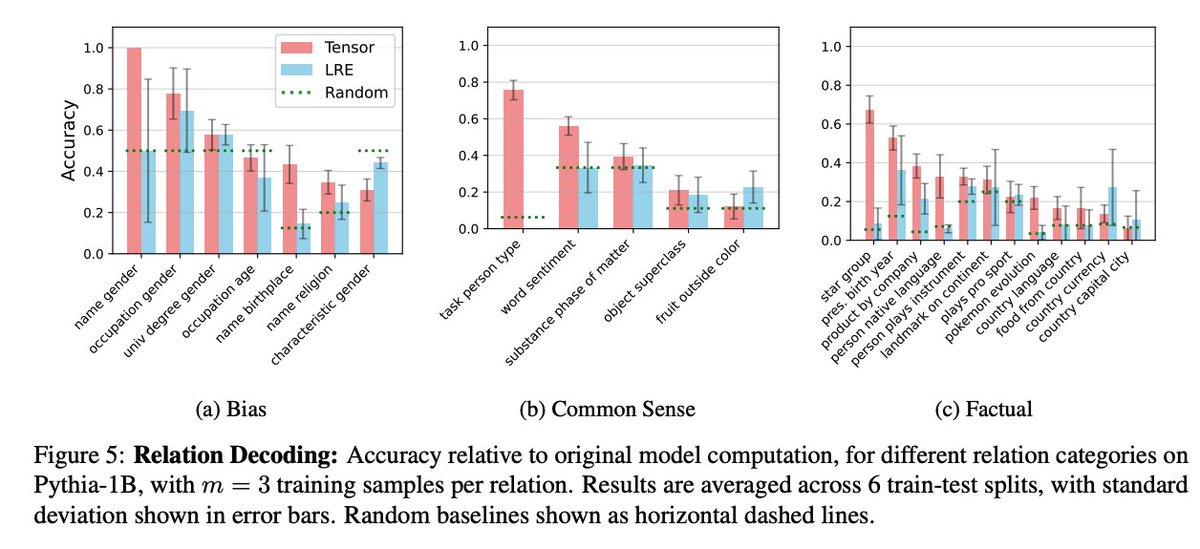
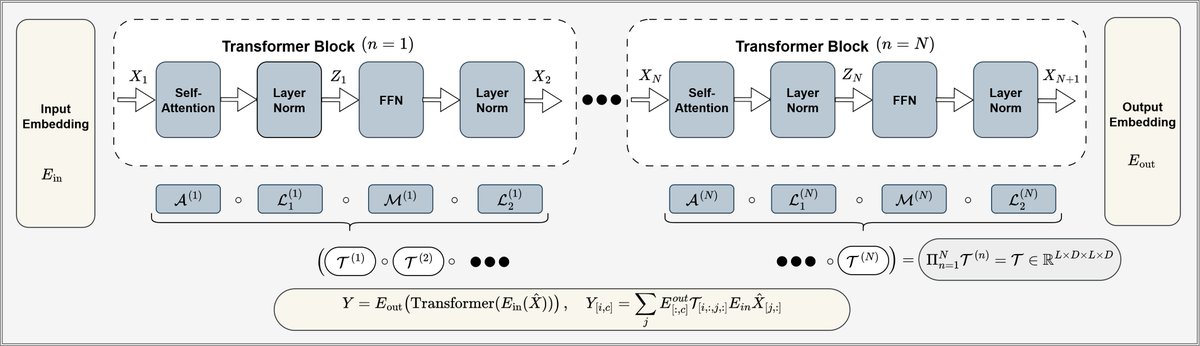
We expose the LLM’s internal 🕰️, and show how to monitor 📊 & overclock it⚡
🧵👇

English