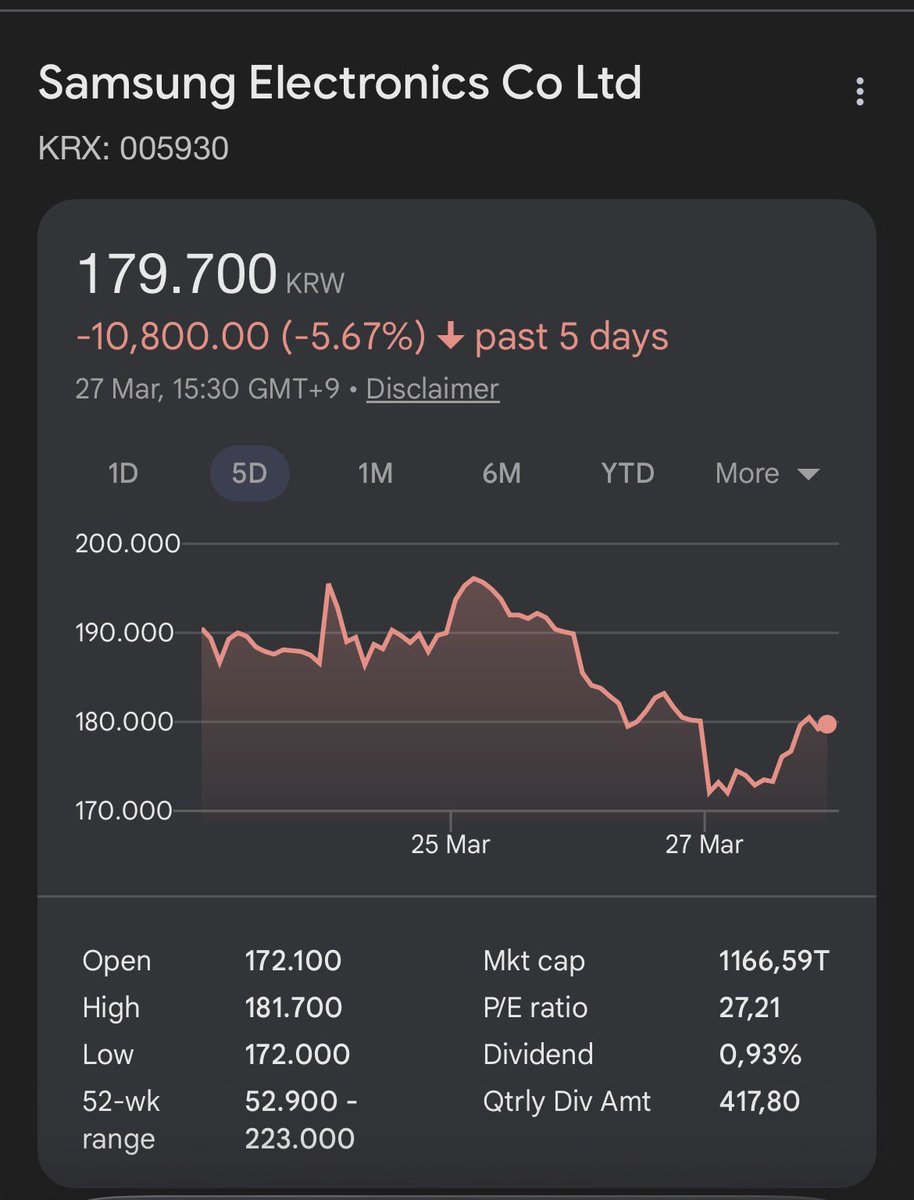
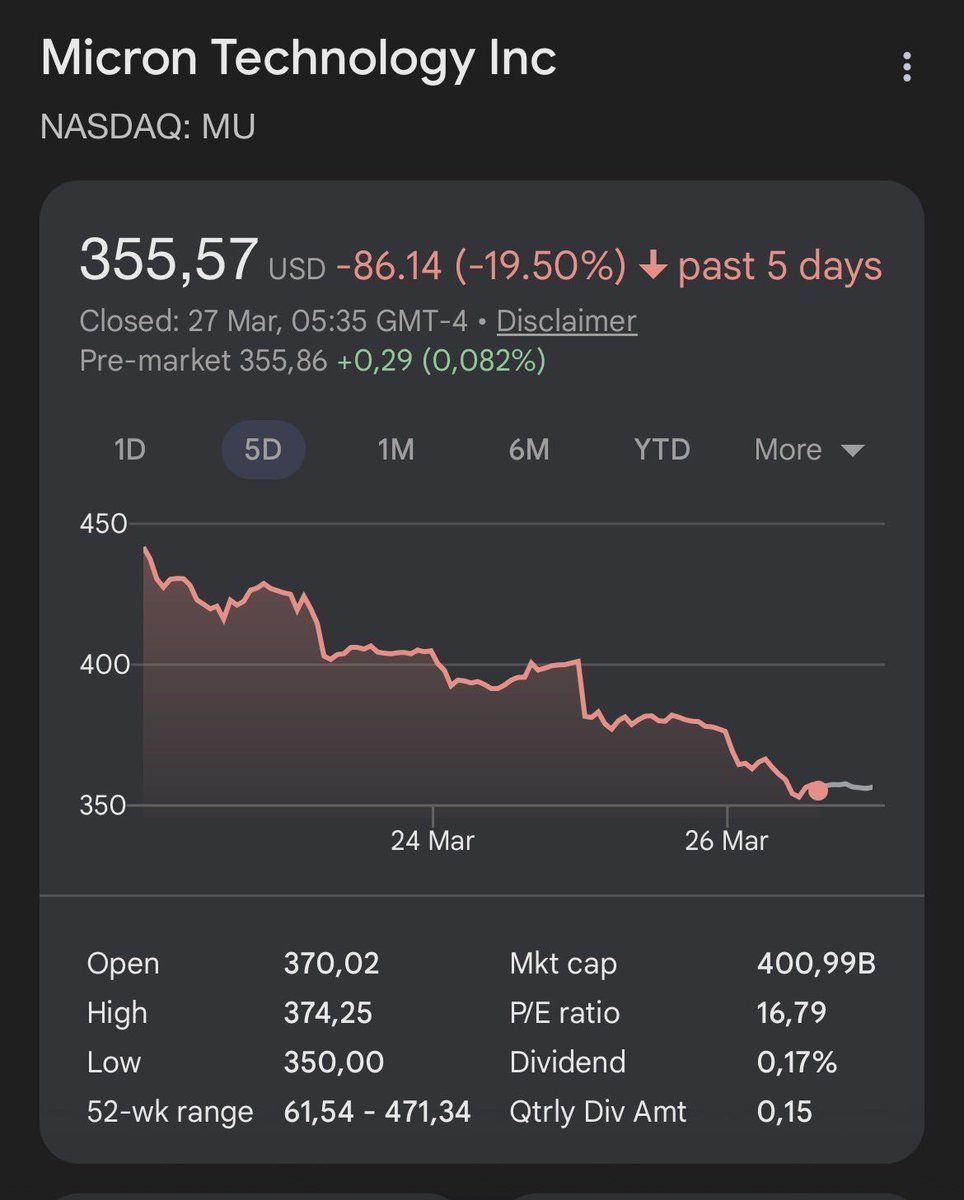
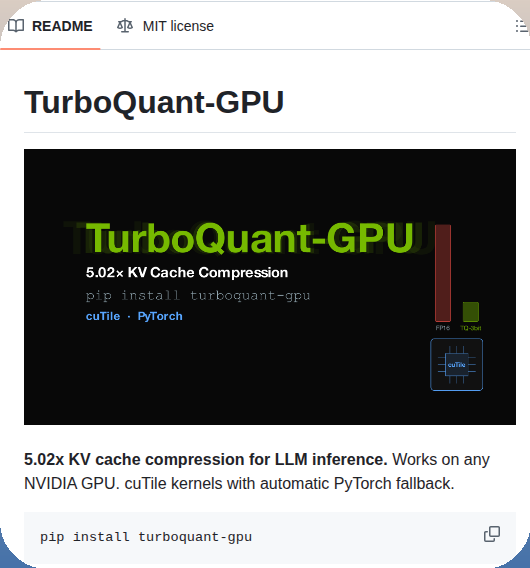
@michalmajzlik @tom_doerr not the same turboquant variant but check out my test results and local setup scripts github.com/jamesarslan/lo…
English
James Arslan
56 posts
@JamesArslanSwe
CTO of https://t.co/dolKx2UPD9 instagram @jamesarslanswe






So we know Gemma 4 is good at tool calling, but what about web coding? I threw 4 UI screenshots at three Gemma 4 models and said rebuild this, one shot, no hand-holding, just image in, code out. Model lineup: - E4B - 26B A4B (MoE) - 31B Dense (skipped the E2B this round) Let me know which one you think cooked the hardest



Meet Gemma 4: our new family of open models you can run on your own hardware. Built for advanced reasoning and agentic workflows, we’re releasing them under an Apache 2.0 license. Here’s what’s new 🧵


Excited to launch Gemma 4: the best open models in the world for their respective sizes. Available in 4 sizes that can be fine-tuned for your specific task: 31B dense for great raw performance, 26B MoE for low latency, and effective 2B & 4B for edge device use - happy building!



🚨 SON DAKİKA : Google TurboQuant’ı neden önemli? AI çalışabilmesi için kelimeler arasındaki ilişkiyi anlamak yani vektör hesaplamaları için karmaşık pusulalar kullanıyordu artık üstüne sadece yukarı veya aşağı anlamına gelen basit etiketlerle de yön bulabilmeye başladı. Bu basit bir bilgisayarlarda kendi kodlarınızı yazdırabileceğiniz anlamına geliyor hatta ai için donanım sınırlarının ortadan kalması artık çok daha fazla yatırıma ihtiyaç olmayacağı ve hatta ai araçlarının ucuzlayacağı anlamına geliyor!

🚀 Qwen3.5-Omni is here! Scaling up to a native omni-modal AGI. Meet the next generation of Qwen, designed for native text, image, audio, and video understanding, with major advances in both intelligence and real-time interaction. A standout feature: 'Audio-Visual Vibe Coding'. Describe your vision to the camera, and Qwen3.5-Omni-Plus instantly builds a functional website or game for you. Offline Highlights: 🎬 Script-Level Captioning: Generate detailed video scripts with timestamps, scene cuts & speaker mapping. 🏆 SOTA Performance: Outperform Gemini-3.1 Pro in audio and matches its audio-visual understanding. 🧠 Massive Capacity: Natively handle up to 10h of audio or 400s of 720p video, trained on 100M+ hours of data. 🌍 Global Reach: Recognize 113 languages (speech) & speaks 36. Real-time Features: 🎙️ Fine-Grained Voice Control: Adjust emotion, pace, and volume in real-time. 🔍 Built-in Web Search & complex function calling. 👤 Voice Cloning: Customize your AI's voice from a short sample, with engineering rollout coming soon. 💬 Human-like Conversation: Smart turn-taking that understands real intent and ignores noise. The Qwen3.5-Omni family includes Plus, Flash, and Light variants. Try it out: Blog: qwen.ai/blog?id=qwen3.… Realtime Interaction: click the VoiceChat/VideoChat button (bottom-right): chat.qwen.ai HF-Demo: huggingface.co/spaces/Qwen/Qw… HF-VoiceOnline-Demo: huggingface.co/spaces/Qwen/Qw… API-Offline: alibabacloud.com/help/en/model-… API-Realtime: alibabacloud.com/help/en/model-…