Sabitlenmiş Tweet

LocalAI ( @LocalAI_API ) 4.2.0 is out, just few numbers and facts:
- +392 commits ( we squash these 😄 )
- +11 Backends: voice and face recognition, vibevoice.cpp (from me), LocalQVE from @jichiep and among @sgl_project , @__tinygrad__ , @no_stp_on_snek 's Turboquant, ik_llama.cpp, sam.cpp from @el_PA_B
- Many new QoL improvements, increased sglang and VLLM support and hardening on distributed mode
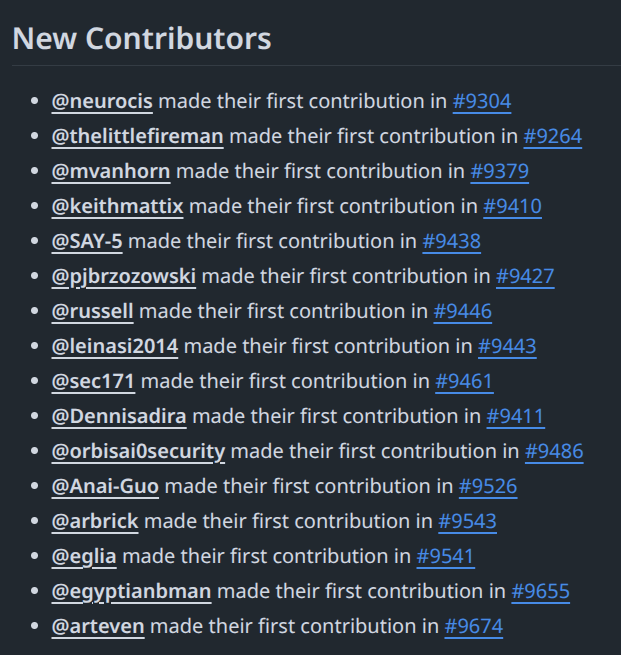
- 16+ new contributors ! Thanks to the community!
LocalAI is all about give you flexibility to run the latest from the community, and ds4 support from @antirez is on its way!
This is the year of Local AI!

English














