Jan Hasenauer retweetledi

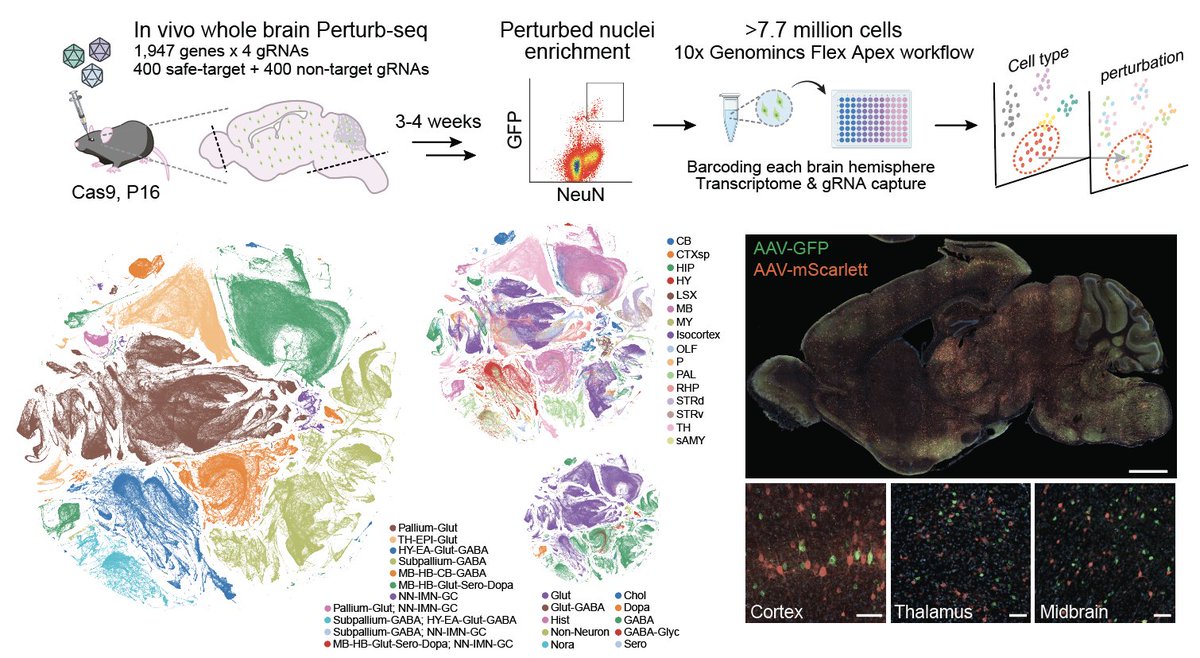
📢 Preprint: we present a whole-mouse-brain in vivo Perturb-seq atlas, 7.7 million cells, 1947 disease-associated perturbations, moving toward direct readout of how human genetics rewires cell states & circuits in vivo. Grateful for the Team! @NVIDIAHealth biorxiv.org/content/10.648…
English