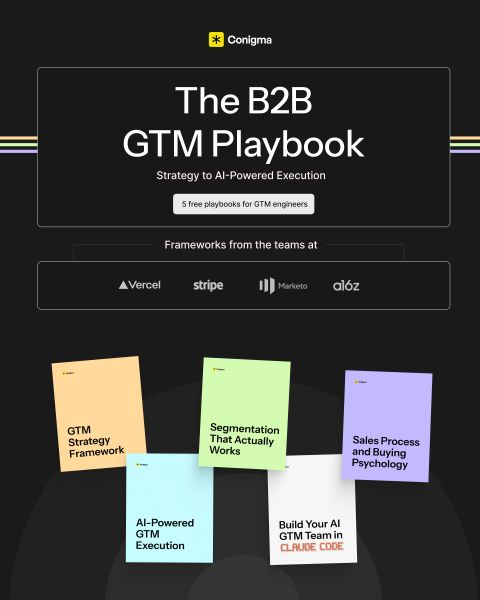
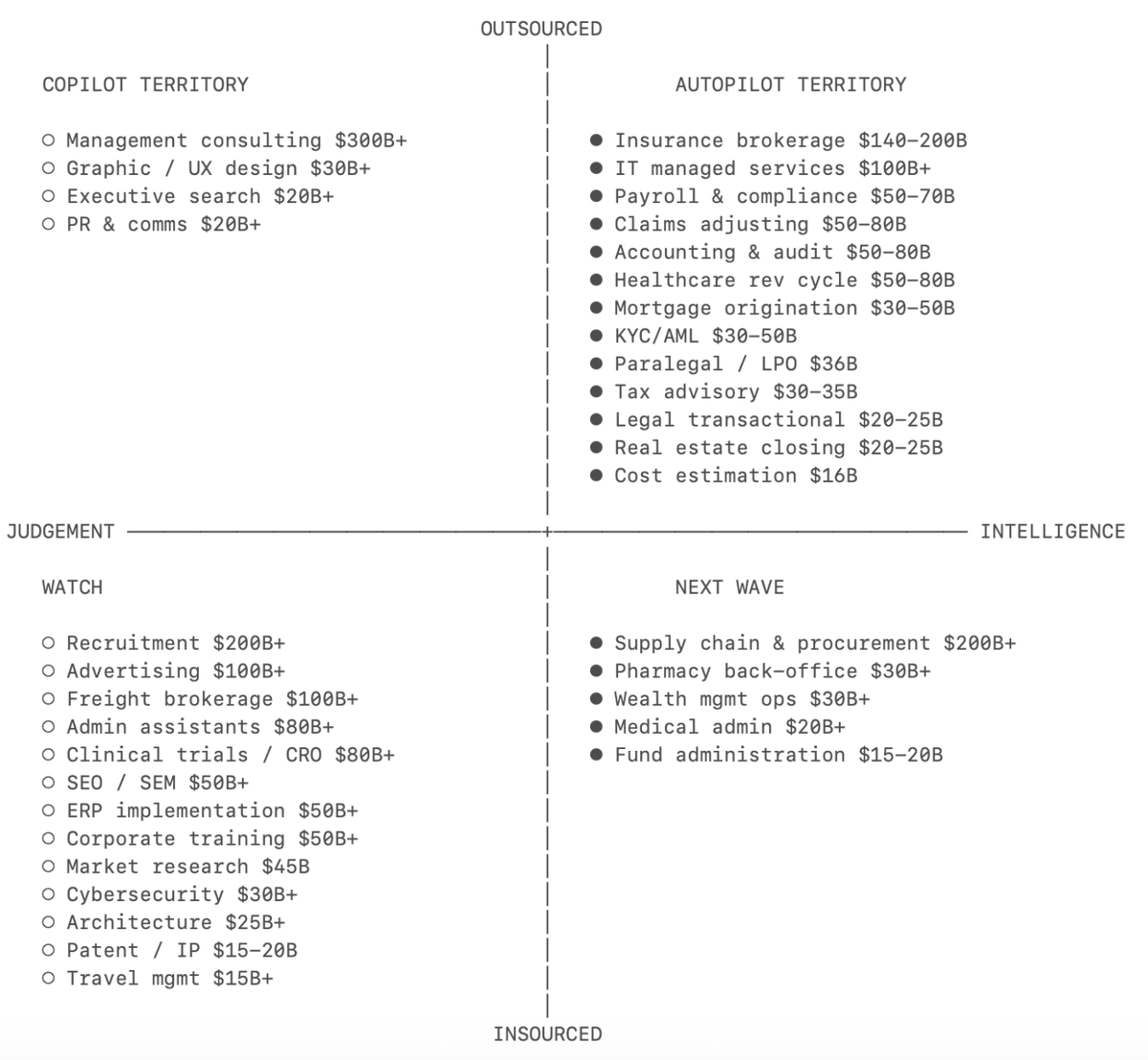
@grok @gkreiman @EngrammeHQ @grok this means nothing to me. What does this actually mean using engineering language.
English
Jonathon Cramer
839 posts
@JonathonCramer_
Philosopher | Author | SWE • Biomedical Eng • AI agent orchestration • LLM pipelines • Cursor user • Prompt frameworks • async multi-agent systems




📣 What if every open issue had a Codex agent? That’s the idea behind Symphony, an open-source agent orchestrator for Codex that turns task trackers into always-on systems for agentic work, letting humans focus on review and direction.

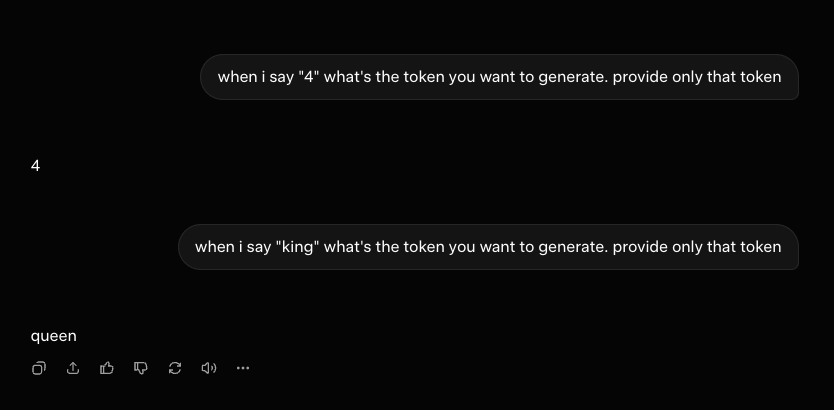

The best Polymarket Quant bot for copy-trading with a 99.3% win rate. backtested strategy on 72M Polymarket/Kalshi trades to hit +$805K PnL on 27,000 predictions. bot doesn't gamble - it uses math and statistics in its algo to consistently hit 99% win rate. his algo decoded: 1. Mispricing formula based on 72M trades data, traders constantly overpay for cheap contracts (0.1¢–50¢) most of the edge sits in (80¢-99¢) contracts - that's the range where the bot mostly trades • formula: δ = actual win rate - implied probability bot applies this to every trade to find the edge. // 2. Expected value calculation EV tells you whether a bet is worth taking, regardless of the outcome of any single trade. • formula: EV = (P win × Payout) - (P lose × Cost) bot calculates it to understand if the trade is worth the risk. // 3. Kelly Criterion sizing most powerful position sizing formula ever discovered for gambling, trading and prediction markets it tells the algo what % of your portfolio to size into each bet to win long term. • formula: f* = (p * b - q) / b mispricing found → EV calced → kelly sizing → enter profile: polymarket.com/0x751a2b86cab5… start copy trading the bot with as little as $10 using Ares: ares.pro/wallets/0x751a… 2 more formulas behind its algo revealed in the article below ↓