Joseph Jeesung Suh retweetledi

🎉 Thrilled to have two papers accepted to ACL 2026 main!
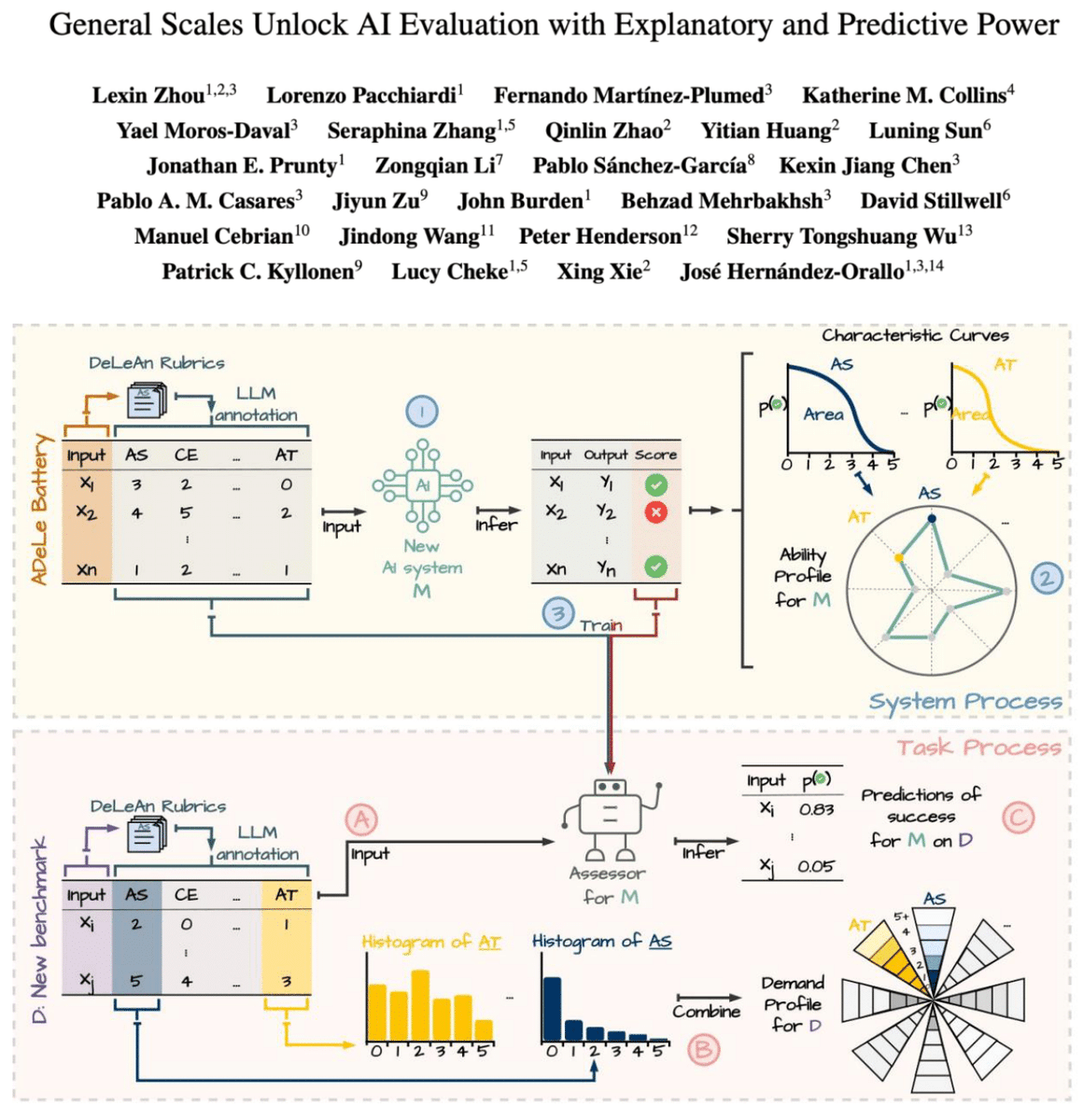
1. Graph-based models match LLMs on close-ended human simulation tasks with far less compute & greater transparency
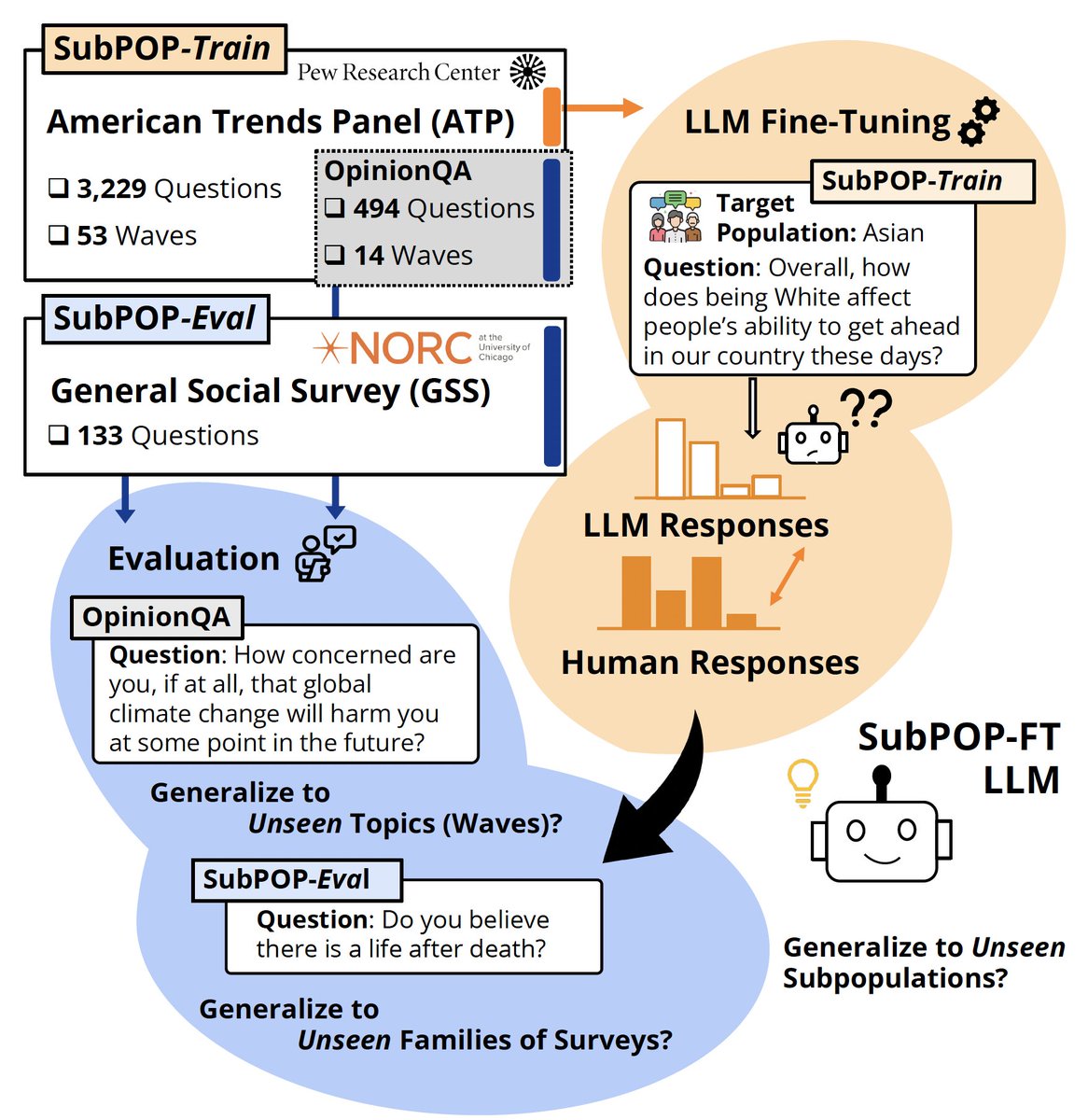
2. (oral) How to allocate human samples towards fine-tuning vs post-hoc rectification in simulation


English