Sabitlenmiş Tweet

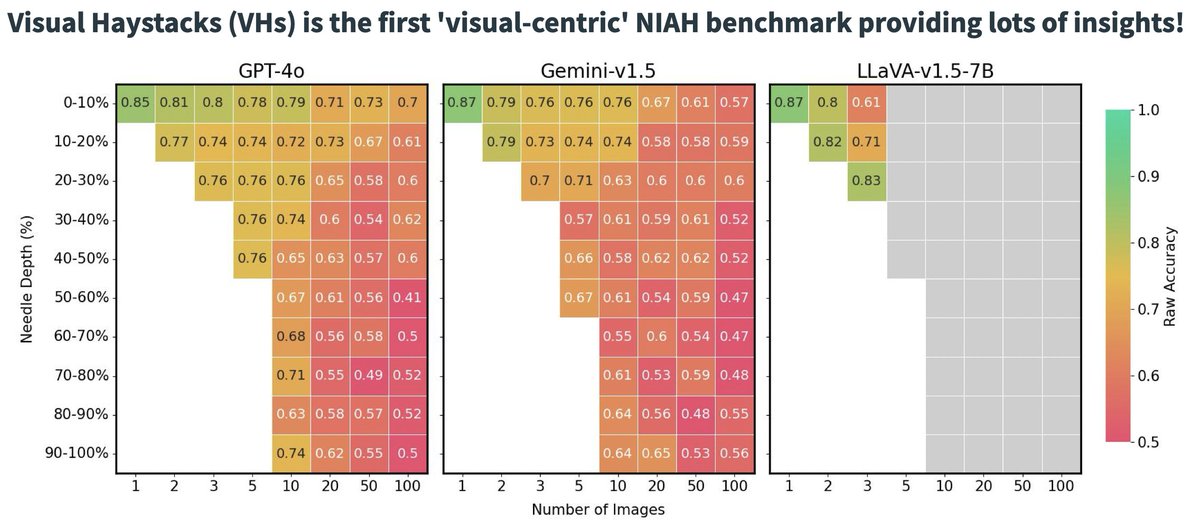
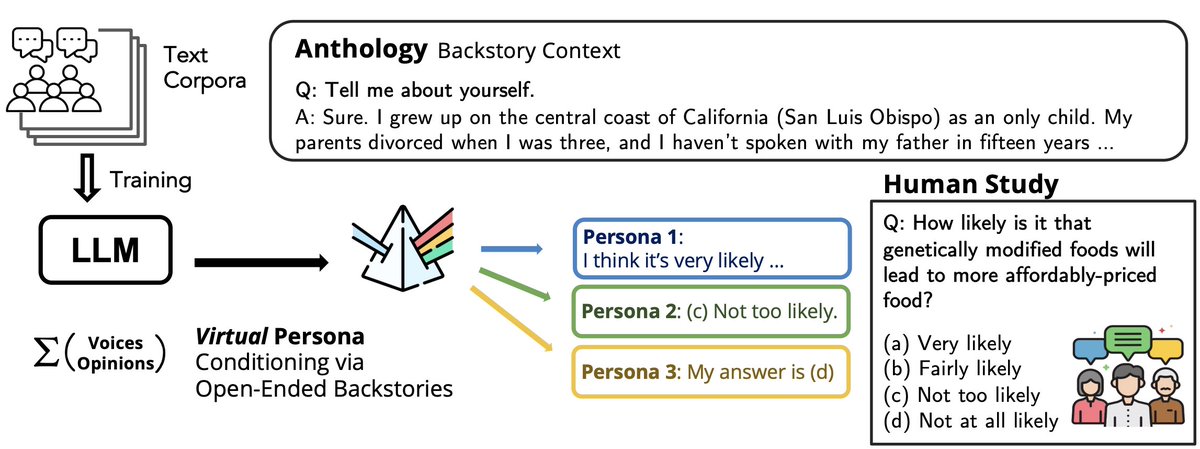
Rich backstories enable deeper persona binding. LLMs conditioned with the backstories go beyond predicting human opinions to simulating how people perceive others and are perceived in return.
Minwoo (Josh) Kang@joshminwookang
🤔 Do LLMs exhibit in-group↔out-group perceptions like us? ❓ Can they serve as faithful virtual subjects of human political partisans? Excited to share our paper on taking LLM virtual personas to the *next level* of depth! 🔗 arxiv.org/abs/2504.11673 🧵
English