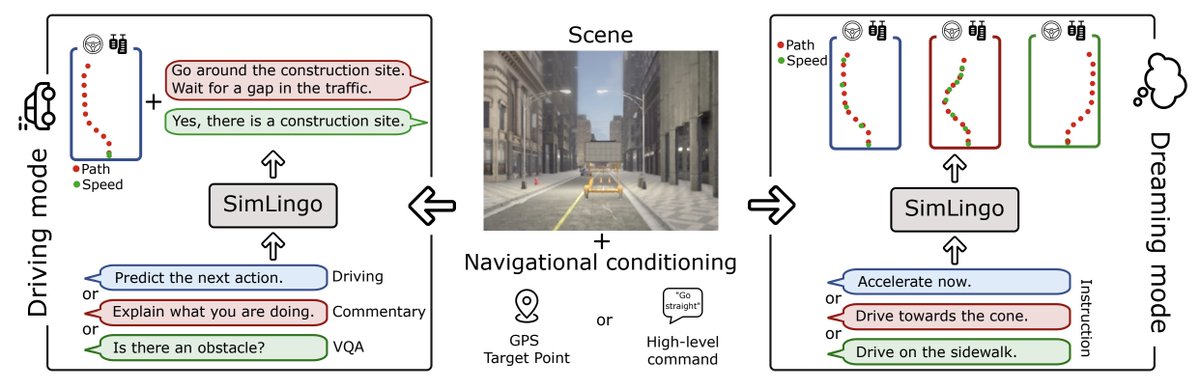
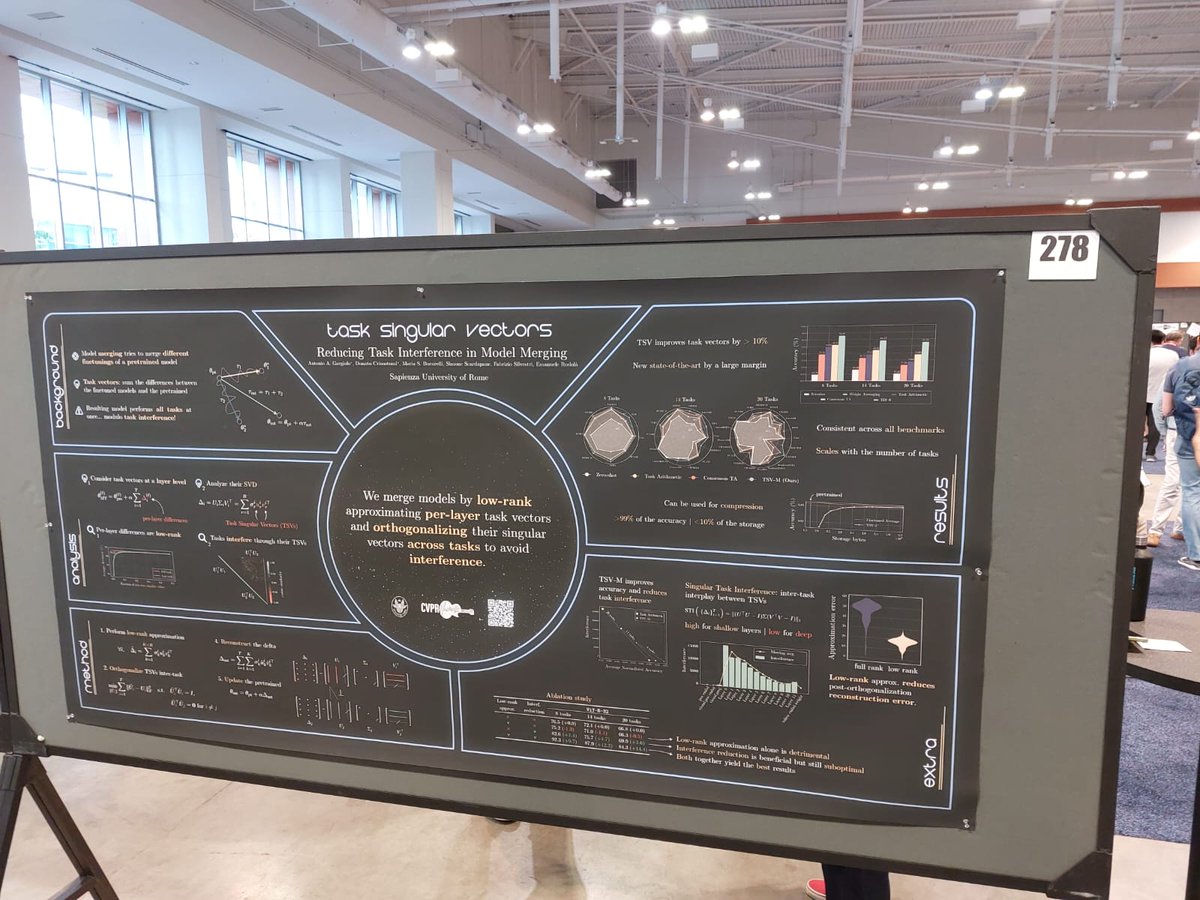
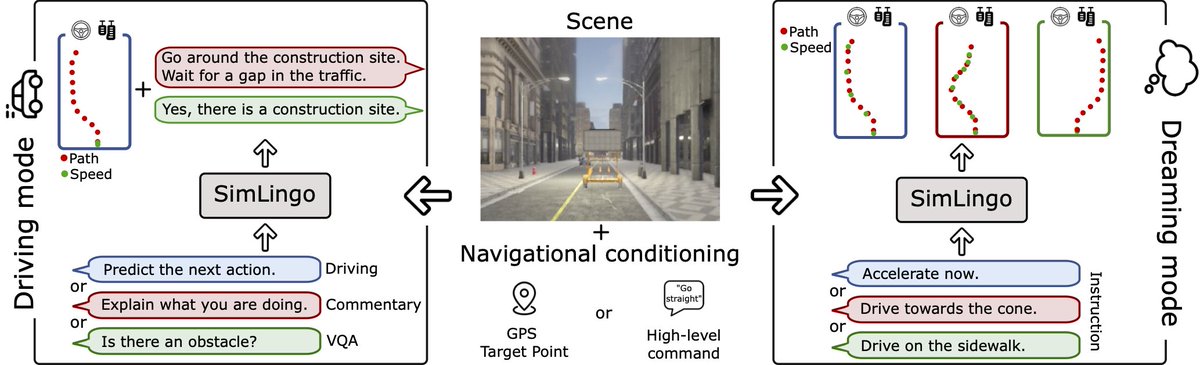
Katrin Renz retweetledi

The most important AI research center in Europe isn’t in London, Paris, or Berlin. It’s in a university town of 90,000 people you’ve probably never heard of.
Tübingen, in southwestern Germany, is home to Cyber Valley - an AI consortium set up in 2016 with €165M from the state of Baden-Württemberg, the Max Planck Society, and partners including Bosch, Mercedes-Benz, and Amazon. The region publishes more machine learning and computer vision research to top conferences than anywhere else in Europe. Aleph Alpha came out of here.
With @FastCodeAI Labs now registered in Baden-Württemberg, we’re applying to join the Cyber Valley Startup Network.
Thanks to Paul-David at Cyber Valley for the time.

English