Kayro
506 posts


Kayro
@KayroTheWagon
22 | 🇩🇪/🇬🇧 | Car enthusiast | Tech tinkerer | Will out-optimize your smart fridge | FPV Pilot












We're excited to partner with Google to offer Grounding With Exa inside of Gemini models! Using Exa's agent-first search, Gemini models can now access billions of websites, technical docs, papers, people, companies, and more. 10^18🤝10^100


WWDC17 - June 5, 2017 The very first time John Ternus appeared onstage as a presenter, he talked about the Mac.🖥️ He introduced the iMac Pro!!! "One of the first things you will notice is that it comes in this seriously badass Space Grey finish" 😎







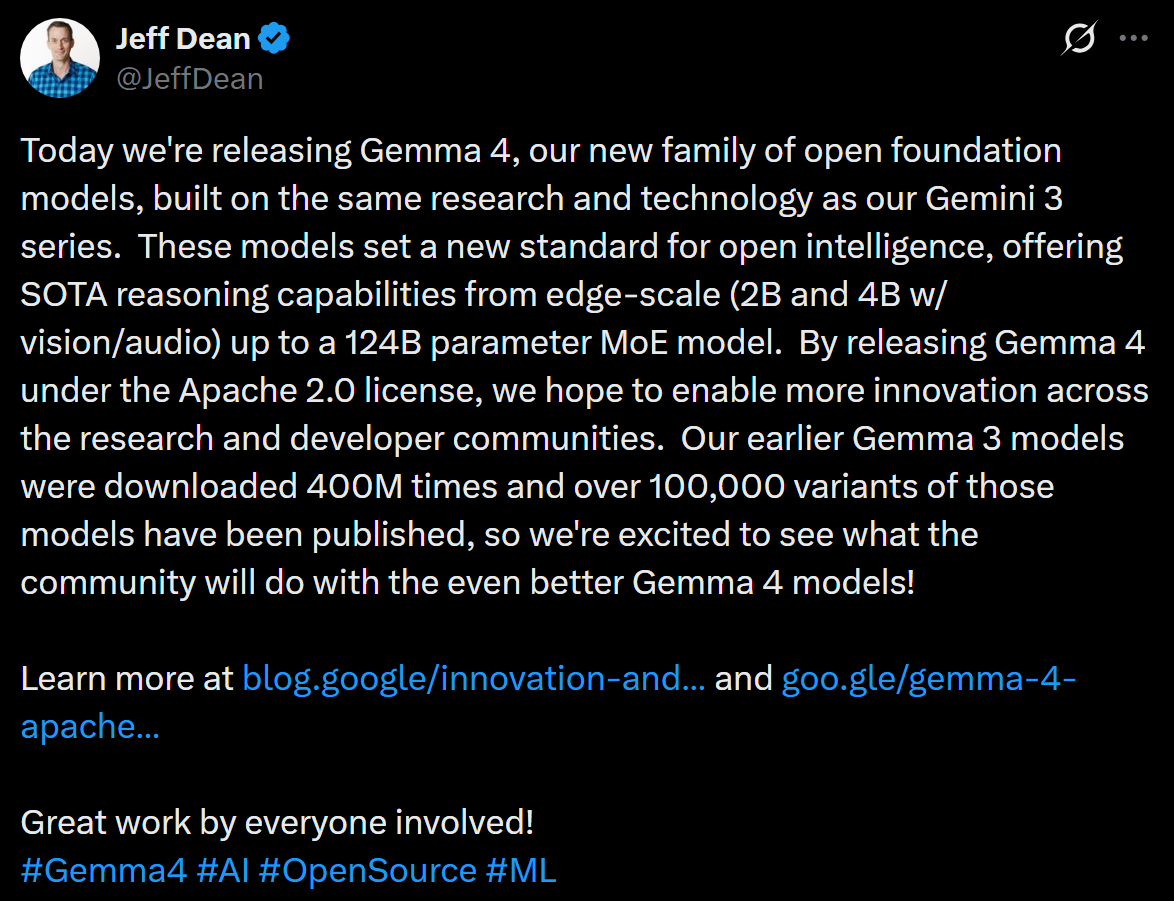


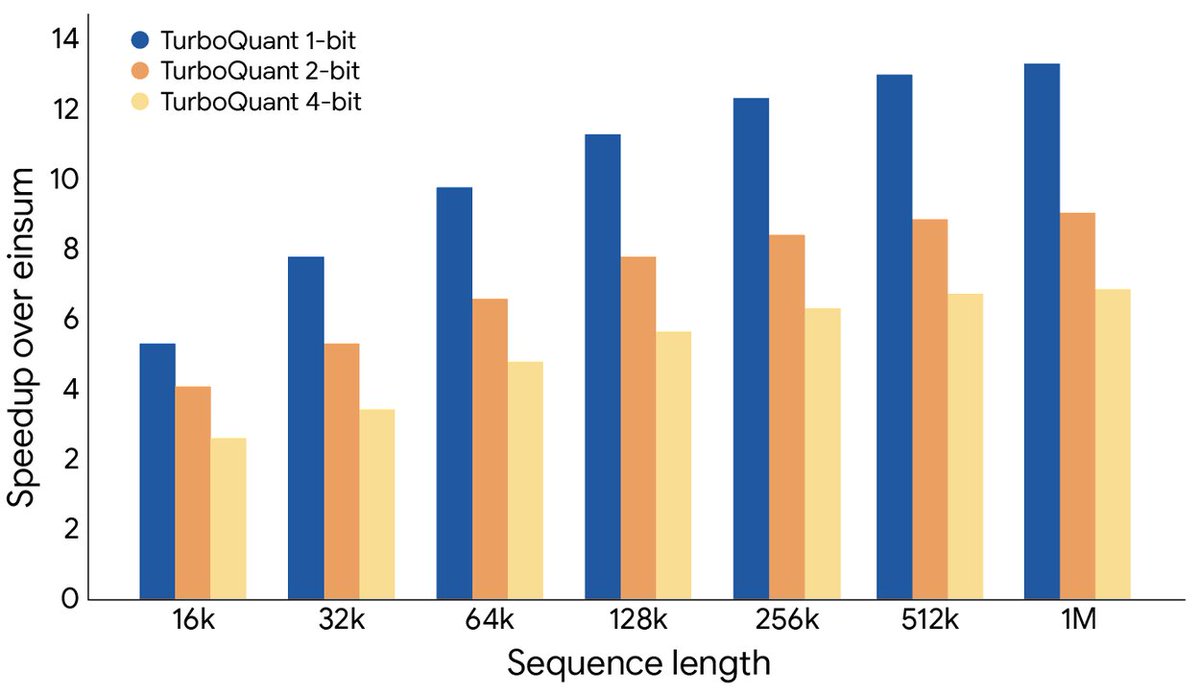

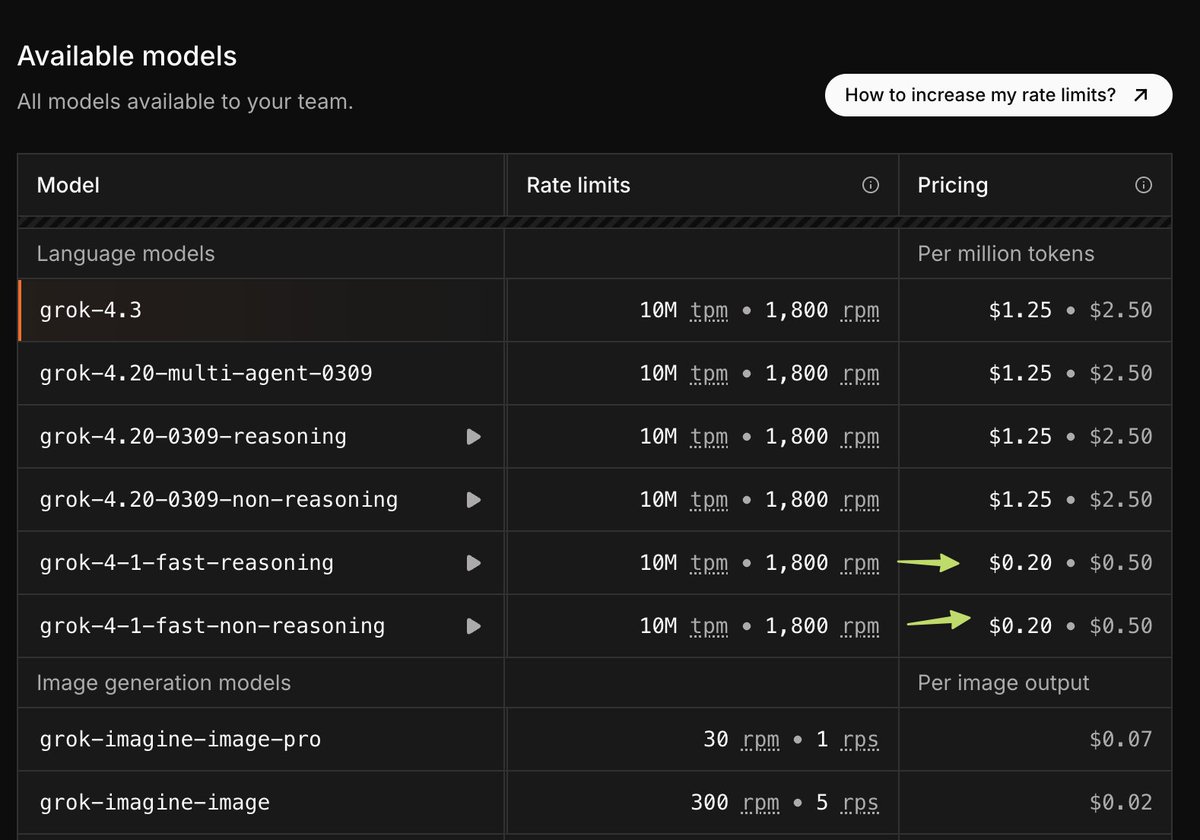
Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: goo.gle/4bsq2qI