Sabitlenmiş Tweet

Very cool to work on a project with the Seahawks that's helping 74% more fans get through stores during events, and doubling sales. forbes.com/sites/timnewco…
English
Kellen Sunderland
4.3K posts

@KellenDB
🇨🇦✈️🇩🇪🚵♂️🇺🇲 - Amazon Go








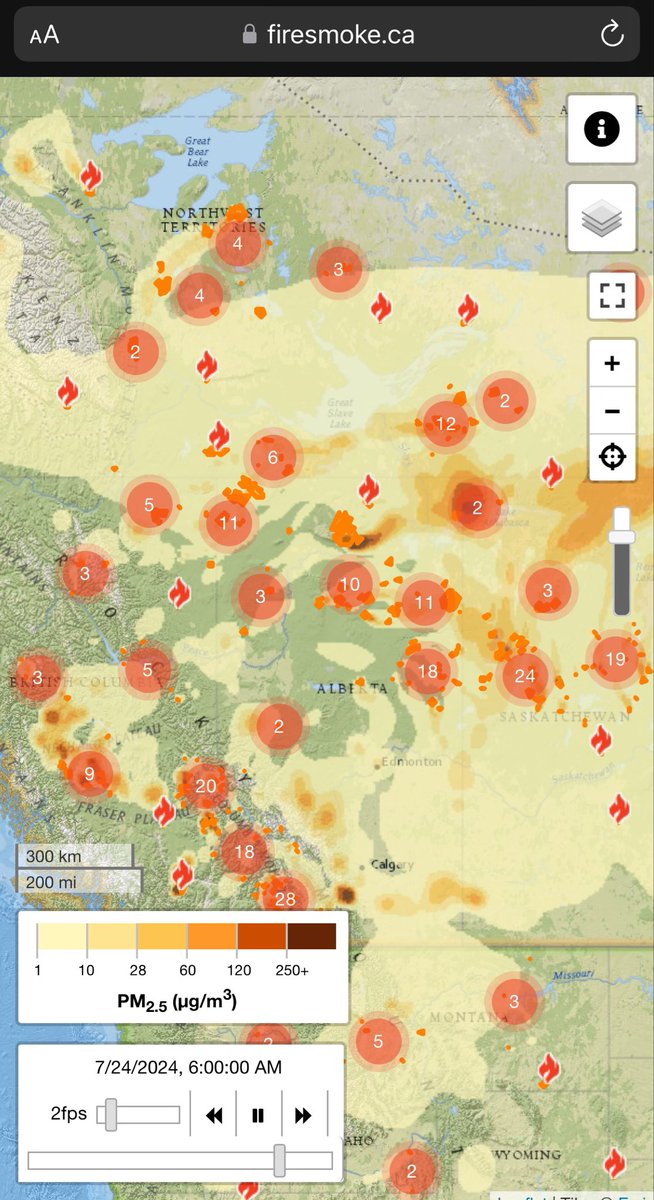
The fires in Jasper should hold a lessen to decision makers about public policy, effective leadership and the role of science when there is controversy, writes Gary G. Mar. theglobeandmail.com/opinion/articl…




This is an Alberta Emergency Alert. The Municipality of Jasper has issued a Wildfire alert. This alert is in effect for everyone located in Jasper. There is a wildfire south of town. An Evacuation Order has been issued for the Town of Jasper. Everyone in Jasper must evacuate now. Use Highway 16 towards British Columbia. Follow directions from local authorities. Bring identification, important documents, medication, pets and your emergency kit with you. We will publish more information about assembly points soon. Check the Municipality of Jasper and Jasper National Park's Facebook page and website for more information. alberta.ca/alberta-emerge… #ABemerg #ABfire
We have received reports of continued disruptions and unacceptable customer service conditions at Delta Air Lines, including hundreds of complaints filed with @USDOT. I have made clear to Delta that we will hold them to all applicable passenger protections.

Meta releases VGGSfM Visual Geometry Grounded Deep Structure From Motion Structure-from-motion (SfM) is a long-standing problem in the computer vision community, which aims to reconstruct the camera poses and 3D structure of a scene from a set of unconstrained 2D images. Classical frameworks solve this problem in an incremental manner by detecting and matching keypoints, registering images, triangulating 3D points, and conducting bundle adjustment. Recent research efforts have predominantly revolved around harnessing the power of deep learning techniques to enhance specific elements (e.g., keypoint matching), but are still based on the original, non-differentiable pipeline. Instead, we propose a new deep SfM pipeline VGGSfM, where each component is fully differentiable and thus can be trained in an end-to-end manner. To this end, we introduce new mechanisms and simplifications. First, we build on recent advances in deep 2D point tracking to extract reliable pixel-accurate tracks, which eliminates the need for chaining pairwise matches. Furthermore, we recover all cameras simultaneously based on the image and track features instead of gradually registering cameras. Finally, we optimise the cameras and triangulate 3D points via a differentiable bundle adjustment layer. We attain state-of-the-art performance on three popular datasets, CO3D, IMC Phototourism, and ETH3D.