Sabitlenmiş Tweet

Do we really need pixel generation to model motion? 🤔
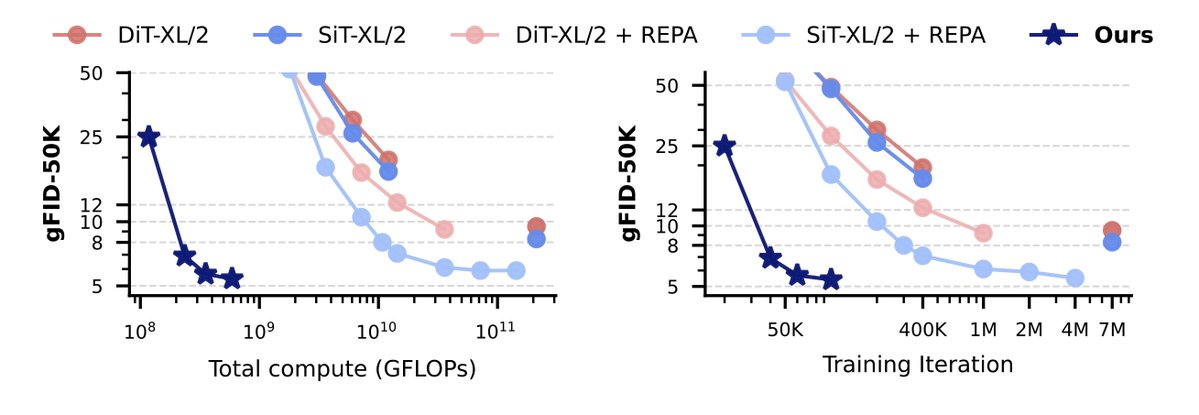
We show how directly representing motion in a compact space enables efficient, scalable planning.
10,000× faster than video models, enabling planning and reasoning in open-world and robotics settings.
Check it out ⬇️
Nick Stracke@rmsnorm
Video diffusion models learn motion indirectly through pixels. But motion itself is much lower-dimensional. We introduce 64× temporally compressed motion embeddings that directly capture scene dynamics. This enables efficient planning -> 10,000× faster than video models. 🧵👇
English