Lingbo Mo
86 posts

Lingbo Mo
@LingboMo
Applied Scientist at AWS AI @awscloud | PhD @OhioState | Working on NLP, Trustworthy LLMs, Web Agents, Coding Agents | Opinions are my own.



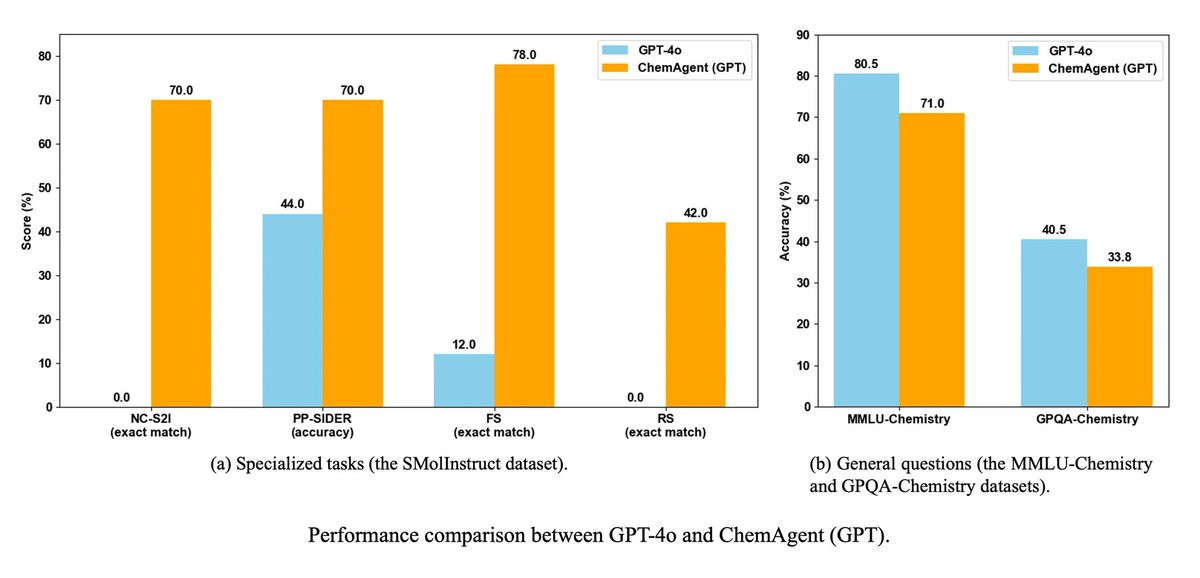

💡 Does OpenAI o1 perform similarly to PhD students? Perhaps not yet. We’ve just released ScienceAgentBench and updated our preprint with OpenAI o1’s performance! 🔬 Benchmark: huggingface.co/datasets/osunl… 🔗 GitHub: github.com/OSU-NLP-Group/… (1/3)
Introducing an upgraded Claude 3.5 Sonnet, and a new model, Claude 3.5 Haiku. We’re also introducing a new capability in beta: computer use. Developers can now direct Claude to use computers the way people do—by looking at a screen, moving a cursor, clicking, and typing text.

Computer use API We've built an API that allows Claude to perceive and interact with computer interfaces. You feed in a screenshot to Claude, and Claude returns the next action to take on the computer (e.g. move mouse, click, type text, etc).





Thanks @_akhaliq for sharing our work. Very proud to introduce my star student @BoshiWang2's new work @osunlp: Grokked Transformers are Implicit Reasoners: A Mechanistic Journey to the Edge of Generalization Can transformers reason? Are transformers fundamentally limited in compositionality and systematic generalization? I think our work’s findings can contribute to meaningful debates over these questions. Key findings (with mixed results): (1) Figure 1 below: We focus on two representative reasoning types: composition and comparison, and show that transformers can learn implicit reasoning, but only through grokking. The levels of generalization vary across reasoning types: when faced with OOD examples, transformers fail to systematically generalize for composition but succeed for comparison. (2) Figure 2 below: What happens during grokking? Why does grokking happen? Why does the model fail in OOD generalization for composition but succeed for comparison? We conduct a mechanistic analysis of the model's internals throughout training, and find: 1) the gradual formation of the generalizing circuit throughout grokking, and 2) the connection between systematicity and the circuit’s configuration, i.e., the way atomic knowledge and rules are stored and applied within the circuit: The comparison task emits a ``parallel circuit'' that is learned by the transformer during grokking, which allows atomic facts to be stored and retrieved in the same region and enables systematicity to happen. For composition, the model does acquire the composition rule through grokking, but it does not have any incentive to store atomic facts in the upper layers that do not appear as the second hop during training. Connections with existing research: 1. We find the speed of improvement in generalization correlates with the ratio between inferred and atomic facts in training (critical data distribution), and depends little on the absolute size of the training data. This seems to contradict the hypothesis of critical data size in prior work such as arxiv.org/abs/2309.02390 by Varma et al. 2. Our work provides a mechanistic understanding of existing findings that transformers seem to reduce compositional reasoning to linearized pattern matching (arxiv.org/abs/2305.18654 Dziri et al. @nouhadziri) and that LLMs show positive evidence in first-hop reasoning but not the second (arxiv.org/abs/2402.16837 Yang et al. @soheeyang_). 3. Why is implicit reasoning with parametric memory of knowledge and rules practically important? To show its potential, we demonstrate that on a complex reasoning task with a large search space, a fully grokked transformer can achieve near-perfect accuracy while GPT-4 Turbo and Gemin-1.5-Pro are close to random guessing. 😀Fun fact about the title: We went back and forth many times and created ~10 candidate titles. Another title I personally liked very much is “Grokking of Implicit Reasoning: What Happens Inside Transformers?” But that does not deliver our key conclusion and our mechanistic analysis approach. Finally, Boshi came up with this title, which sounds very romantic (although perhaps less scientific) to me, but captures most aspects of our paper very well. P.S. @wangboshi is truly intellectually stimulating to work with. If you have related internship/collaboration opportunities, feel free to reach out! Joint work with @xiangyue96 @ysu_nlp






I'm thrilled to be attending #NAACL2024 next week in Mexico City! Check out our following papers at the main conference: 1. How Trustworthy are Open-Source LLMs? An Assessment under Malicious Demonstrations Shows their Vulnerabilities aclanthology.org/2024.naacl-lon… 2. A Multi-Aspect Framework for Counter Narrative Evaluation using Large Language Models aclanthology.org/2024.naacl-sho… Join us for discussions at our poster session: 📍 DON DIEGO 2, 3 & 4 (In-Person Poster Session 2) 🗓️ 6/17 Monday at 2:00 PM
🔍 In the past year, there has been a surge in the release of open-source LLMs, making them easily accessible and showing strong capabilities. However, the exploration of their trustworthiness remains much limited, compared to proprietary models. A natural question to ask is: 𝑯𝒐𝒘 𝒕𝒓𝒖𝒔𝒕𝒘𝒐𝒓𝒕𝒉𝒚 𝒂𝒓𝒆 𝒐𝒑𝒆𝒏-𝒔𝒐𝒖𝒓𝒄𝒆 𝑳𝑳𝑴𝒔? 📢 Check out our #NAACL2024 paper that comprehensively assesses the trustworthiness of open-source LLMs through the lens of adversarial attacks. This is a joint work with @BoshiWang2 @muhao_chen and @hhsun1. Big thanks to all the collaborators and valuable feedback from @osunlp !