
ank R
4 posts

ank R retweetledi

Open-ended coding training data may no longer be the bottleneck: AI can scale open-ended tasks—and even outperform human-expert curation.
FrontierCS team is releasing FrontierSmith: a system for synthesizing open-ended coding problems at scale. Starting from closed-ended coding tasks, FrontierSmith mutates, filters, and builds runnable optimization environments for long-horizon coding agents. In our experiments, FrontierSmith data trains stronger models than human-curated open-ended data on FrontierCS and ALE-bench.
Blog: frontier-cs.org/blog/frontiers…
Paper: arxiv.org/abs/2605.14445
Code: github.com/FrontierCS/Fro…
Model: huggingface.co/runyuanhe/qwen…
English
ank R retweetledi

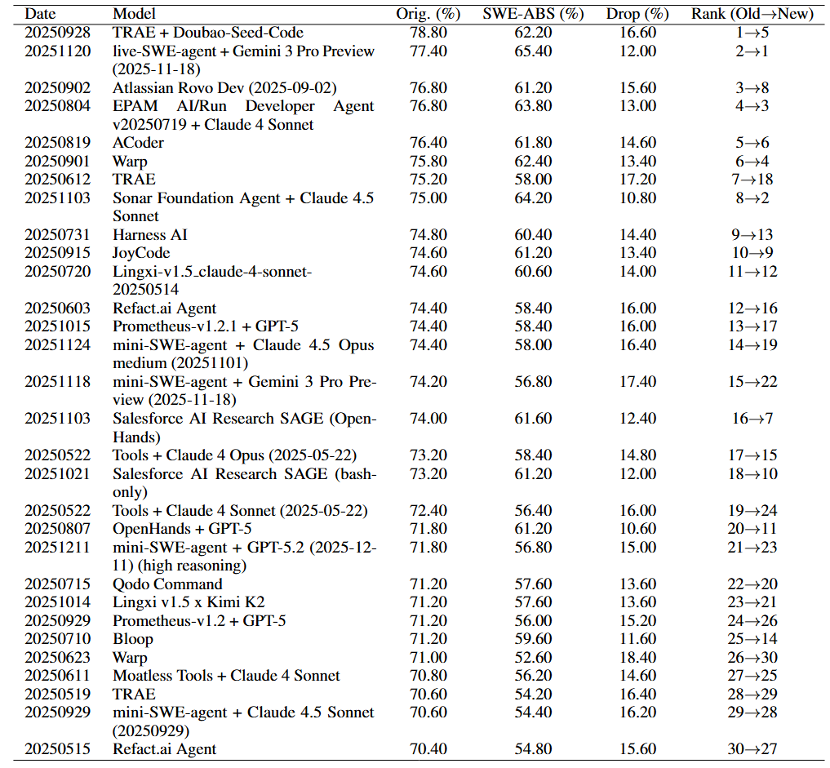
🔥 SWE-ABS accepted by ICML2026 @icmlconf 🔥
OpenAI @OpenAI showed SWE-Bench @SWEbench tests reject correct patches.
We reveal the other side: they also accept wrong ones.
SWE-ABS strengthens SWE-Bench (Verified & Pro) via:
coverage-driven tests + mutation-based attacks.
Key results:
• All top-30 rankings shift (#1 → #5)
• 19.78% “solved” patches are actually wrong
• 50.2% Verified strengthened
• 64.7% Pro subset strengthened
👉 Test quality—not benchmark difficulty—is the real bottleneck.
Links 👇
English