Boxi Yu
703 posts

Boxi Yu
@BoshCavendish
I love building coding agents and exploring how AI and software engineering can improve each other.



People at major AI labs (using internal models) 3-4 months ahead of startup silicon valley engineers SV founders/eng 3-6 months ahead of NY NY founders/eng 6-12 months ahead of rest of world Most people have no idea how fast AI shifting as 1-2 years behind SOTA "The future is here, just not equally distributed" - Robert Heinlein

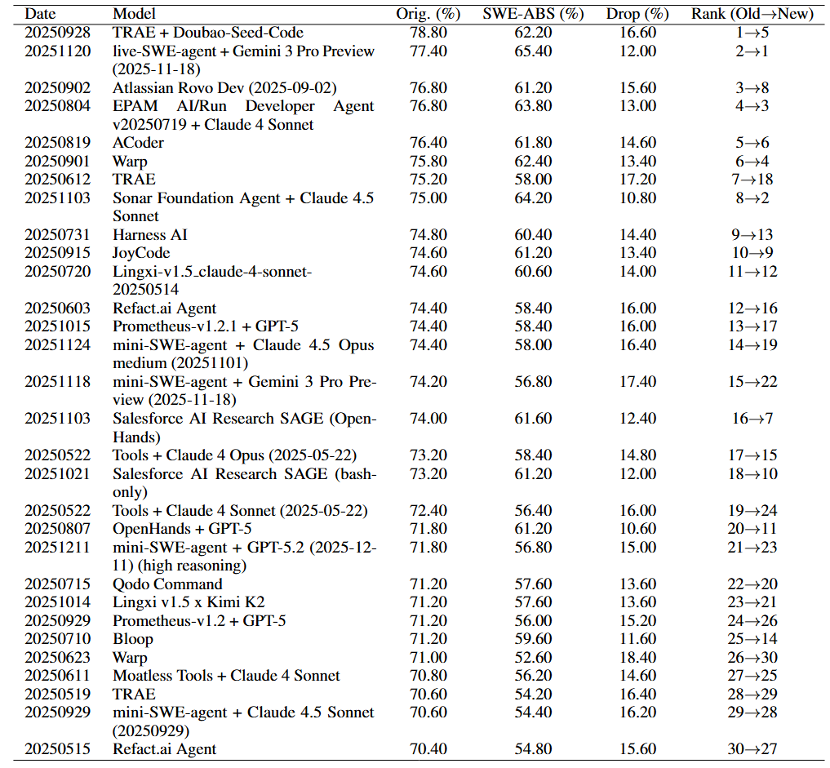
🔥 SWE-ABS accepted by ICML2026 @icmlconf 🔥 OpenAI @OpenAI showed SWE-Bench @SWEbench tests reject correct patches. We reveal the other side: they also accept wrong ones. SWE-ABS strengthens SWE-Bench (Verified & Pro) via: coverage-driven tests + mutation-based attacks. Key results: • All top-30 rankings shift (#1 → #5) • 19.78% “solved” patches are actually wrong • 50.2% Verified strengthened • 64.7% Pro subset strengthened 👉 Test quality—not benchmark difficulty—is the real bottleneck. Links 👇


















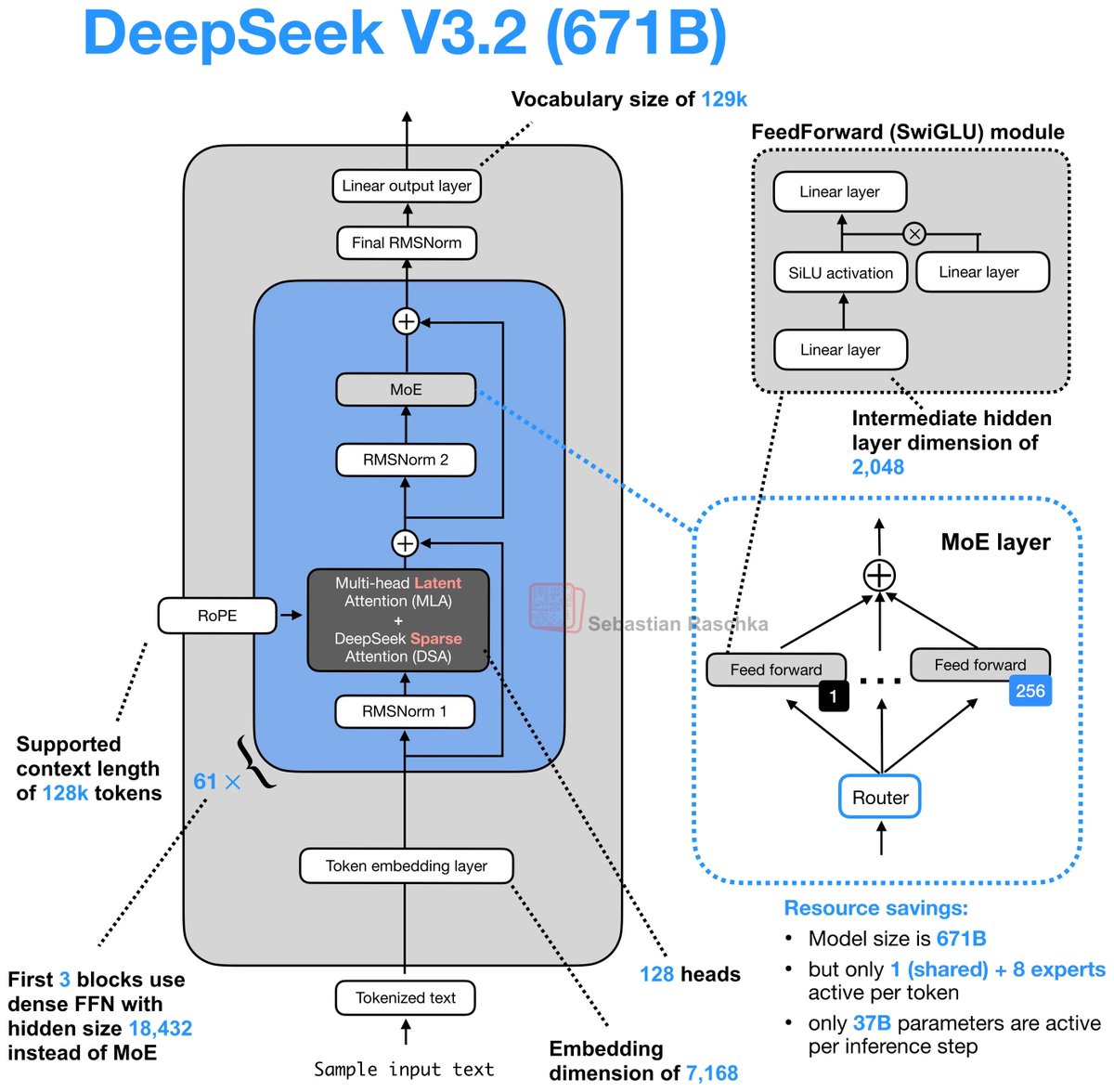


Day 82/365 of GPU Programming Taking a closer look at Mixture of Experts today, so I can write better MoE kernels. Specifically, to optimize an MXFP4 MoE fused kernel for the GPU Mode challenge. I haven't had much prior exposure to MoEs, so lots of new concepts I learned today. Luckily I found the best intro to MoEs thanks to @MaartenGr visual overview of the topic. I then watched @tatsu_hashimoto's amazing Stanford CS336 lecture on MoEs, which added deeper context around why MoEs are gaining popularity, FLOPs, OLMoE, infra complexity, routing functions (mindblown this works so well...), expert sizes, training objectives, top k routing and DeepSeek variations. Once I had a basic understanding I started playing around with the some AITER kernels but progress there is tbd. Also had a nice chat with @juscallmevyom (who was kind enough to reach out!) about the AMD kernels and the challenge of materialization overhead.