Louis Béthune retweetledi

Autoregressive models dominate, but what if we treat multimodal generation as discrete order agnostic iterative refinement? Excited to share our systematic study on the design space of Tri-Modal Masked Diffusion Models (MDMs). We pre-trained the first Tri-Modal MDM from scratch on (text,), (image, text), and (audio, text). The same model can do ASR, TTS, T2I, captioning and native text generation.
What I'm the most proud of in this work is the scientific rigor. Over 3,500 training runs. Principled hyperparameter transfer. Honest results. Carefully controlled ablations across multiple different axis of entanglement.
A thread on our empirical findings (arXiV: arxiv.org/abs/2602.21472)
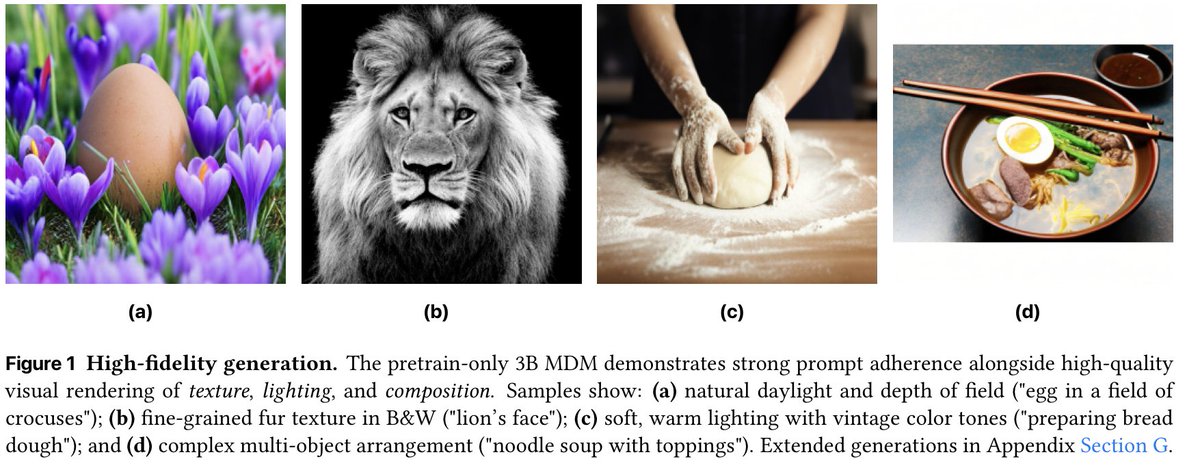
English