Luke Dz
300 posts


Luke Dz
@LukeDz8
AI/ML SPC Founder Fellow - networking saas: https://t.co/RDwgTpj5Yn, https://t.co/wUIAYt462x, https://t.co/SdGpVTvdFG



Over the past month, some of you reported Claude Code's quality had slipped. We investigated, and published a post-mortem on the three issues we found. All are fixed in v2.1.116+ and we’ve reset usage limits for all subscribers.


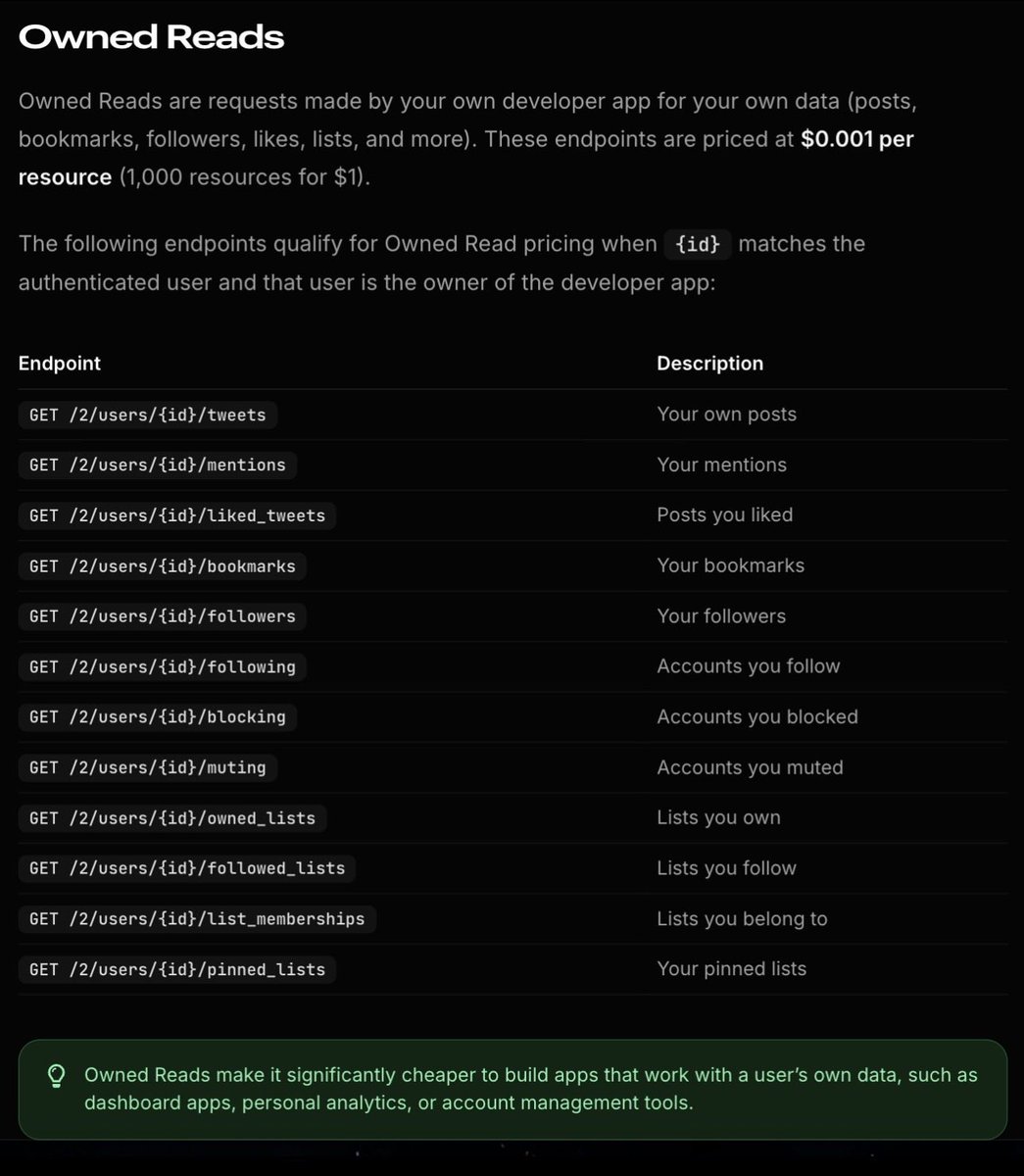
Updates to Owned Reads and pricing for posting via the API are now live.
Ladies and gentlemen, today we're launching one of our biggest changes to 𝕏 Introducing Custom Timelines This feature allows you to pin a specific topic to your home tab. With support for over 75 topics, you can dive deep into your favorite niche on X. It's powered by Grok's understanding of every post with the algorithm's personalization—meaning every timeline is made just for you. And it works even better when it's a topic you already engage with. This was a huge undertaking across many months, so we're excited for you take it for a spin. We're giving early access to Premium subscribers on iOS (and Android coming very soon).

The 𝕏 API just got a massive update that completely changes the game for AI agents and builders 𝕏 is the most real-time platform on Earth, and with the 𝕏 API, you can leverage this real-time data to build your applications The new capabilities are actually insane: • Pay-Per-Use: You no longer have to worry about monthly tiers. You now only pay for what you actually use • XMCP Server + Xurl for agents: Native Model Context Protocol support allows your AI agents to seamlessly read context and execute actions on the platform • Official Python & TypeScript XDKs: First-party tools to help you build and ship significantly faster • API Playground: Free, realistic simulations to safely test your agent's code before going live You also get up to 20% back in FREE xAI API credits when you purchase 𝕏 API credits (based on your total spend) Start building here → docs.x.com
Try using the X API





