Bohan Lyu retweetledi

April 1st marks 50 years of Apple. Thank you to everyone who’s been a part of our journey. apple.com/50-years-of-th…
#Apple50

English
Bohan Lyu
79 posts




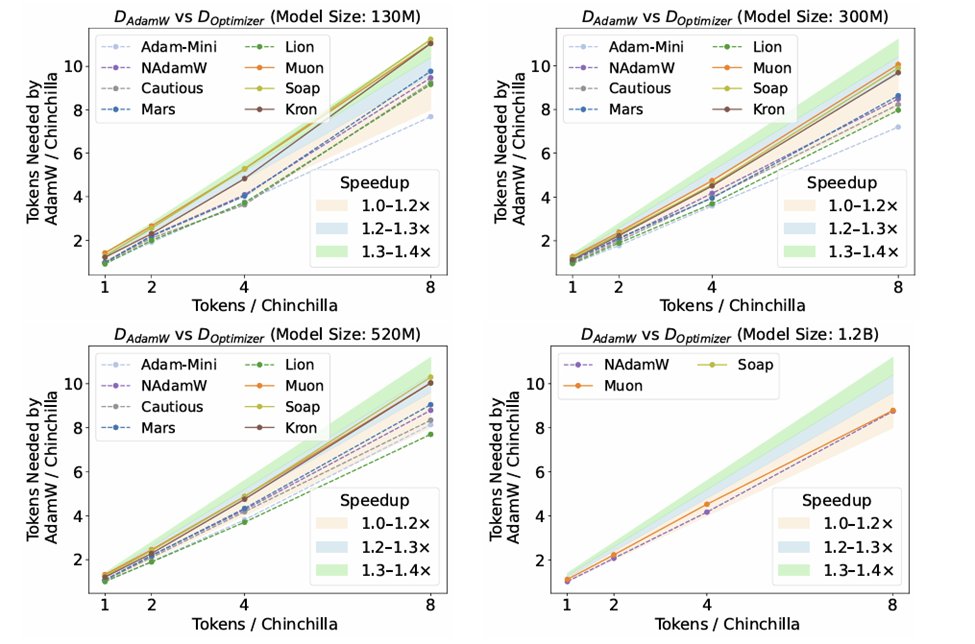
🚀 We present the first large-scale Lean 4 formulation of Statistical learning theory from scratch! Led by my student @yuanhezhang6 and collaborated with @jasondeanlee 📄 Paper: arxiv.org/abs/2602.02285 💻 GitHub: github.com/YuanheZ/lean-s… 🤗 Dataset: huggingface.co/collections/li…
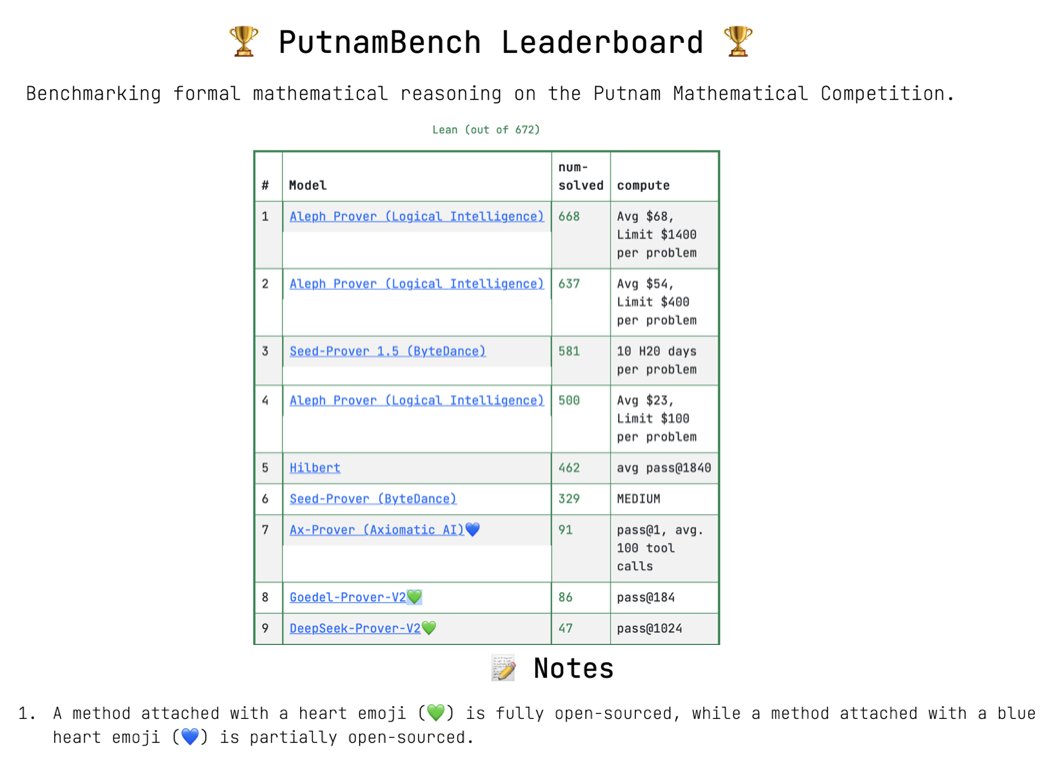

Excited to announce Seed-Prover 1.5 which is trained via large-scale agentic RL with Lean. It proved 580/660 Putnam problems and proved 11/12 in Putnam 2025 within 9 hours. Check details at github.com/ByteDance-Seed…. We will work on autoformalize towards contributing to real math!







Our Goedel-Prover V1 will be presented at COLM 2025 in Montreal this Wednesday afternoon! I won’t be there in person, but my amazing and renowned colleague @danqi_chen will be around to help with the poster — feel free to stop by!

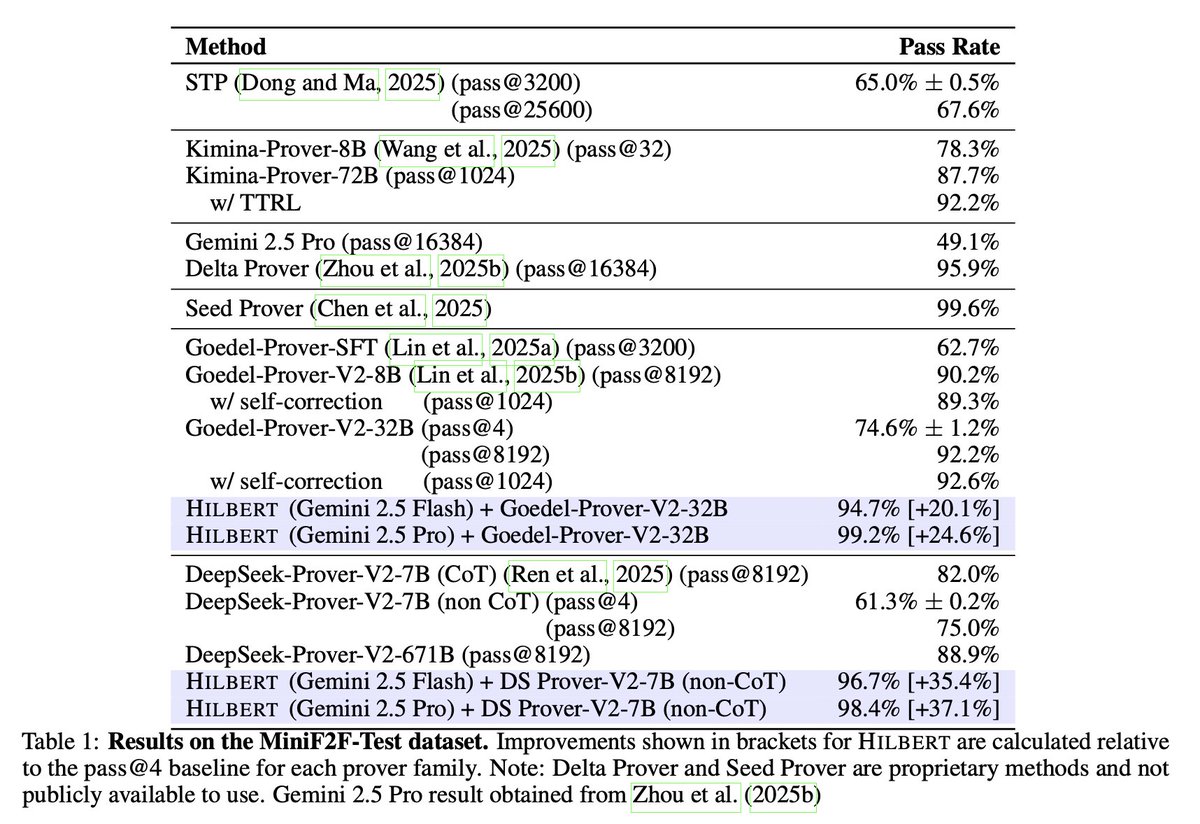


I want to quietly mention that we basicly came up with the same idea of code execution as world models six months ago, and it turned out to be a EMNLP'25 paper (top 0.5% meta score). Check out: arxiv.org/abs/2502.11167 . Glad to see META pushing it a lot further.