Sabitlenmiş Tweet

🚀 We're thrilled to announce Uni-MoE-2.0-Omni - a groundbreaking omnimodal large model that evolves from multimodal understanding to seamless understanding AND generation!
✨ What's New:
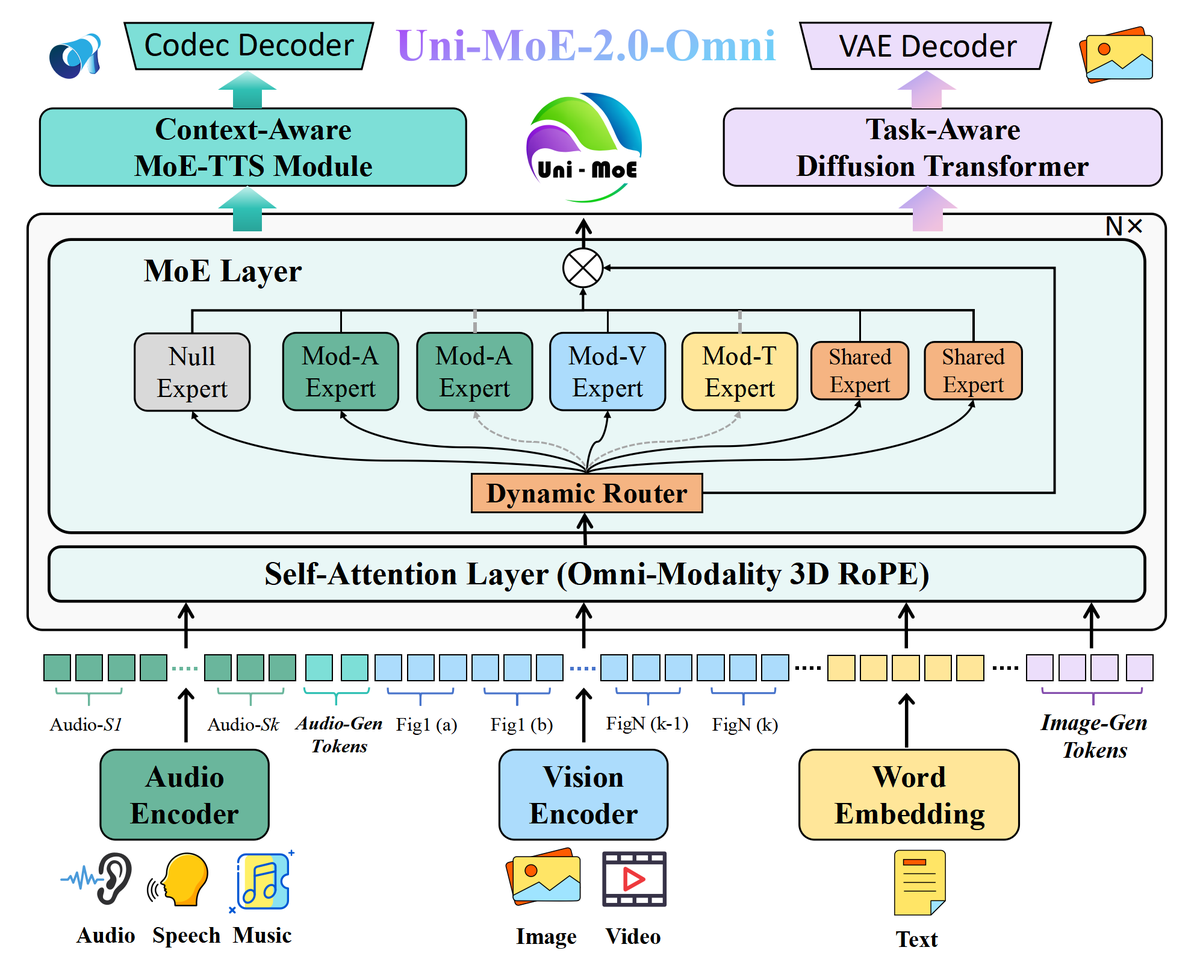
We explored how to transform dense LLMs into efficient MoE-driven omnimodal large models through progressive architecture evolution and training strategies.
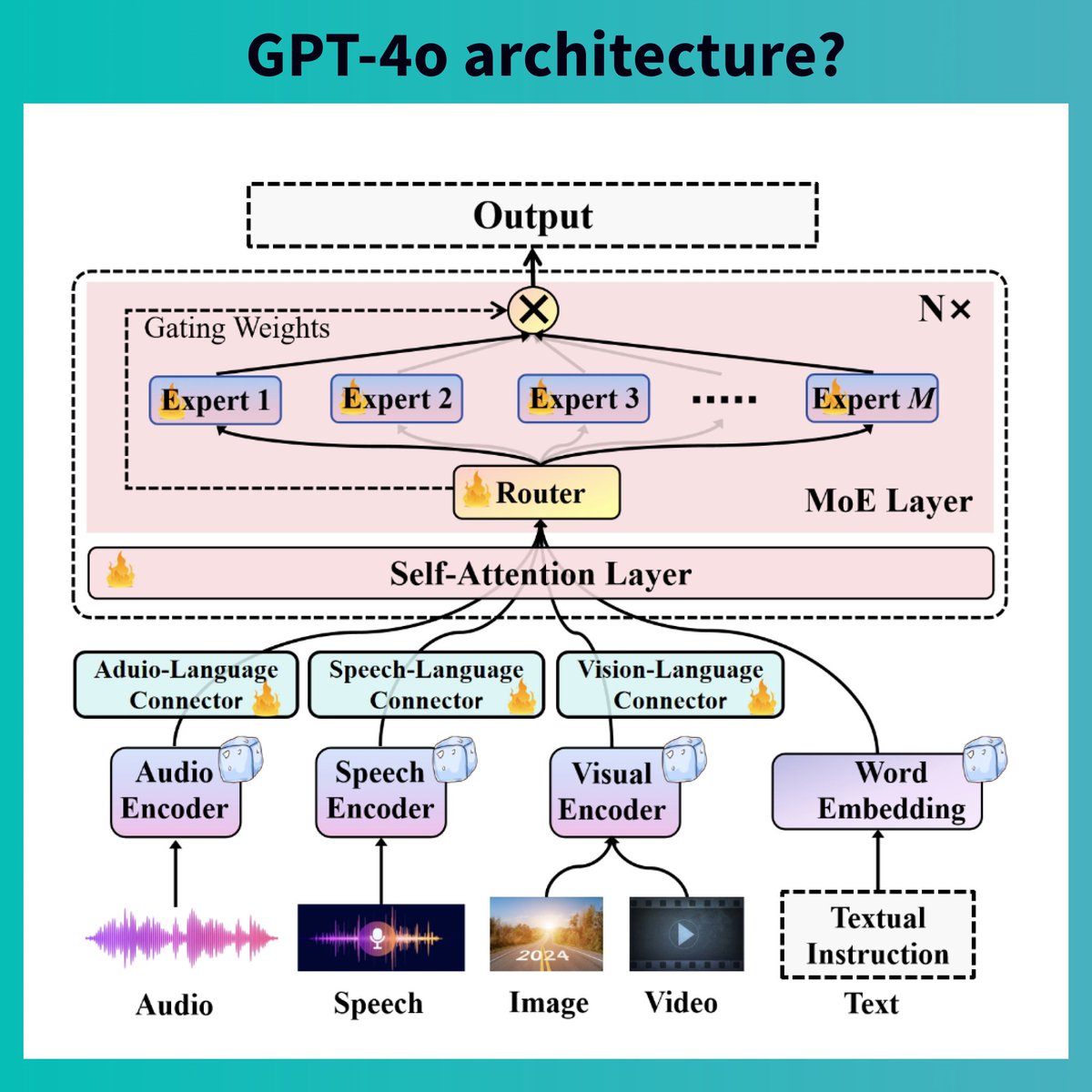
🧠 Architecture Innovations:
1️⃣ Novel Omnimodality 3D RoPE + Dynamic Capacity MoE
Unifies aliand gnment across speech, text, images, video in spatiotemporal dimensions, better for omnimodal inputs
Adaptive computation allocation based on task complexity
2️⃣ Deeply fused multimodal encoder-decoder design
Supports any combination of input/output modalities
Enables true omnimodal interaction & generation
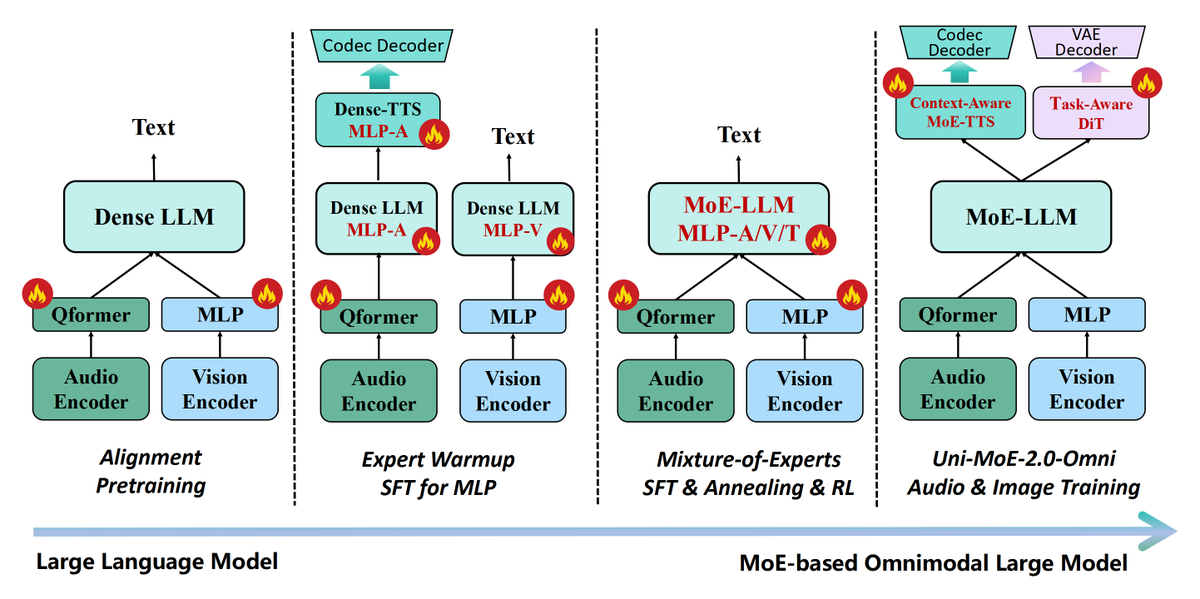
🛠️ Training Breakthroughs:
1️⃣ Progressive training strategy:
Cross-modal alignment → Expert warm-up → MoE fine-tuning & RL → Generative training
Efficiently scales dense LLMs to omnimodal MoE-based large models with a total of 75B tokens
Ensures stable convergence with less data, especially for RL
2️⃣ Language-anchored mixed understanding and generating training
Unifies understanding & generation tasks under a language generation framework
Breaks down barriers between modalities
🎨 Capabilities:
✅ Speech generation & interaction
✅ Image generation & editing
✅ Image/Video understanding
✅ Audio-visual reasoning
✅ And 10+ multimodal tasks!
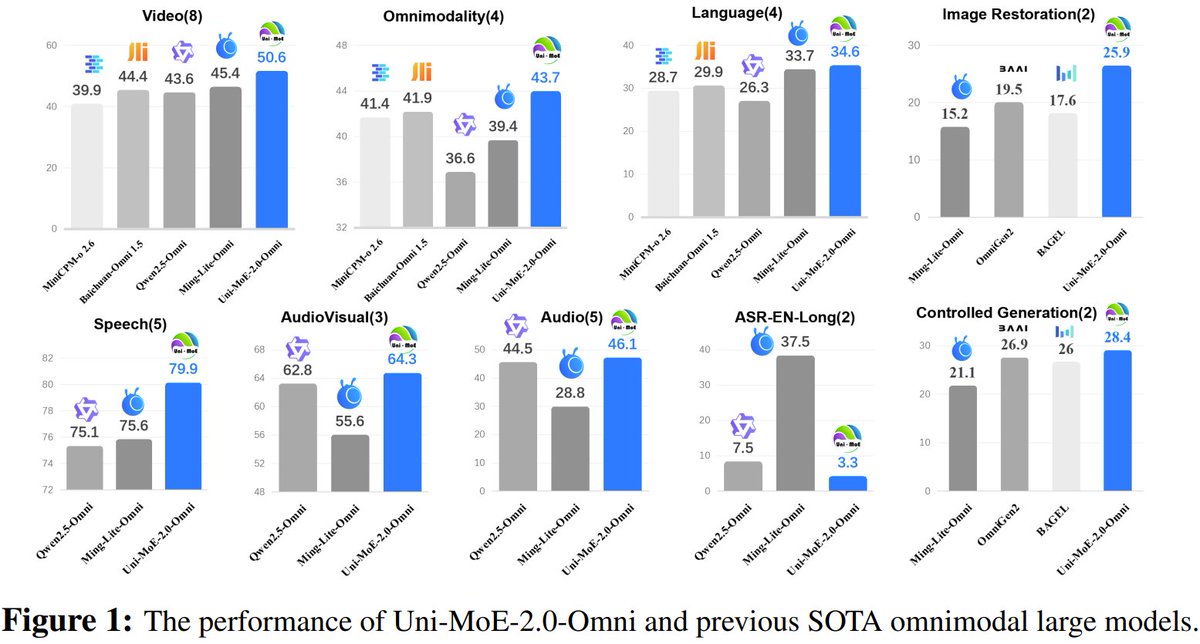
🔥 Key Results:
Outperformed Qwen2.5-Omni (1.2T tokens) in 50+ out of 76 comparable tasks with only 75B tokens!
📈 Video understanding (8): +5%
📈 Omnimodal understanding (4): +7%
📈 Speech QA: +4.3% lead
📈 Image processing: +7% lead
🌍 Now Open Source!
Model: huggingface.co/collections/HI…
Code: github.com/HITsz-TMG/Uni-…
Homepage: idealistxy.github.io/Uni-MoE-v2.git…


AK@_akhaliq
Uni-MoE-2.0-Omni Scaling Language-Centric Omnimodal Large Model with Advanced MoE, Training and Data
English