Sabitlenmiş Tweet
Mindwall
765 posts


Mindwall
@M1ndWall
I look at screens... a lot. Building the Knowledge Objects of tomorrow
Solana Katılım Mayıs 2012
401 Takip Edilen186 Takipçiler
@dreamofabear Can we pin those artifacts at top level for quick access in the claude app plaese? That would be a game changer
English

New feature I've been working on -- Cowork "Live artifacts" are dashboards and mini-apps that call your connectors (MCP's) directly. Get fresh data on load without spending tokens.
Excuse my silly example. Ask Claude to make you a better one!
x.com/claudeai/statu…
GIF
Claude@claudeai
In Cowork, Claude can now build live artifacts: dashboards and trackers connected to your apps and files. Open one any time and it refreshes with current data.
English


Just spent over an hour with my clinical team debating which growth hormone peptide protocol to run. Still torn. Wanted to share the thinking and get your take.
The goal: Increase GH and IGF-1 to support anabolism, recovery, and sleep, but also test a specific stacking hypothesis.
Tirzepatide (GLP-1/GIP agonist) can elevate resting heart rate, disrupt sleep, and suppress appetite aggressively.
CJC-1295 (GHRH analog) can worsen insulin resistance. The bet is that combining them cancels each other's downsides: CJC-1295's slow-wave sleep enhancement offsets tirzepatide's sleep disruption, while tirzepatide's insulin-sensitizing effects counteract CJC-1295's insulin resistance. Best of both worlds — or at least, that's the hypothesis we're testing.
The two candidates:
CJC-1295 with DAC: the long acting version. One injection per week, stays active for 6–8 days. This is what was used in the actual clinical trials. Raises GH 2–10x and IGF-1 1.5–3x from a single dose. Preserves GH pulsatility even under continuous stimulation. The tradeoff: if you get side effects, you're committed for a week. Harder to titrate.
CJC-1295 without DAC + ipamorelin: the short-acting version paired with a selective ghrelin receptor agonist. Daily injections, pre-bed, clears in 30 minutes.
Ipamorelin adds a second axis of GH release, pulse frequency via the ghrelin pathway, on top of the amplitude boost from CJC. No cortisol or prolactin elevation. This is what most clinicians prescribe and most of the peptide community uses. The tradeoff: less clinical trial data, daily injections, more anecdotal evidence base.
What we're considering:
Start with DAC at half dose 2.4 mg, then if well tolerated escalate 4.8 mg, weekly injection.
If side effects aren't tolerable, switch to no-DAC + ipamorelin (100 mcg then 200-300 mcg daily, before bedtime).
Or,
Run both head to head. 2 weeks DAC, 2 weeks no-DAC + ipamorelin and compare.
Tracking: GH, IGF-1, Cortisol, CGM, real time core body temperature, RHR, overnight HRV (rMSSD), IGF-1, HOMA-IR, sleep architecture, subjective recovery.
The purist in us says stick with DAC; that's where the published data lives. Yet the pragmatist says no-DAC + ipamorelin is what thousands of people actually use, and testing it generates more socially relevant data.
English

LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English


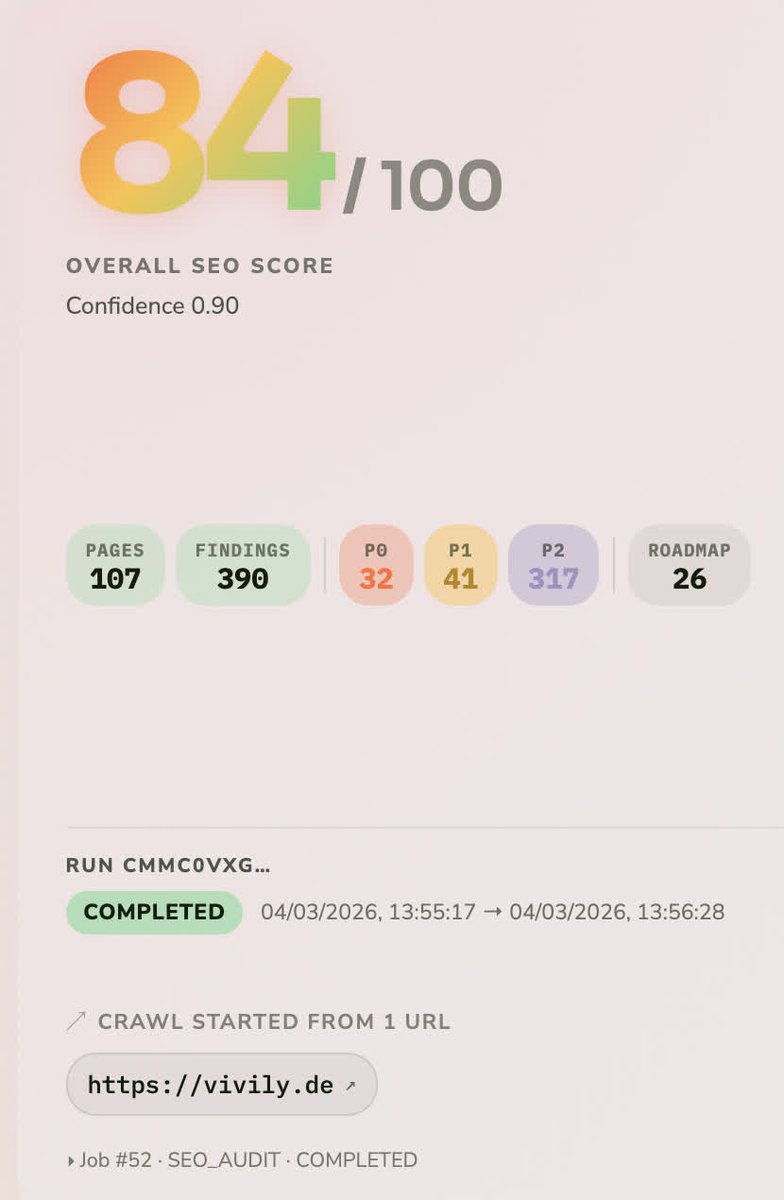
Built an AI system that audits 49+ SEO issues in 20 minutes, tracks competitors 24/7, and generates 15+ optimized articles every week.
It replaces $500 manual audits that take 3 days.
Recently onboarded 5 new clients most use it to attract more clients and boost visibility. Testing with 3 more companies now.
If you want it:
Like + Comment “SEO”
I’ll DM you the details.

English
Seeing ALPHA being used as Lebel by newly released product hurts my soul. The alpha testing might be customer acceptance test but is not out in the wild for everybody to download, it never was and never will be, no matter how bad you marketing attempt is. Just call it beta, theo
Theo - t3.gg@theo
T3 Code is now available for everyone to use. Fully open source. Built on top of the Codex CLI, so you can bring your existing Codex subscription.
English



confession time: i've never felt more paralyzed when it comes to work. i unlock my computer and i'm like what in the flying fuck should i do now...
English

I just asked Claude Code to replace a hardcoded constant 3 with 5 in my vibe-coded project because I have no idea where it is.
English