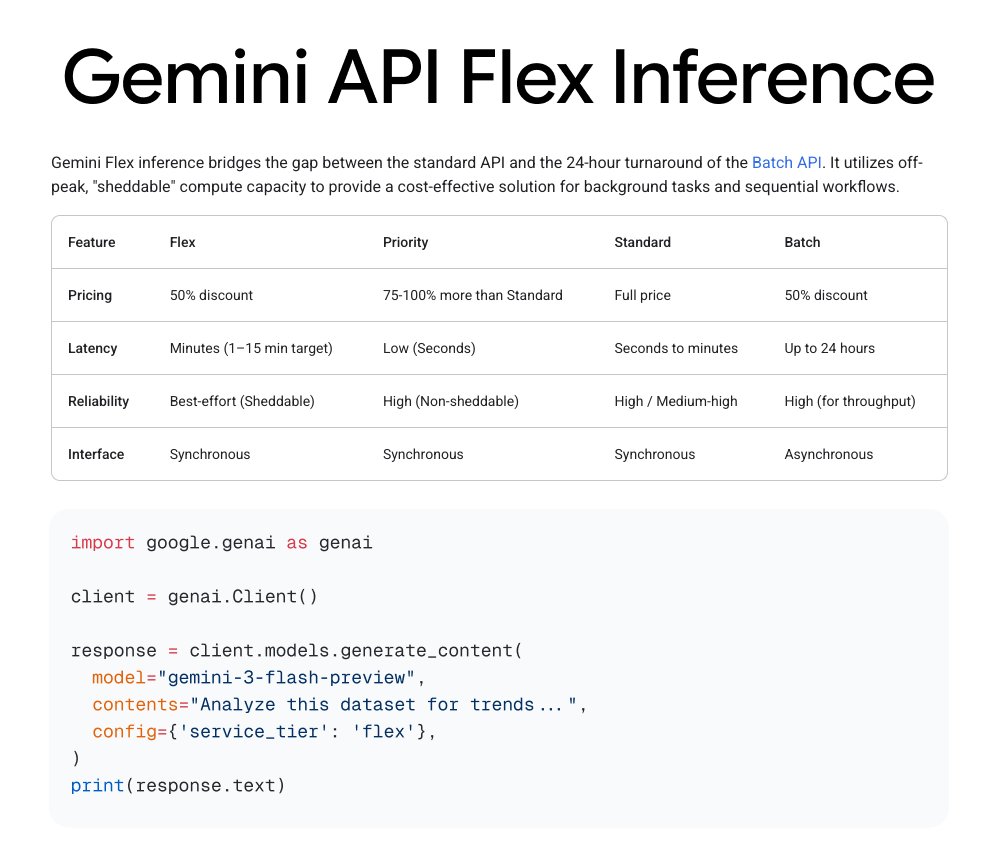
@NielsRogge Hey Niels, in this specific case, if you remember, they released the dinov2 register paper after a few months, so how do you plan to incorporate such updates (which are not really version updates). Maybe have multiple follow up papers?
English