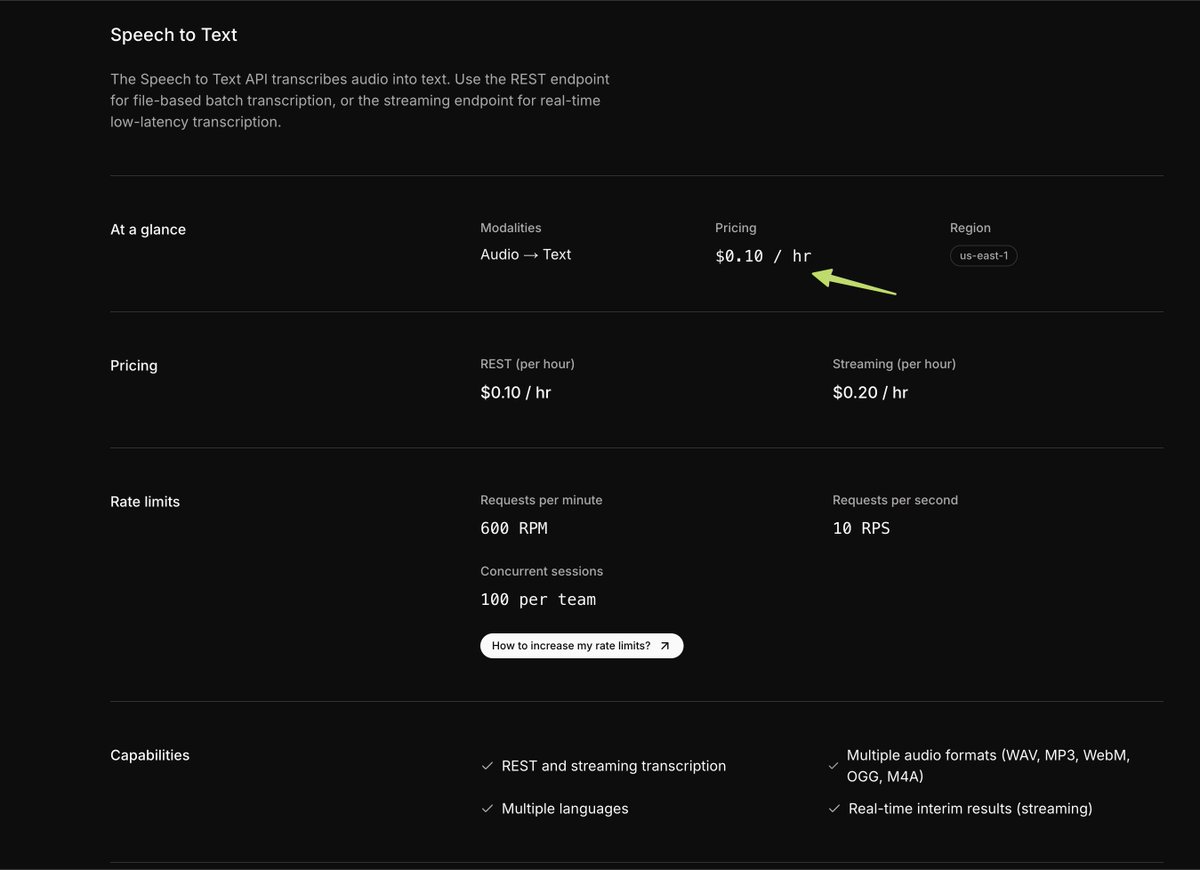
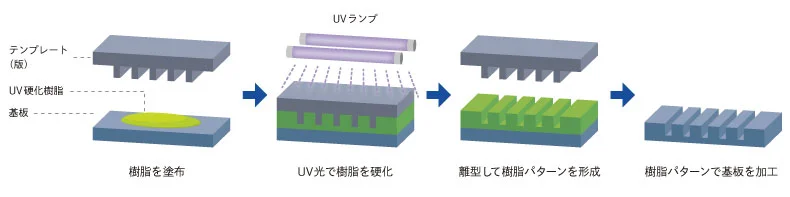
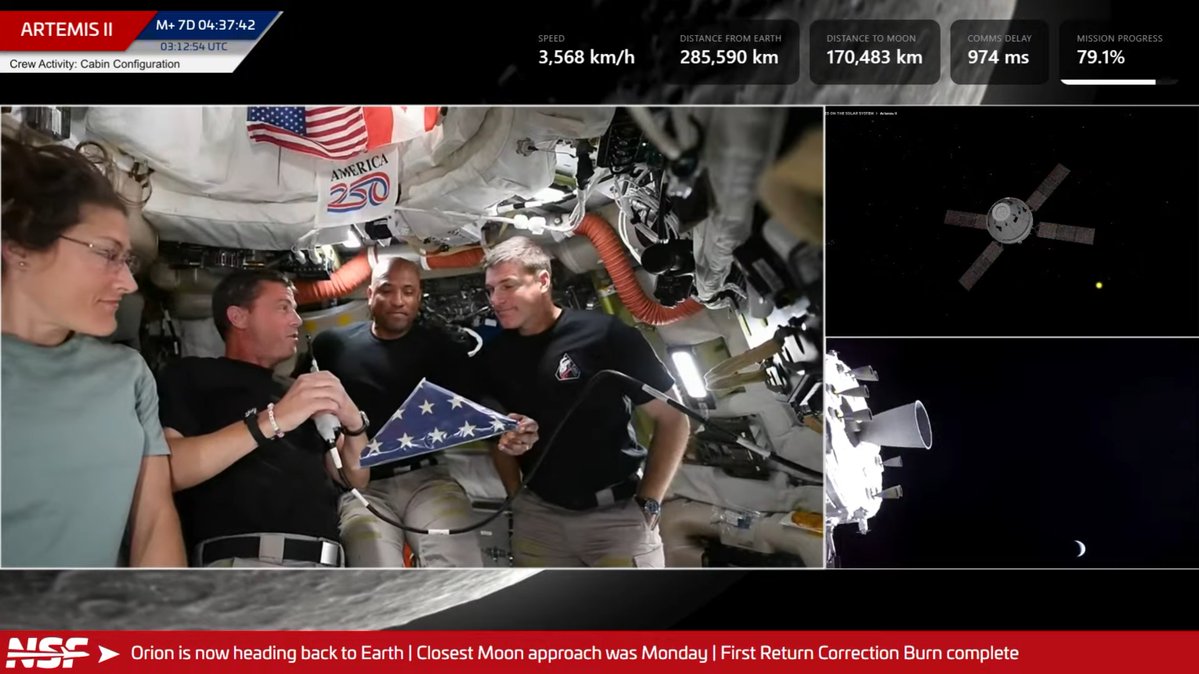
Qwen3.6 35BA3B seems to spend an enormous time thinking and makes tons of tokens. My Hermes agent compacted a 128K window (0.85 threshold I think) 4+ times writing what seems to be not too complicated code. A speed up over 27B means nothing if it's spent on more thinking.
English