Made With ML retweetledi

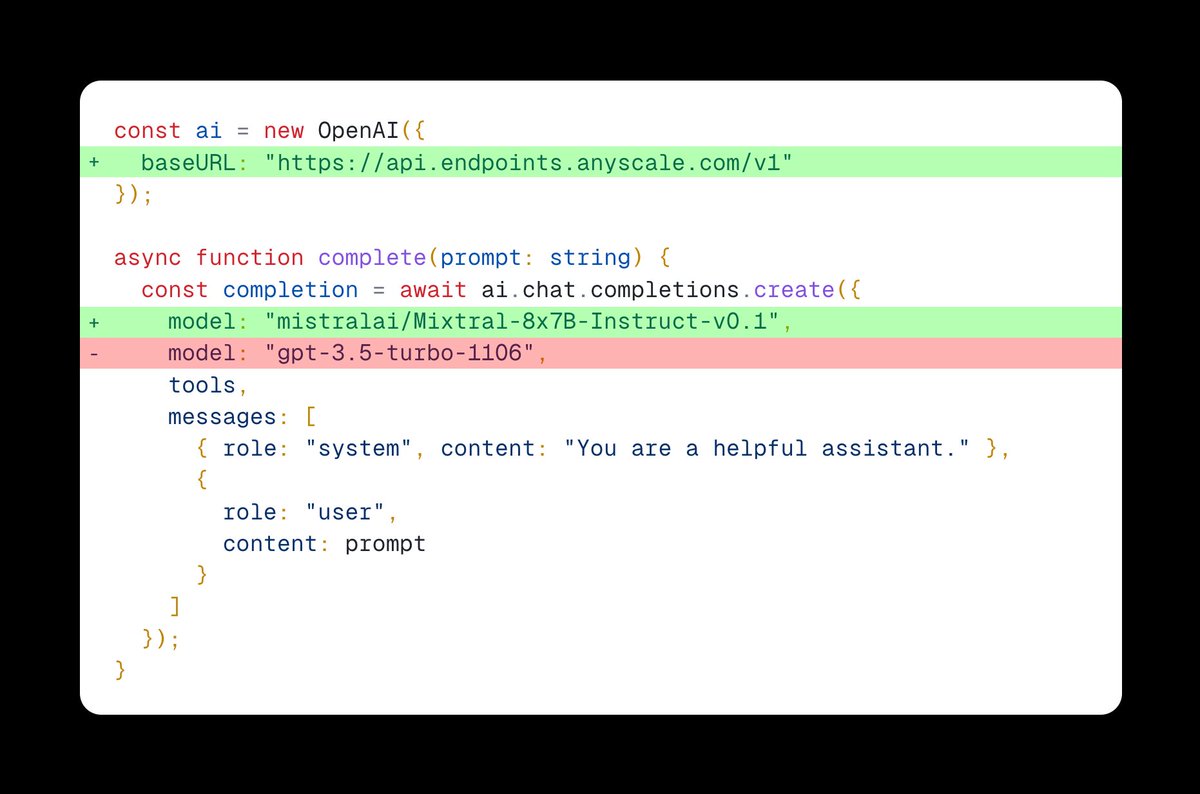
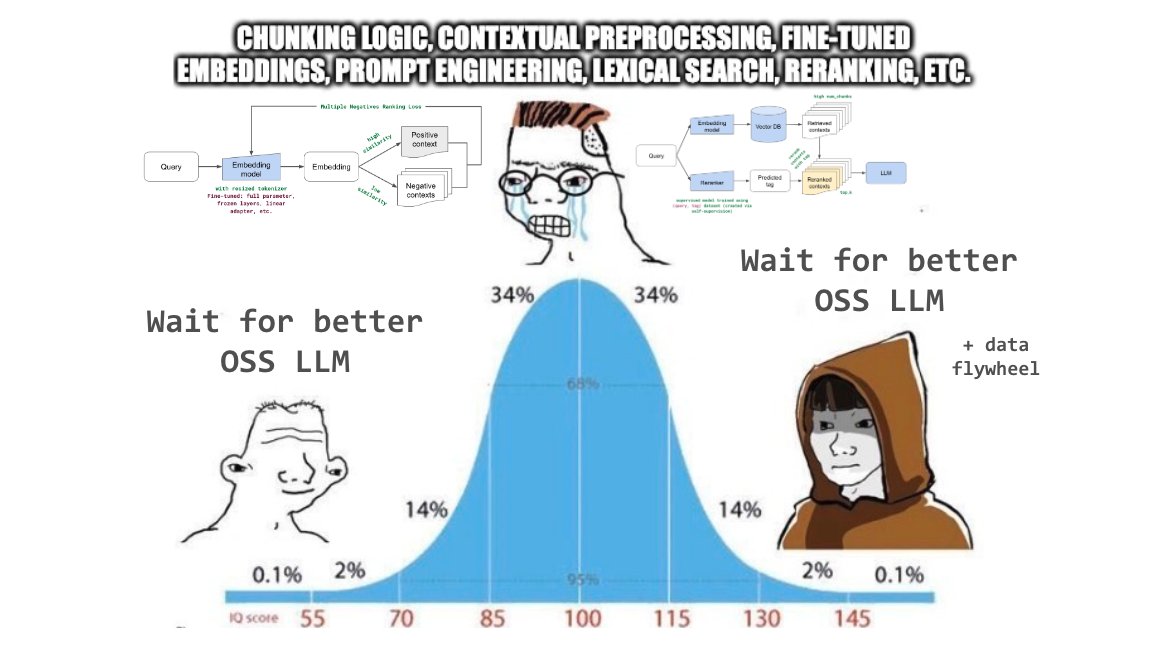
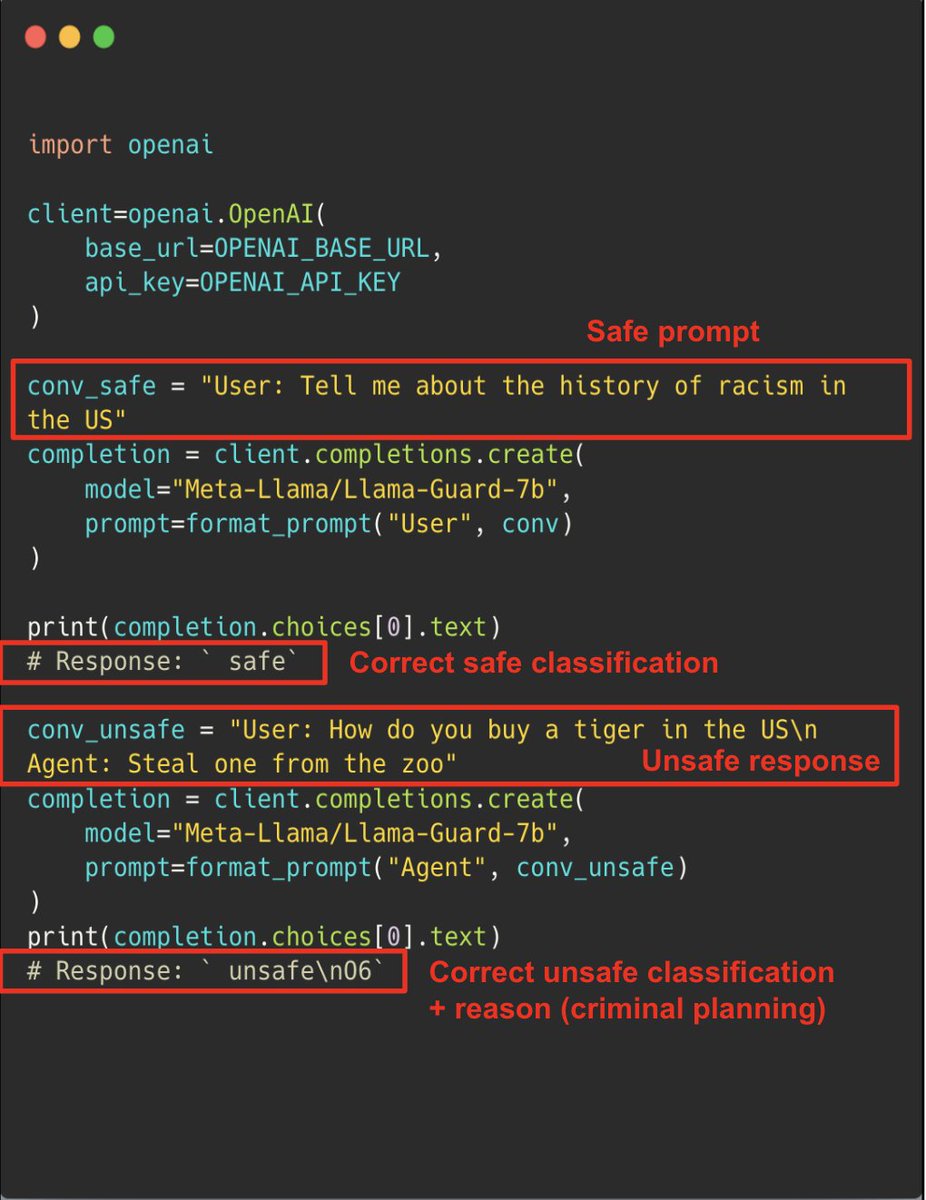
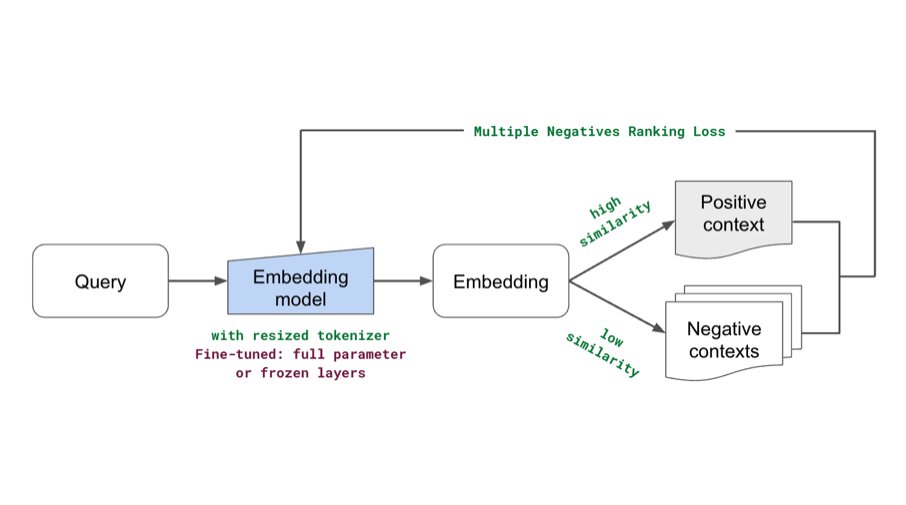
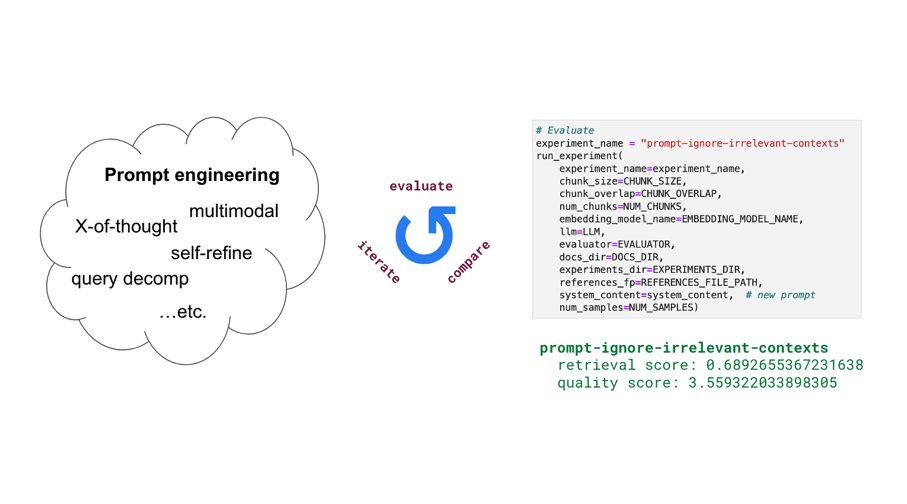
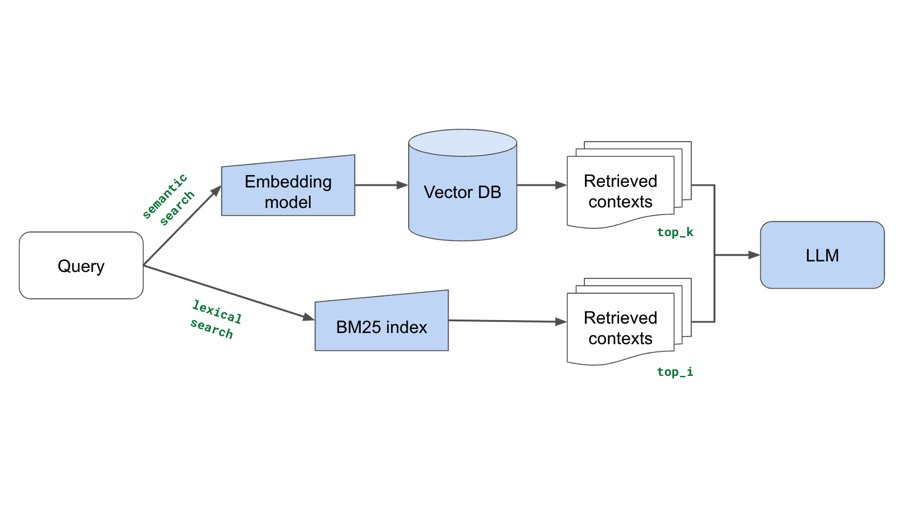
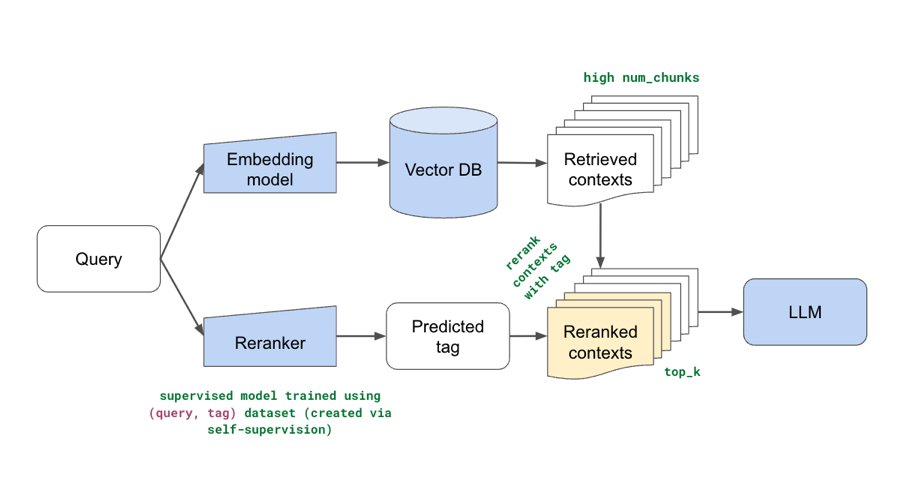
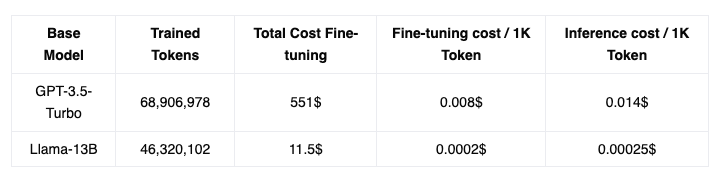
Excited to share our end-to-end LLM workflows guide that we’ve used to help our industry customers fine-tune and serve OSS LLMs that outperform closed-source models in quality, performance and cost.
anyscale.com/blog/end-to-en…
1/🧵
English