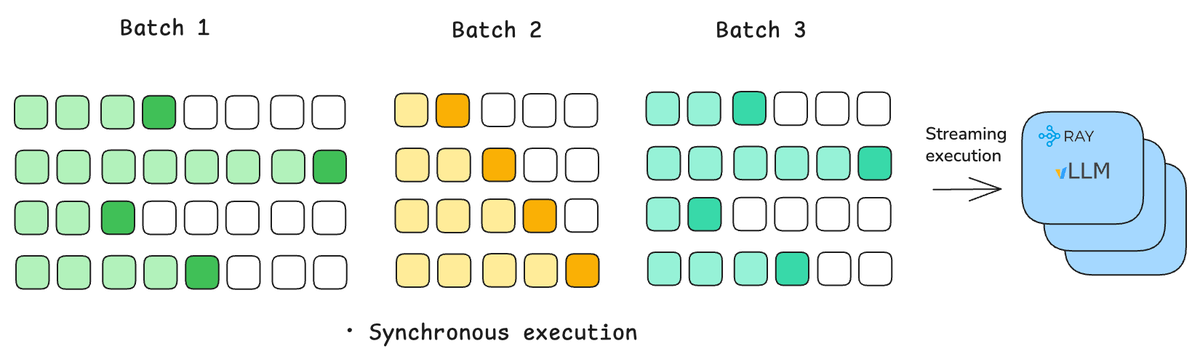
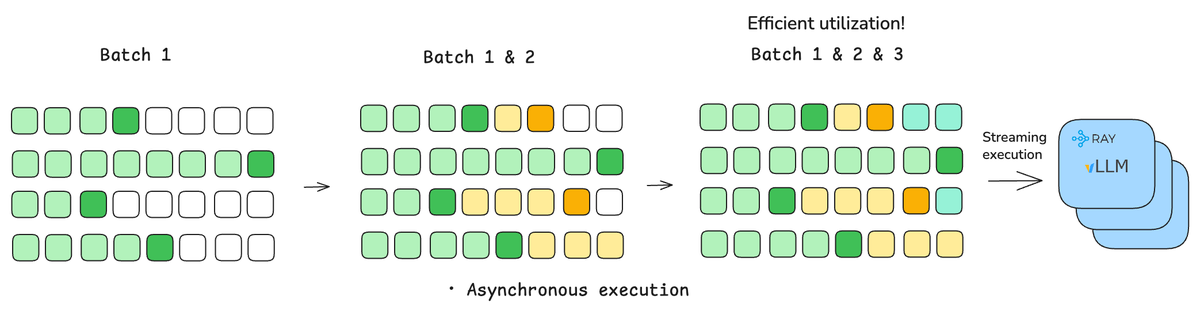
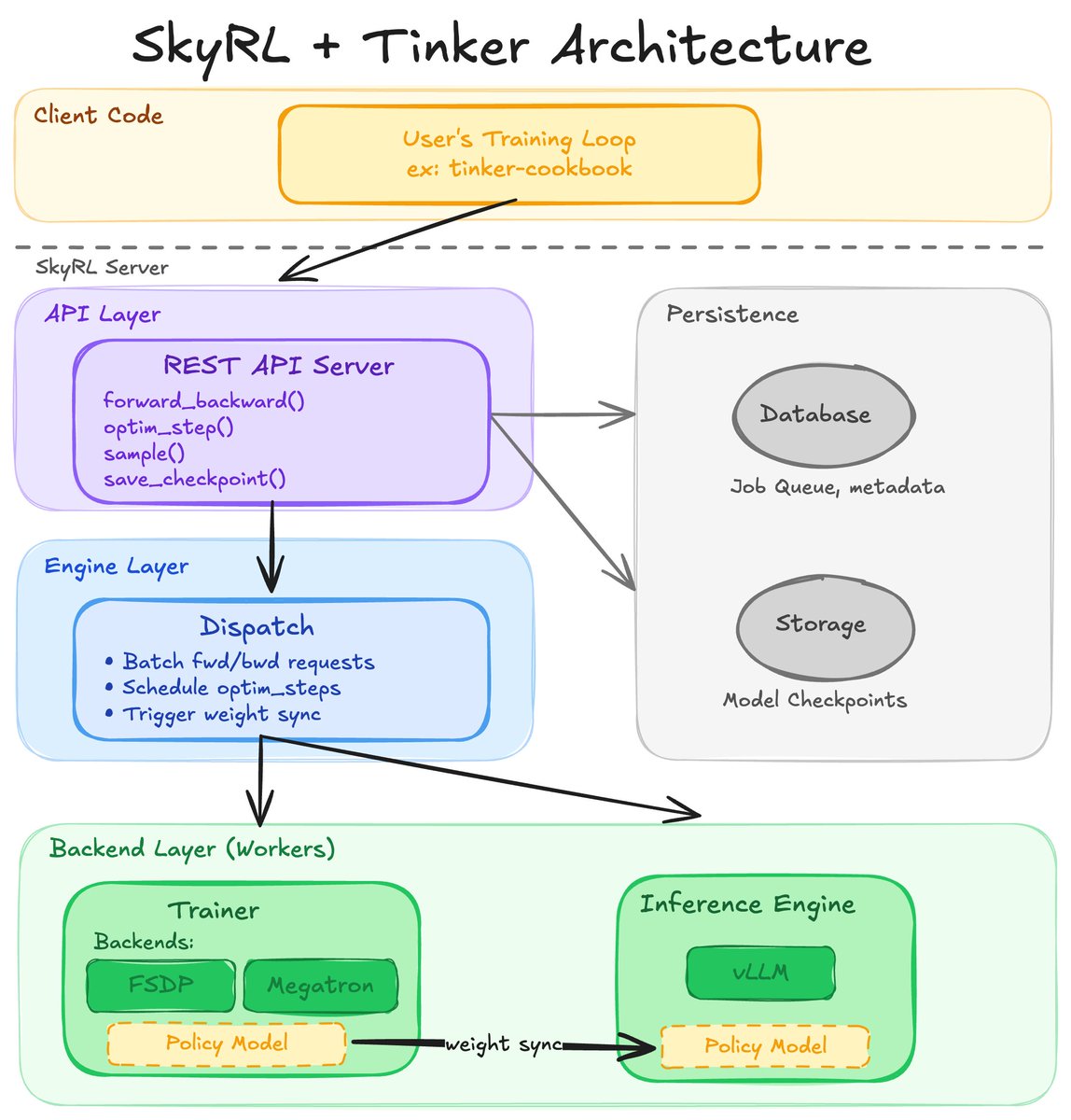
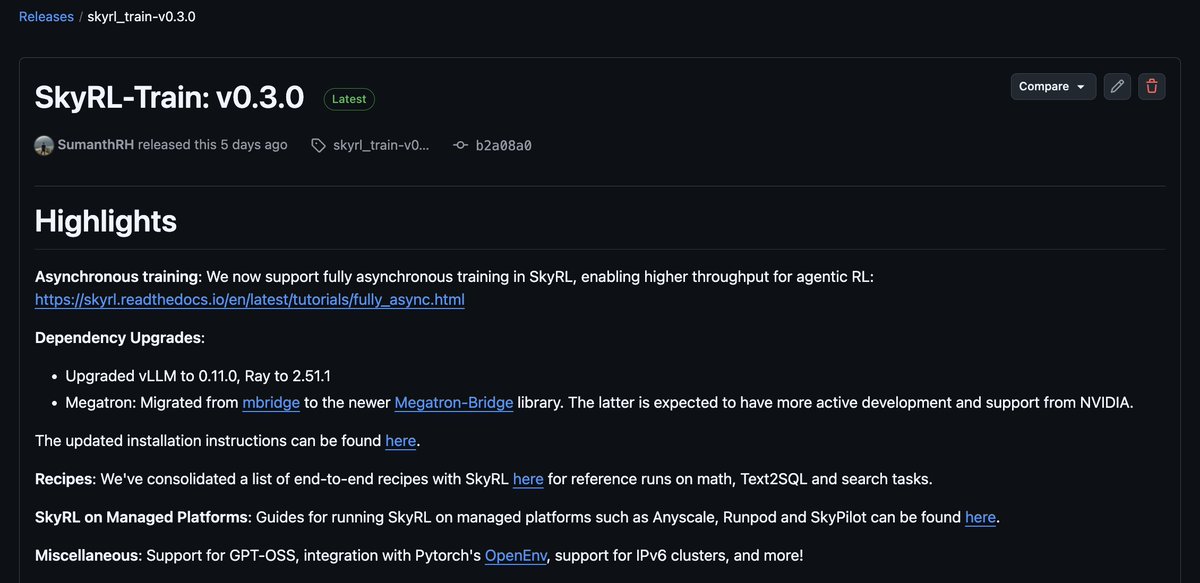
Philipp Moritz retweetledi

SkyRL now supports end-to-end vision-language post-training, from SFT to agentic RL, and adds vision model support to SkyRL’s Tinker interface! Existing multimodal cookbooks, e.g. VLM classification, work out of the box:

English