Sabitlenmiş Tweet

@jeremyphoward @fastdotai Jeremy, you just made my day !!! Thank you for mention!!!
English
Manish Chablani
462 posts

@ManishChablani
Head of AI and Research @EightSleep, Marathoner. (Past: AI in healthcare @curaiHQ, self driving cars @cruise, ML @Uber, Early engineer @MicrosoftAzure)
















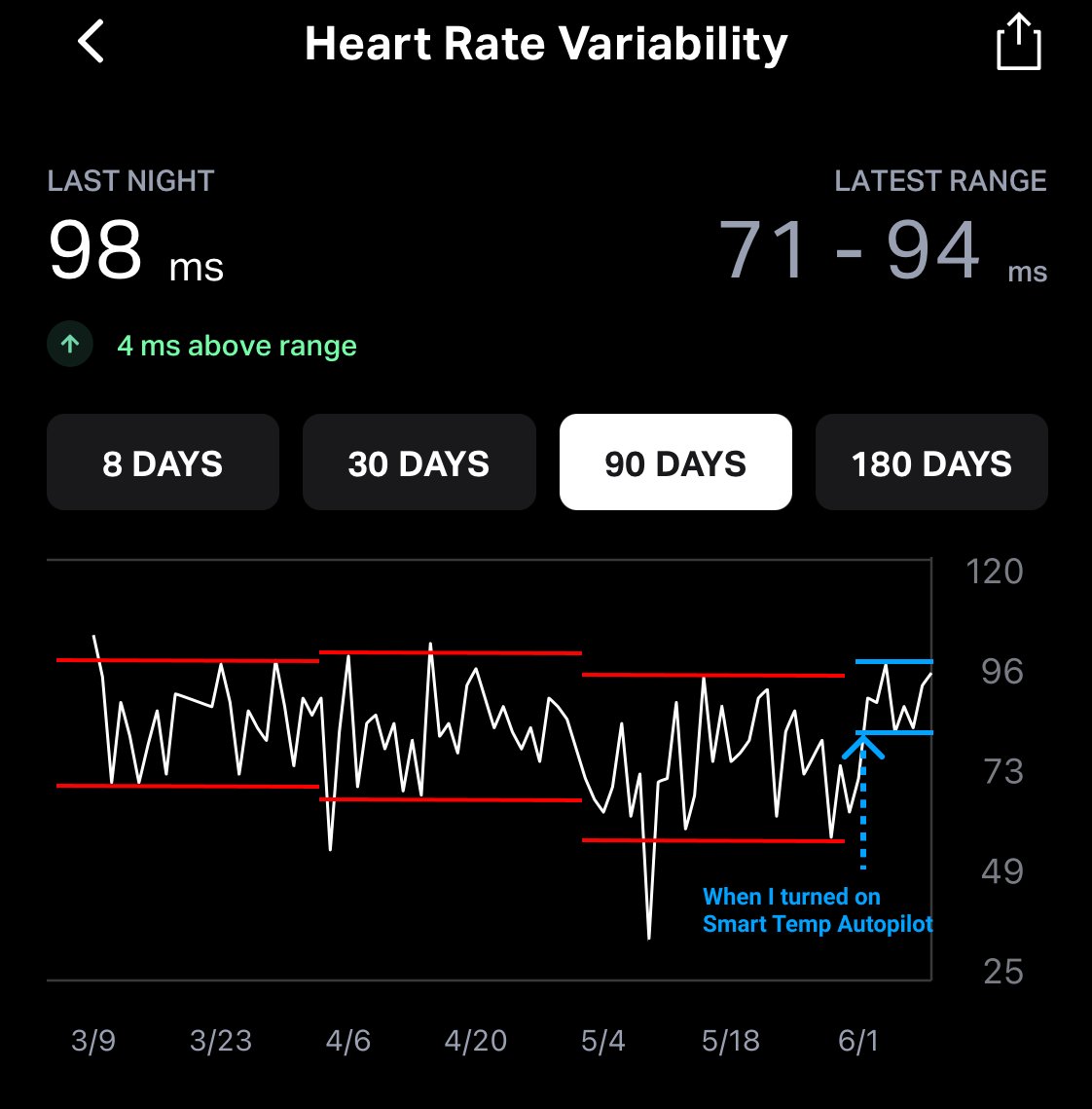
BREAKING NEWS: Today we are launching SleepOS, the first operating system for sleep enhancement. SleepOS now powers @eightsleep Pod features including Smart Temp Autopilot, Sleep and Health Insights, and it will continue evolving to help humanity unlock sleep fitness.