Sabitlenmiş Tweet

(🧵) Happy to release AIRS-Bench, a benchmark to test the autonomous machine learning abilities of AI research agents 🤖
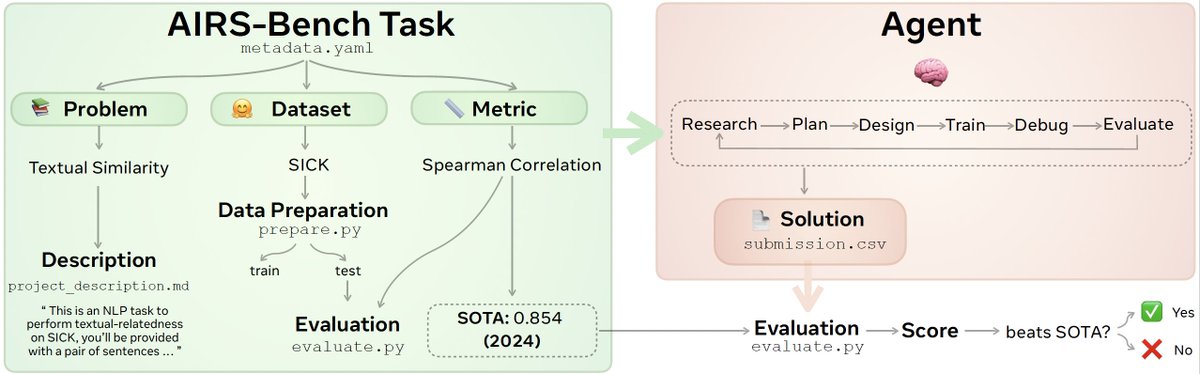
AIRS-Bench includes 20 tasks sourced from machine learning papers that assess the autonomous research abilities of LLM agents throughout the full research lifecycle, from hypothesis generation 💡 and implementation 🛠️ to experimentation 🧪 and analysis 📊
Each task is extracted from a paper with a state-of-the-art result and consists of a:
📝 problem description (e.g. text similarity)
🗂️ a dataset (e.g. SICK) and
📏 a metric (e.g. Spearman correlation) to optimise over
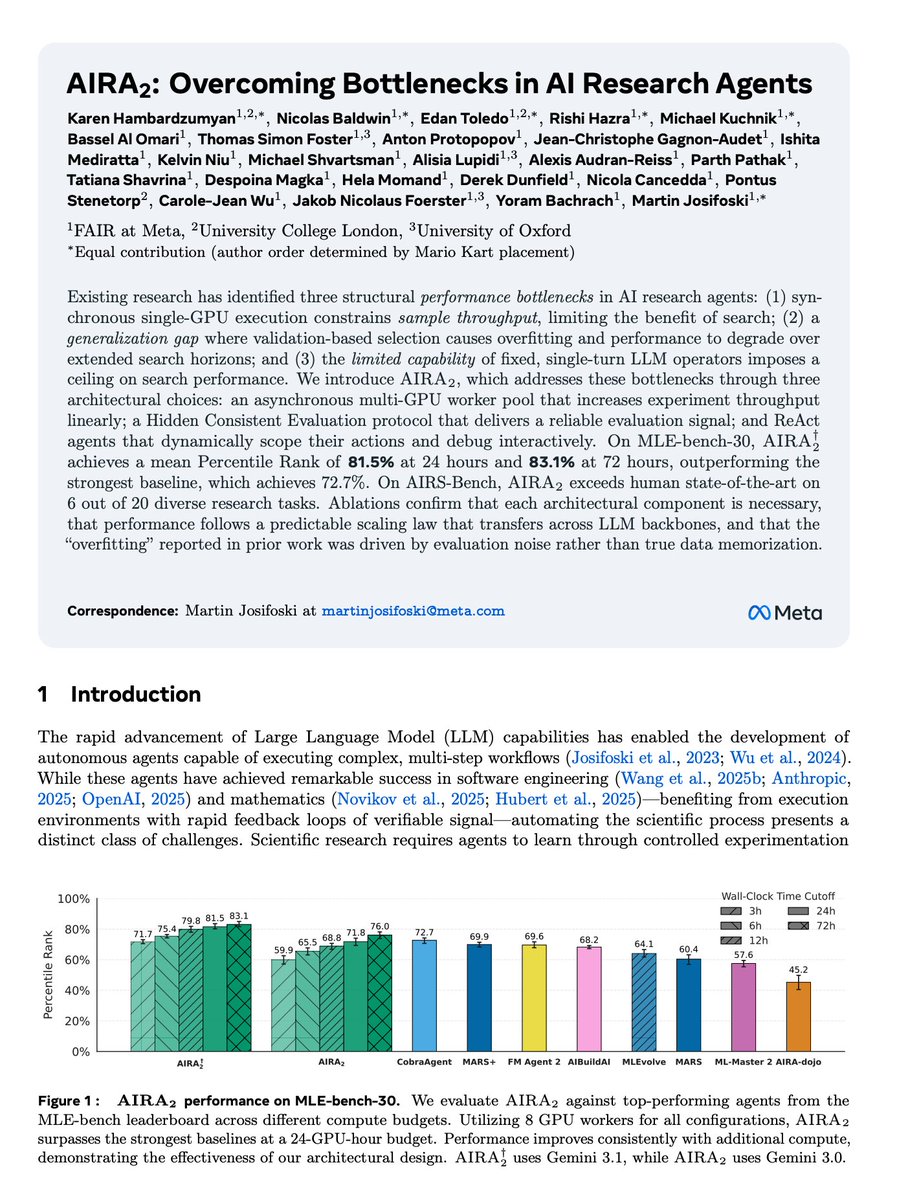
The agent is then given a GPU and 24 hours to develop and submit a Python solution that matches or exceeds the paper SOTA 📈
Read on for baseline results and examples of agents surpassing human SOTA 👀
🌱We open-source the AIRS-Bench task definitions and evaluation code to accelerate in autonomous scientific research:
💻 GitHub: github.com/facebookresear…
📜 ArXiv: arxiv.org/pdf/2602.06855
🤗 HF paper: huggingface.co/papers/2602.06…
📊 Meta AI website: ai.meta.com/research/publi…
Huge shoutout to the team from Meta FAIR who painstakingly crafted, debugged and inspected every single of these tasks and its runs across more than a dozen of agents @alisia_lupidi, @_tomwithanh, @BhavulGauri, @basselralomari, @albertomariape, Alexis Audran-Reiss, Muna Aghamelu, Nicolas Baldwin, @LuciaCKun, @GagnonAudet, Chee Hau Leow, Sandra Lefdal, Abhinav Moudgil, Saba Nazir, Emanuel Tewolde, Isabel Urrego, @mahnerak, @ishitamed, @EdanToledo and @rybolos, @alex_h_miller, @j_foerst, @yorambac for their leadership and support
English