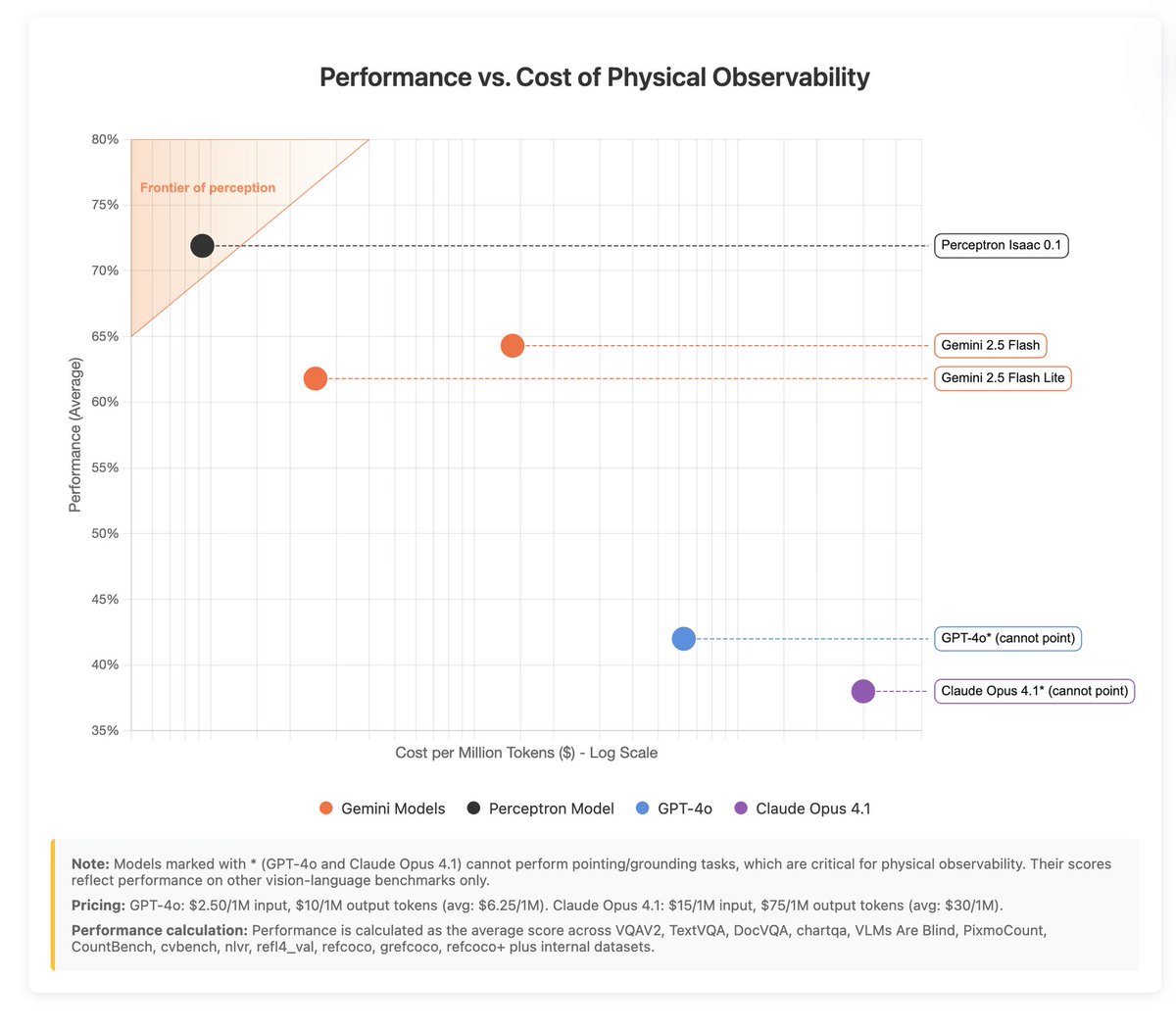
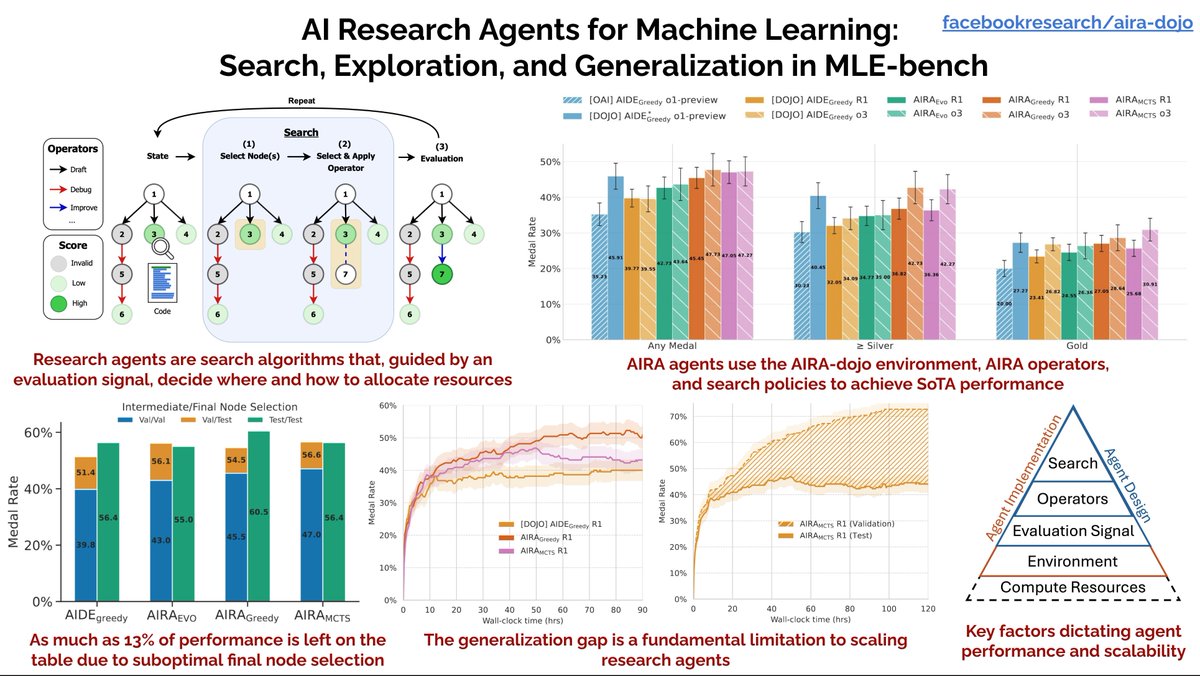
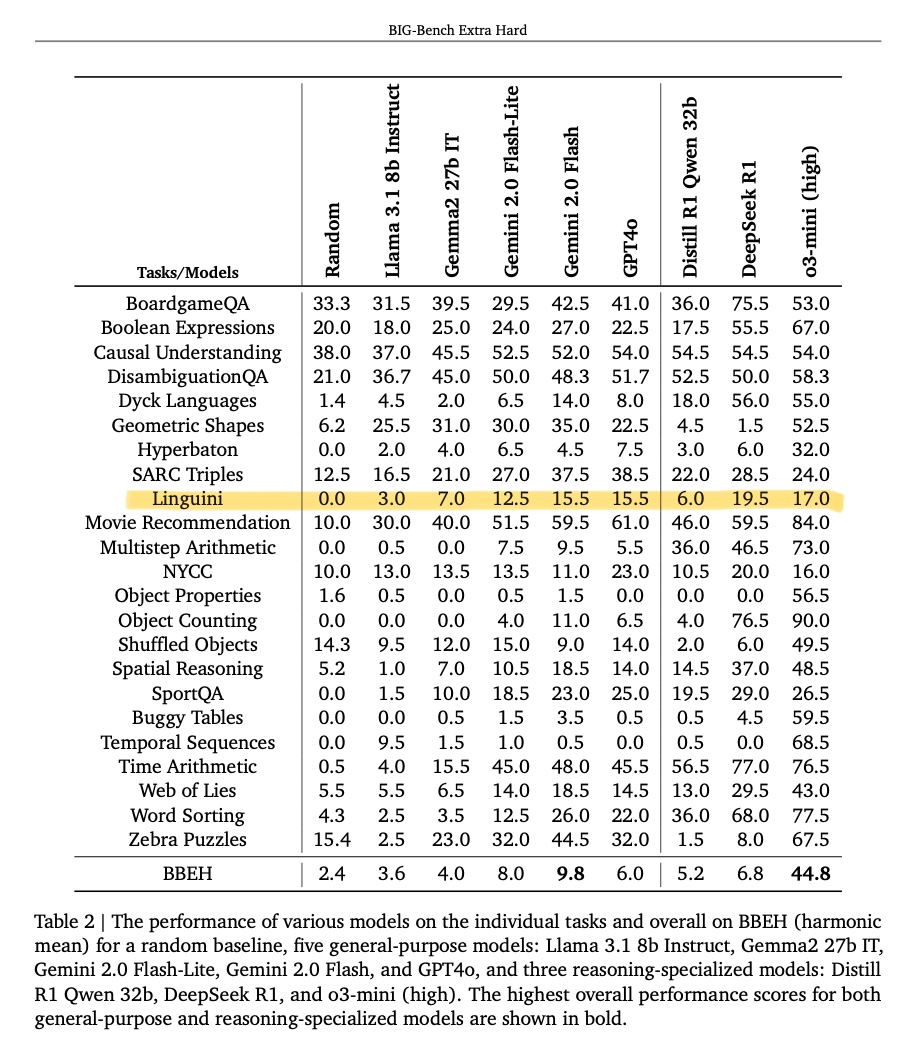
Karen Hambardzumyan retweetledi

Introducing - AIRS Bench, a benchmark for “AI Researcher Agent”. Agents attempt 20 open ML problems starting from zero code (full research loop). And yes, they beat SOTA in few cases (read more below!) arxiv.org/abs/2602.06855
English