Supersocks@iamsupersocks
Google TurboQuant : le thread complet pour TOUT comprendre.
Pétard mouillé ou game-changer pour les modèles locaux ?
Pourquoi le marché mémoire a pricé 90 milliards de risque en quelques jours, pourquoi un dev solo a devancé Google sur l'implémentation, et pourquoi un MacBook fait déjà tourner un modèle de 104 milliards de paramètres.
On déroule.
1/ Le problème.
Quand une IA vous répond, elle garde des "notes" de toute la conversation. C'est le KV cache (Key-Value cache).
Plus la conversation est longue, plus les notes grossissent. Et elles grossissent VITE.
Le vrai bottleneck des LLM en local, c'est pas les poids du modèle on arrive à les quantizer comme il faut avec GGUF, AWQ, etc. C'est le KV cache.
Exemple concret : le Qwen3.5-35B-A3B, le modèle que beaucoup d'entre vous font tourner en local.
En Q4, il prend ~22 Go pour les poids. Ça rentre sur une RTX 4090 24 Go. Cool.
Mais dès que tu pousses le contexte à 262K tokens (sa fenêtre native), le KV cache ajoute ~5 Go de plus. Là t'es à 27 Go. Ta 4090 a dit stop.
Ceux qui build en local le savent : le vrai mur, c'est le contexte. Ton Qwen rentre en VRAM, mais essaie de lui donner un vrai document long ou une session de 50 messages et ta RAM te dit stop. Tu finis par couper le contexte à 32K, 16K, voire 8K pour que ça tienne.
C'est aussi pour ça que ChatGPT ou Claude "oublient" le début de la conversation. Pas parce qu'ils sont bêtes. Parce que la mémoire de travail explose.
2/ Comment PolarQuant compresse autant.
Prenez une carte au trésor. Deux façons de noter la même position :
• "3 pas est, 4 nord" → coordonnées cartésiennes
• "5 pas, cap 37°" → coordonnées polaires
Même info, même taille. Jusque-là zéro gain.
Mais voilà le piège : le coût de la compression, c'est pas les données. C'est l'emballage.
En format classique, les valeurs sont chaotiques.
Chaque paquet a besoin de son propre emballage sur-mesure (des constantes de calibration).
À 3 bits de compression, ces emballages bouffent la moitié de la place qu'on vient de libérer. Un comble.
PolarQuant applique une rotation mathématique qui force toutes les données à avoir la même distribution prévisible. Après ça, un seul emballage universel suffit pour tout. Le gaspillage disparaît.
Le changement de coordonnées ne compresse rien. Il rend la compression possible sans déchets.
3/ Comment ça marche ? (en 3 couches de profondeur)
Couche 1 - Pour tout le monde :
TurboQuant prend les notes de l'IA, les réorganise pour qu'elles prennent 6x moins de place, sans perte mesurable sur les benchmarks. C'est comme ranger un placard en désordre. Rien n'est jeté, tout est juste mieux rangé.
Couche 2 - Pour les curieux :
Étape 1 (PolarQuant) : les données en mémoire sont un bazar, des valeurs énormes ici, minuscules là, aucun pattern. PolarQuant les "secoue" avec une rotation mathématique. Après ça, toutes les valeurs se rangent dans le même format prévisible. Un seul outil de compression universel suffit pour tout, au lieu d'un outil différent par bloc. C'est là que le gros du gain mémoire se fait.
Étape 2 (QJL) : la compression laisse de minuscules erreurs résiduelles. TurboQuant utilise 1 seul bit par dimension pour les corriger. Le résultat : l'IA calcule ses scores d'attention aussi précisément qu'avant sur tous les benchmarks testés.
Couche 3 - Pour les nerds :
Le tout est data-oblivious : aucun entraînement, aucune calibration, aucun dataset.
La rotation est une matrice orthogonale via décomposition QR. Le codebook est un quantizer Lloyd-Max optimal sur la distribution Beta induite.
Budget total ~3.5 bits : 3 bits PolarQuant + 1 bit QJL.
Distortion MSE bornée par √(3π/2) × 1/4^b. Proche des bornes théoriques à facteur constant près.
4/ Les chiffres qui claquent.
→ 80 Go de KV cache → 13 Go. Sur le même GPU.
→ Jusqu'à 8x plus rapide pour calculer l'attention sur H100 (en 4-bit, dans les benchmarks Google)
→ Qualité neutre sur LongBench, Needle-in-Haystack, ZeroSCROLLS, RULER, L-Eval
→ Indexation vectorielle en 0.0013s vs 239s pour Product Quantization
→ Testé sur Gemma, Mistral, Llama, Qwen -> fonctionne sur tout
→ Data-oblivious : zéro calibration, zéro fine-tuning, ça marche out-of-the-box
5/ Ce que turboquant n'est pas.
⚠️ TurboQuant ≠ compression du modèle.
Il compresse la MÉMOIRE DE TRAVAIL (le KV cache), pas le cerveau (les poids du modèle).
Si ton 70B ne rentre déjà pas en VRAM, TurboQuant ne fait rien pour ça.
C'est la différence entre avoir un bureau trop petit pour ton PC (→ problème de poids) vs avoir un bureau assez grand mais tes notes de travail débordent partout (→ problème de KV cache). TurboQuant résout le deuxième.
6/ L'histoire dingue: un dev solo devance Google.
Google publie le papier le 25 mars. Zéro code.
Tom Turney ouvre son terminal avec Claude. 7 jours plus tard :
→ Implémentation complète en C avec kernels Metal pour Apple Silicon
→ 4.6-4.9x de compression du KV cache
→ 102% de la vitesse de q8_0 (plus rapide, car moins de mémoire = moins de bande passante)
→ 511+ tests Python, 100% de couverture de code
→ Validé de 1.5B à 104B paramètres
Et il a trouvé des trucs qui NE SONT PAS dans le papier de Google :
• La compression des valeurs V est "gratuite" compresser V à 2 bits n'a aucun impact sur la qualité tant que les clés K restent précises
• La précision des clés K est le facteur dominant car elles contrôlent le routage de l'attention via softmax
• Les gros modèles absorbent mieux la quantization (104B : +3.6% PPL vs 70B : +11.4%)
Lui-même le dit : quand il écrit "j'ai implémenté", c'est en tandem avec Claude Code et Codex. "Juste beaucoup de pilotage et de babysitting."
Il n'a pas "battu" la recherche de Google. Il a battu Google sur la vitesse d'appropriation open source et la diffusion pratique.
C'est ça l'ère actuelle : un humain + une IA bien pilotée devance une grosse équipe corporate qui garde son code fermé.
Son repo turboquant_plus est déjà en cours d'intégration partout (llama.cpp, MLX, LM Studio...). Respect.
7/ Le résultat le plus fou
Command-R+ 104 MILLIARDS de paramètres. 128K tokens de contexte. Sur un MacBook M5 Max 128 Go.
74 Go de RAM peak. PPL de 4.024.
Un modèle de 104B. Sur un laptop. Avec 128K de contexte.
Il y a 2 ans, ça aurait nécessité un cluster de GPU serveur.
Autres résultats communautaires :
• Prince Canuma : 6/6 needle-in-haystack sur Qwen3.5-35B-A3B jusqu'à 64K tokens (MLX)
• RTX 4090 : output identique caractère par caractère à la baseline en 2-bit sur Gemma 3 4B
• Premier test AMD validé : Radeon RX 9070 XT fonctionne sans modifs
• M4 Pro 48 Go : 4.6x compression, 98% de la vitesse native sur Qwen2.5-32B
Si t'as une carte avec beaucoup de VRAM/RAM, prépare-toi : les modèles de 70-100B en contexte 128K+ sont en train de devenir la nouvelle normale. C'est pas demain. C'est maintenant.
8/ ça sert à quoi concrètement
Pour toi et moi :
• Conversations ultra-longues sans que l'IA oublie le début
• RAG sur des livres entiers en local
• Agents qui raisonnent sur des centaines de tours sans exploser
• LLMs locaux sur Mac/PC qui gèrent de vrais documents longs
• Assistants IA sur smartphone, sans cloud, sans censure
Pour les entreprises :
• 5-6x plus d'utilisateurs par GPU en datacenter → coûts d'inférence qui chutent
• Un cabinet d'avocats peut analyser un document de 1000 pages en local, sans envoyer ses données dans le cloud
Pour la recherche :
• Recherche vectorielle quasi-instantanée (Google Search, RAG, Spotify, Pinterest)
• Fenêtres de contexte de 1 million de tokens deviennent viables économiquement
Pour l'industrie :
• Moins de pression sur la HBM (mémoire ultra-chère des GPU), possible shift vers DDR5/MR-DIMM
• Pourrait desserrer un peu la pénurie mondiale de puces mémoire
9/ Le concurrent: Nvidia KVTC (aussi ICLR 2026)
Nvidia a sa propre approche, inspirée de... la compression JPEG.
• 20x de compression (vs 6x pour TurboQuant)
• < 1 point de % de perte de précision
• Testé de 1.5B à 70B (plus large que TurboQuant)
• Mais nécessite une calibration PCA offline par modèle
• S'intègre dans Dynamo + vLLM
Deux philosophies :
-> TurboQuant = plug-and-play, zéro config, marche sur tout
-> KVTC = compression max, mais faut préparer chaque modèle
La battle à ICLR 2026 fin avril va être intéressante.
10/ La limite de Shannon: on approche la frontière.
Le point que personne ne couvre assez :
L'erreur de TurboQuant approche la borne inférieure théorique de Shannon, à facteur constant près.
En clair : pour cette famille de méthodes (quantization data-oblivious du KV cache), on est PRESQUE au maximum de ce qu'il est mathématiquement possible de compresser.
Ça ne veut pas dire qu'il n'y aura plus d'avancée sur le KV cache. Mais la prochaine ne viendra probablement pas de "compresser encore plus dans le même paradigme". Il faudra changer d'approche : nouvelle architecture, nouvelle façon de gérer le contexte.
TurboQuant ne marque pas la fin de l'histoire. Il marque une frontière dans cette direction.
11/ La controverse
Jianyang Gao, post-doc à ETH Zurich et auteur de RaBitQ, accuse Google de citation insuffisante.
Son argument : le mécanisme central (rotation aléatoire + quantization optimale) serait structurellement trop similaire à RaBitQ, qui l'a publié en premier.
Réponse de Google : "La rotation aléatoire et le JL transform sont standard dans le domaine."
Gao a déposé une plainte au comité d'éthique ICLR. Le Stanford NLP Group a relayé sa position.
La contribution mathématique de TurboQuant est réelle. Le débat sur l'attribution est légitime. À ce stade, c'est une contestation publique, pas une faute établie.
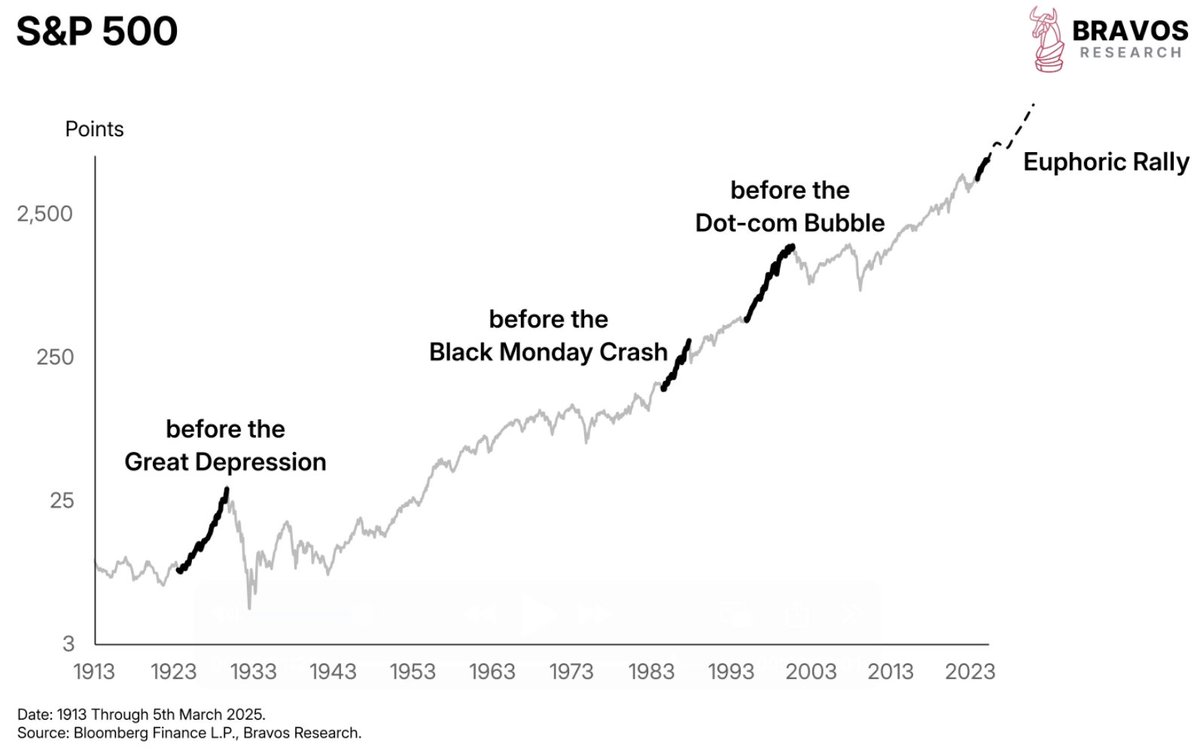
12/ L'impact marché
~90 milliards de $ de capitalisation en moins sur les actions mémoire en quelques jours. Le marché a pricé le risque d'une moindre demande en mémoire pour l'inférence.
Micron : -20% en 6 jours. SK Hynix : -6%. Samsung : -5%. SanDisk : -11% en un jour.
Le CEO de Cloudflare a appelé ça "le DeepSeek de Google".
Mais en face, Morgan Stanley, Citi et Wells Fargo avancent l'argument inverse : paradoxe de Jevons. Quand quelque chose devient moins cher, on en utilise PLUS, pas moins.
Rendre le contexte "moins cher" va probablement faire exploser son usage. Les actions mémoire ont pris un coup à court terme, mais la demande globale de tokens pourrait bien augmenter.
L'inférence représente déjà 60% des workloads IA et va vers 80%. Jensen Huang l'a dit à GTC 2026 : les datacenters sont des usines. Leur produit, c'est le token.
Rendre les tokens moins chers = en produire plus = probablement plus de mémoire nécessaire au final.
13/ En une phrase
TurboQuant ne rend pas l'IA plus intelligente.
Il la rend utilisable sur ton hardware à toi, sans cloud, sans censure, avec un contexte qui tient la route.
L'avenir des LLM n'est pas seulement dans les modèles plus gros. Il est dans le fait qu'on puisse enfin vraiment les faire tourner chez nous.
Et il marque le moment où la compression data-oblivious du KV cache approche sa limite théorique.
La suite ne sera plus "compresser mieux dans le même paradigme". Ce sera "penser différemment".