みさ
246 posts




@Misa_quantum 横から失礼します。
Amphetamine等のappではなくコマンドでスリープ防止をすることに何か別のメリットがあるのでしょうか?
当方非エンジニア故に分からず🙇♂️
日本語
sudo pmset -a disablesleep 1のコマンドだけで閉じてもスリープしなくなるよ
チャエン | デジライズ CEO《重要AIニュースを毎日最速で発信⚡️》@masahirochaen
Claude Codeがなかった時代 vs ある時代
日本語

@Misa_quantum 詳しくないのですが、もしかしてこのコマンドもclaude codeでいけたりします?
日本語
みさ retweetledi


TeX64 気づいたら500ダウンロード行ってました!
AI機能の課金をしてくださる方もいて、本当にありがたい限りです!!!
今後は、完全ノーコードでLaTeX文書が作れる機能を実装するつもりなので、ここ1ヶ月はガチで頑張ります!
TeX64@TeX64AI
We actually make our app’s download numbers public—and we’ve just passed 500 downloads! Incredibly grateful for your support. 🙌 tex64.com/downloads
日本語


@snjev310 @TeX64AI @arxiv Good catch on the rendering — arxiv's 'Export BibTeX' is styled as plain text rather than a hyperlink, making it easy to overlook. There's also a direct URL that bypasses the UI entirely: arxiv.org/bibtex/ARXIV_ID — reliable regardless of how the page renders.
English

The irony of @arxiv enforcing strict policies on hallucinated citations while downstream indexing tools can themselves introduce incorrect metadata. 👇
I tried fetching the official Google Scholar citation for the Gemma 3 Technical Report, but the returned BibTeX entry corresponded to an entirely different paper (Kimi-v2).
Scholar is out here hallucinating references before the AI even gets a chance to. 😭
Honestly, this does not seem like a difficult problem to catch automatically. Conferences and platforms like arXiv could include simple reference-verification checks during submission, similar to how formatting issues are flagged today.
English
@REasther @WKCosmo @welt_woman —InSPIRE codes are great for HEP — DBLP and ACL Anthology serve the same purpose for CS (DOI-keyed, curated, less prone to title-string collision). The broader principle holds: source authority beats title-matching every time.
English

@WKCosmo @welt_woman I always tell my students to make bibtex biographies with InSPIRE codes. They may cite the wrong paper but it would hard to cite a non-existent one.
English

This is really remarkable. Citations to nonexistent papers are not "typos", any more than fabricated data or synthetic figures are.
Ted Pavlic (he/him/his)@TedPavlic
@WKCosmo You're saying that you already do this? You are willing to vouch that no paper you've been co-author on has any typos (because you would have caught them in your complete read despite only being involved in some small aspect of the stats or methodology)?
English
@hatomatzu @Na2COOH_2 はとの二重定義が原因です。を削ってのみにすると直ります。の表示はの設定か、ソース中に誤った文字が紛れ込んでいる可能性があります。
日本語

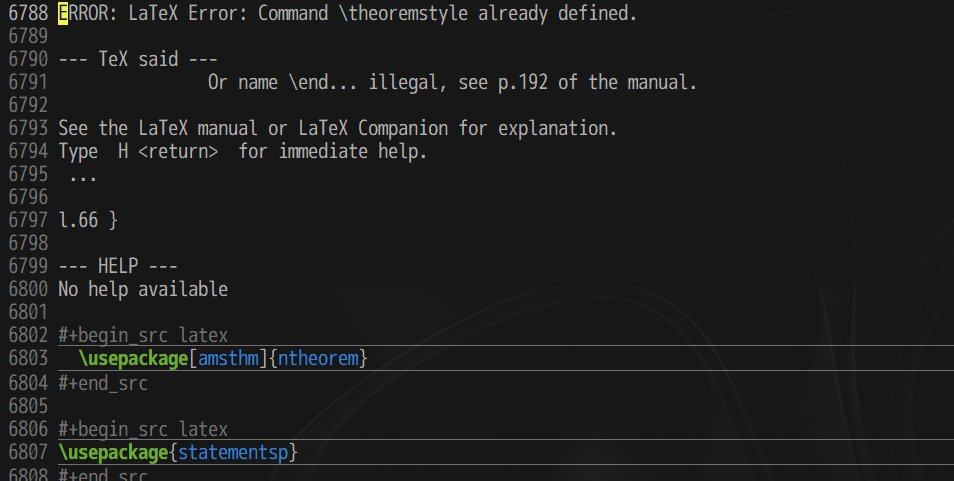
@Na2COOH_2 エラーの1つ目は ERROR: LaTeX Error: Command \theoremstyle already defined. で\usepackage[amsthm]{ntheorem} と競合してるのかエラーは出ますがコンパイルは通ります。
エラーの2つ目はエラー通知無いが、pdfの1ページ目か最後のページに ""と表示されるときがありました(原因不明)
日本語

みさ retweetledi

💡 Product Market Launched!
Inshihub ($INSHI)
Product: orynth.dev/projects/inshi…
Founder: @TeX64AI
English
@bettercallsalva @TeX64AI @QingQ77 The diff idea is underexplored. Most log output is stable boilerplate — a baseline diff surfaces only the signal. Three warning classes worth tracking even when it compiles: `Overfull \hbox`, `undefined reference`, `multiply defined labels`. They cascade.
English

@TeX64AI @Misa_quantum @QingQ77 showing the full log in parallel is something I underrate. usually fold it. but catching a fix that introduces a new warning matters as much as resolving the original. side-by-side diff of clean vs current log would be a small but real win
English

通过 Overleaf Git 桥将近实时同步 Overleaf 项目到本地 macOS 文件系统,让用户能用任意本地编辑器(Cursor、Claude Code、VS Code 等)协作编辑 LaTeX,同时自动处理冲突和推送。
github.com/eric-xw/Overle…
用 SwiftUI 写的 macOS 原生应用,靠 Overleaf Git 桥把项目拉到本地磁盘。手动一键 Pull/Push,也能开自动同步后台定时拉取、保存后几秒自动推送,端到端大约 30 秒。撞上同行冲突时,自动操作暂停,弹出橙色徽章让你手动选保留哪边。

中文
@gladomat @jonashernlund @karpathy Beamer is great for this — the structure maps cleanly to LLM output. One thing that helps further: an AI agent that edits the .tex directly rather than regenerating the whole file. TeX64 does this on Mac (reads context, edits in-place): tex64.com
English

@jonashernlund @karpathy Just make it write latex presentations with the beamer class. Much less code, much more compression, less token usage.
English

This works really well btw, at the end of your query ask your LLM to "structure your response as HTML", then view the generated file in your browser. I've also had some success asking the LLM to present its output as slideshows, etc.
More generally, imo audio is the human-preferred input to AIs but vision (images/animations/video) is the preferred output from them. Around a ~third of our brains are a massively parallel processor dedicated to vision, it is the 10-lane superhighway of information into brain. As AI improves, I think we'll see a progression that takes advantage:
1) raw text (hard/effortful to read)
2) markdown (bold, italic, headings, tables, a bit easier on the eyes) <-- current default
3) HTML (still procedural with underlying code, but a lot more flexibility on the graphics, layout, even interactivity) <-- early but forming new good default
...4,5,6,...
n) interactive neural videos/simulations
Imo the extrapolation (though the technology doesn't exist just yet) ends in some kind of interactive videos generated directly by a diffusion neural net. Many open questions as to how exact/procedural "Software 1.0" artifacts (e.g. interactive simulations) may be woven together with neural artifacts (diffusion grids), but generally something in the direction of the recently viral x.com/zan2434/status…
There are also improvements necessary and pending at the input. Audio nor text nor video alone are not enough, e.g. I feel a need to point/gesture to things on the screen, similar to all the things you would do with a person physically next to you and your computer screen.
TLDR The input/output mind meld between humans and AIs is ongoing and there is a lot of work to do and significant progress to be made, way before jumping all the way into neuralink-esque BCIs and all that. For what's worth exploring at the current stage, hot tip try ask for HTML.
Thariq@trq212
English
@Marsdkruskal @gdb Font chaos is engine + font embedding — pdfLaTeX, LuaLaTeX, XeLaTeX all handle fonts differently. Native MacTeX on Mac eliminates most cross-platform issues. If you're on Mac, TeX64 adds an AI agent that reads .tex files and fixes compile errors directly: tex64.com
English


Daybreak: our umbrella effort for defensive acceleration, equipping cyber defenders with the best possible frontier AI capabilities.
OpenAI@OpenAI
Introducing Daybreak: frontier AI for cyber defenders. Daybreak brings together the most capable OpenAI models, Codex, and our security partners to accelerate cyber defense and continuously secure software. A step toward a future where security teams can move at the speed defense demands.
English
@bettercallsalva @QingQ77 Round-trip latency is exactly what TeX64 tackles — the AI agent edits your .tex files directly on disk, no cloud involved. Compile+fix loops run locally with MacTeX in under a second. If you're on Mac, worth a try: tex64.com
English
@QingQ77 LaTeX local editing with agent help is the part Overleaf undersells. Git bridge plus Claude Code lets you ask 'rewrite methods in passive voice' across 40 pages without losing labels or bibtex keys. Round trip latency stays the real bottleneck.
English