
Morgann
39 posts

Morgann
@MorgannSabatier
Data Scientist junior @Le_Museum Masters in NLP/computational linguistics. #NLP #DataScience Diversity in video games 🌈
Paris Katılım Kasım 2021
57 Takip Edilen14 Takipçiler

@MorgannSabatier Bonsoir le prochain train POMA pour votre parcours est actuellement prévu à 21h34 selon mes informations. J'attire tout de même votre attention sur le fait que le trafic est très perturbé. Vérifiez cette information avant de vous déplacer.
Nathan
Français
@LigneH_SNCF bonjour, est-il possible de rejoindre Domont depuis Gare du Nord ?
Français
@EquipeFRA bonjour, vous sauriez me dire s’il reste des places pour le Club France à la billetterie sur place ? 😊
J’ai ma place mais une amie souhaiterait m’accompagner, j’avais lu que des places étaient en vente à la Villette.
Français
@MorgannSabatier Bonjour, un train est actuellement à Domont, avez vous pu monter à bord?
Français
@LigneH_SNCF bonjour, pourriez-vous m’indiquer à quel heure partira le prochain train de Domont vers Paris GDN ?
Français
Morgann retweetledi


Morgann retweetledi

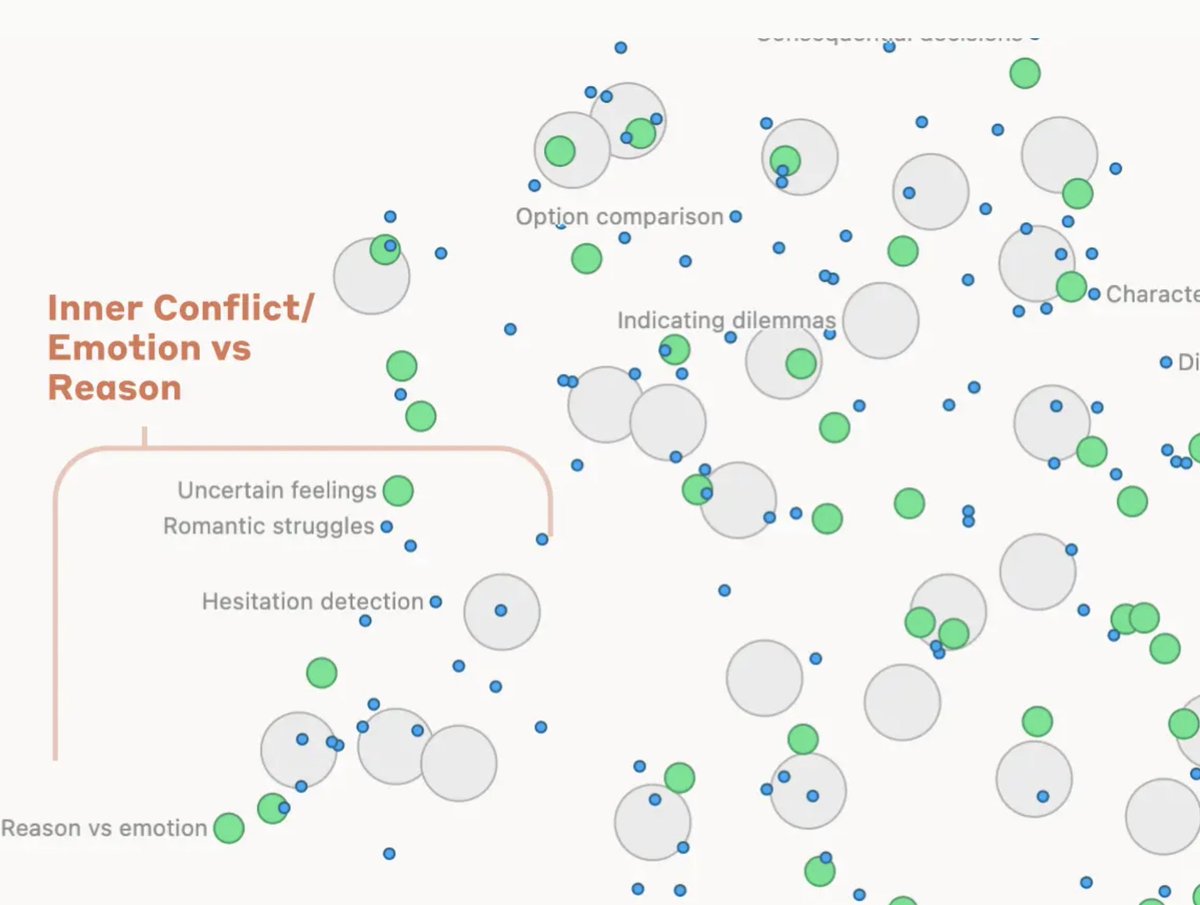
Understanding LLMs - Mapping the Mind of An AI Model
The more we understand the inner workings of the LLM, the more we will be comfortable with it.
Even top researchers don't completely understand how they work. Today, Anthropic released an important paper that help further our understanding of this important topic.
Anthropic previously used a technique called "dictionary learning," borrowed from classical machine learning. Fundamentally, it's about isolating recurring neuron activation patterns across different contexts.
Every feature in an AI model is made by combining neurons, and every internal state is made by combining features.
Anthropic has previously found coherent features corresponding to concepts like uppercase text, DNA sequences, surnames in citations, nouns in mathematics, or function arguments in Python code in a toy LLM.
They extracted millions of features from the middle layer of Claude Sonnet and provide a rough conceptual map of its internal states halfway through its computation. This is the first-ever detailed look inside a modern, production-grade large language model!!
By extracting these features, they show that the internal organization of concepts in the AI model corresponds somewhat to our human notions of similarity.
When you modify or change the feature, the model behaves completely differently. You can manipulate the features to manipulate model behavior.
Understanding LLMs is extremely important, and I am glad Anthropic is investing a significant amount of compute and research bandwidth in this area.
The more we understand LLMs, the less of a black box they will be and the more comfortable we will be with these models.
Congrats to Anthropic on this great piece (link in alt)👏👏
English

Morgann retweetledi

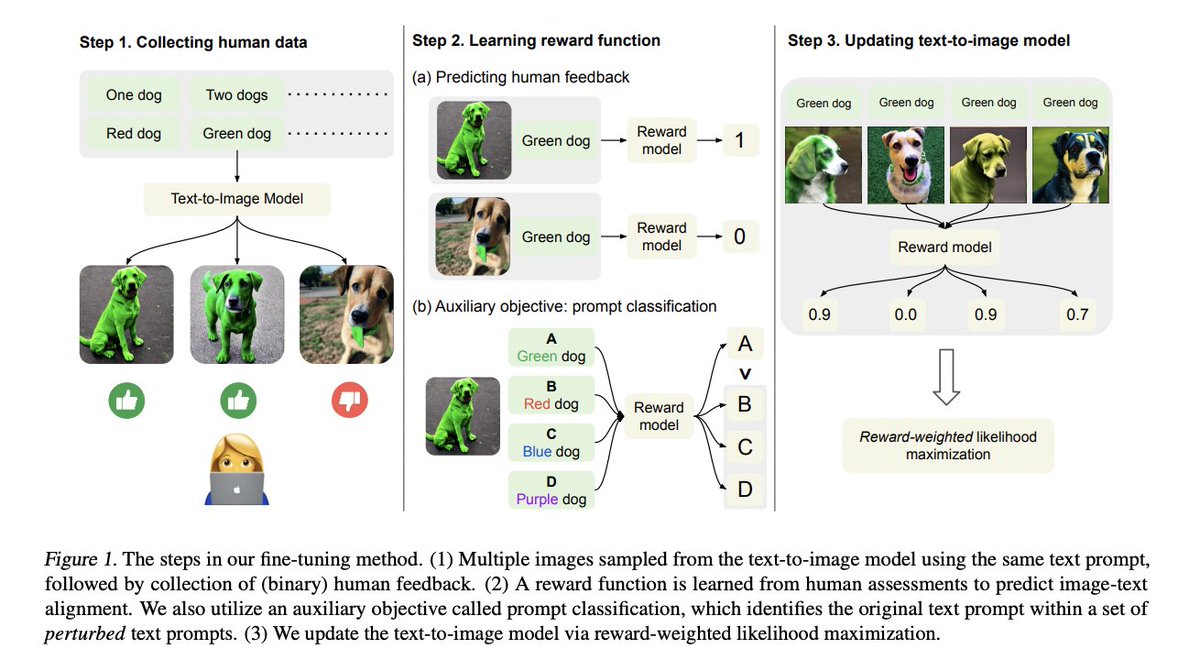
QLoRA: 4-bit finetuning of LLMs is here! With it comes Guanaco, a chatbot on a single GPU, achieving 99% ChatGPT performance on the Vicuna benchmark:
Paper: arxiv.org/abs/2305.14314
Code+Demo: github.com/artidoro/qlora
Samples: colab.research.google.com/drive/1kK6xasH…
Colab: colab.research.google.com/drive/17XEqL1J…

English
Morgann retweetledi

La journée sur l'interdisciplinarité du @reseau_pamir à @Sorbonne_Univ_ se poursuit sur une belle table ronde avec Diego Jarak @lunulabide, Clément Levallois @seinecle, @ClaireNedellec, @MorgannSabatier et Darshan Sathiyanarayanan.

Français
Morgann retweetledi

Morgann retweetledi

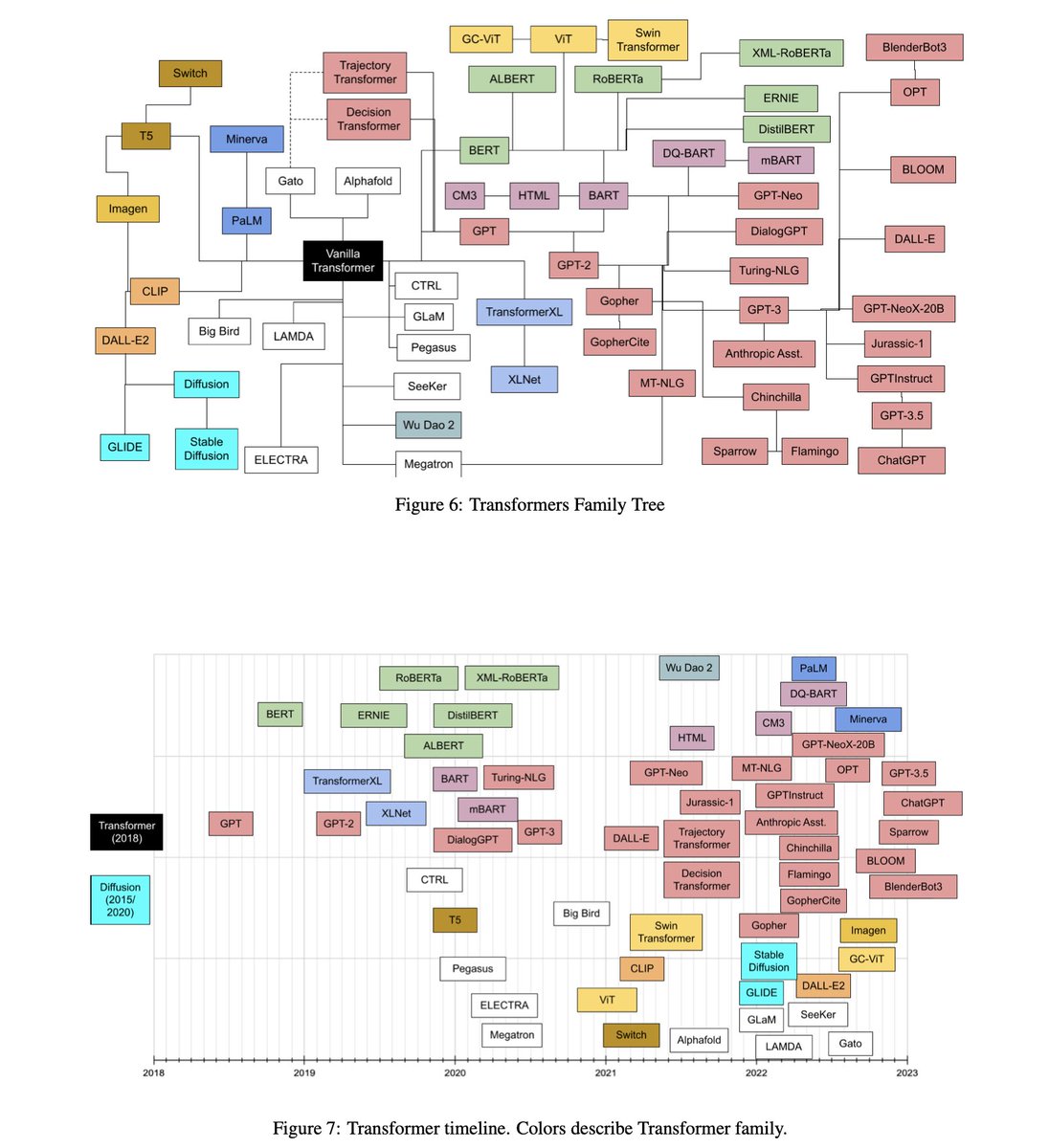
Transformer models: an introduction and catalog
A super concise and brief overview of almost all popular Transformer models. Written well and provide pointers for recent advances in Transformer model architectures.
arxiv.org/abs/2302.07730
English
Morgann retweetledi

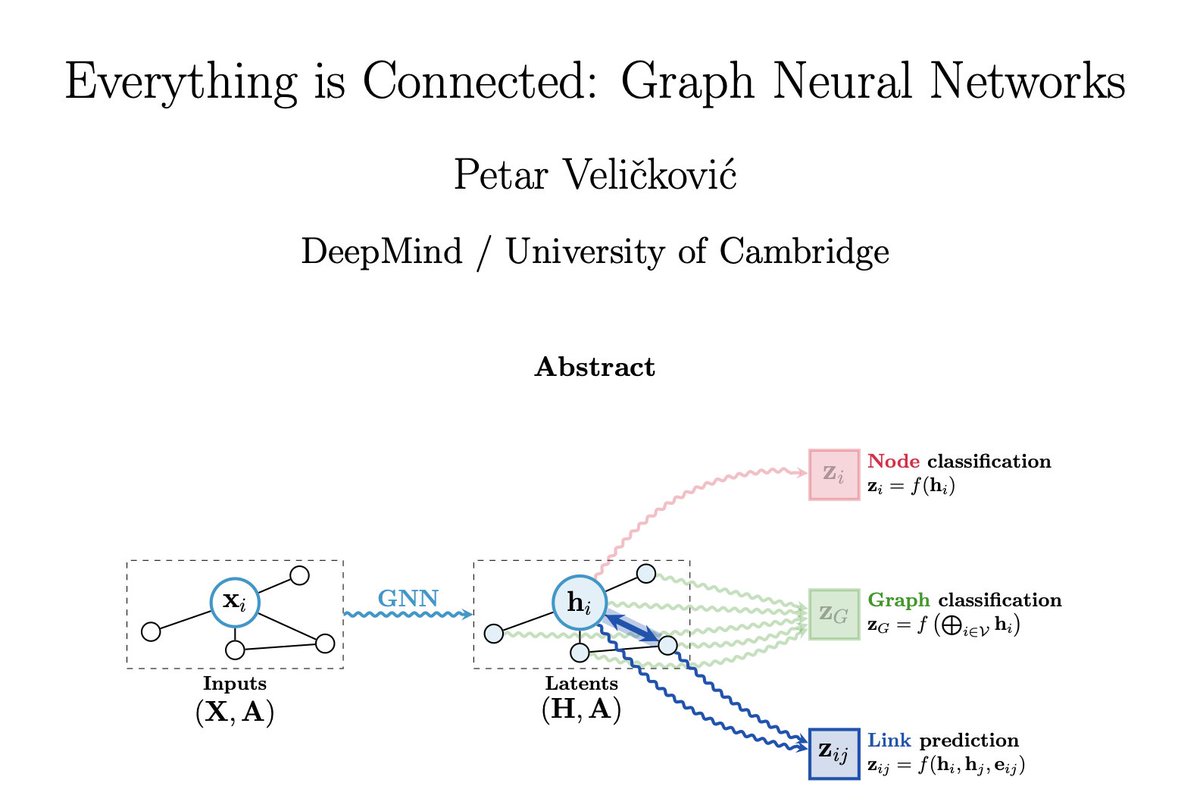
Happy Lunar NY 🎉
Just read @PetarV_93's "Everything is Connected". I spent most of 2022 studying Transformers for graphs and this paper intuitively connects most of what I've learned!
🔗: arxiv.org/abs/2301.08210
Here's an executive summary if you haven't caught it yet!
1/9
English
Morgann retweetledi

Clever paper — HyDE: Hypothetical Document Embeddings
Instead of encoding the user's query to retrieve relevant documents, generate a "hypothetical" answer and encode that. Documents with right answers more similar to wrong answers than to questions. arxiv.org/abs/2212.10496

English
I just completed "Dive!" - Day 2 - Advent of Code 2021 adventofcode.com/2021/day/2 #AdventOfCode
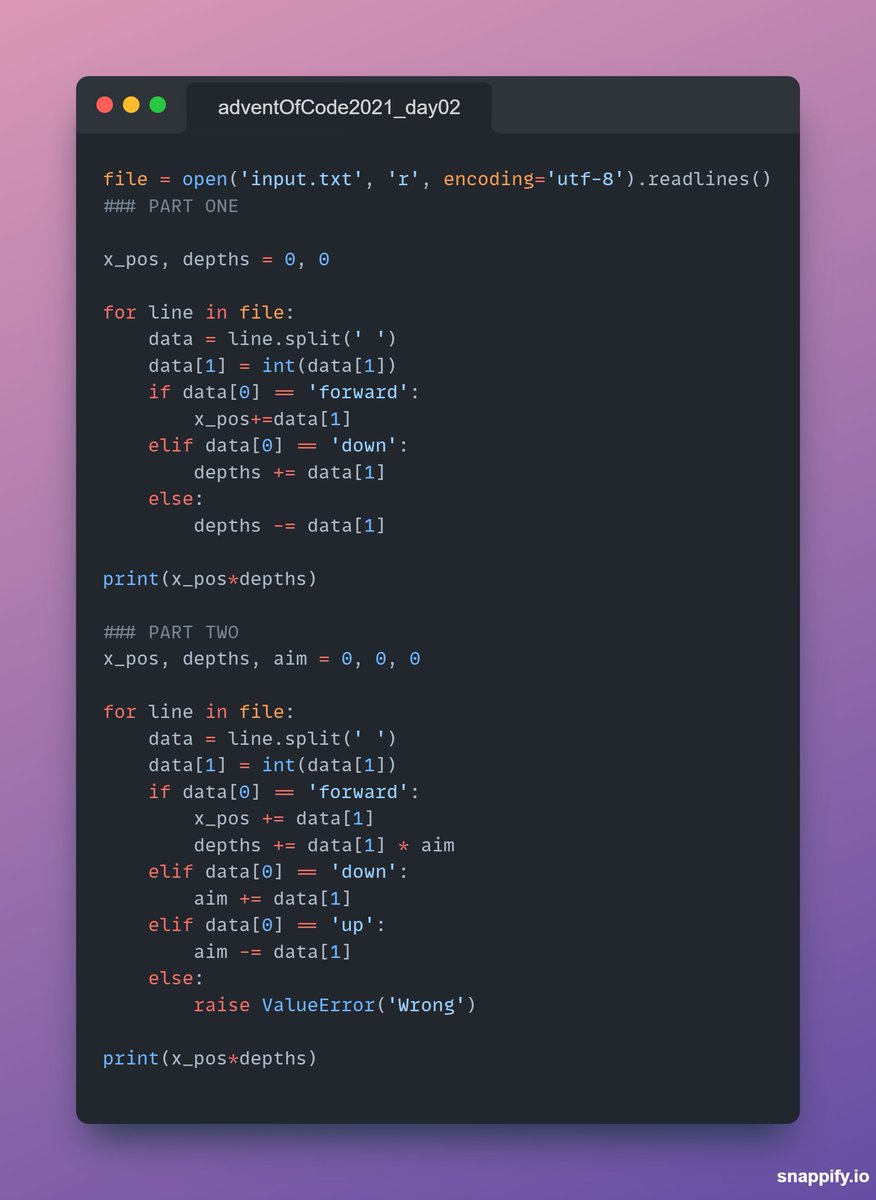
English
I just completed "Sonar Sweep" - Day 1 - Advent of Code 2021 adventofcode.com/2021/day/1 #AdventOfCode
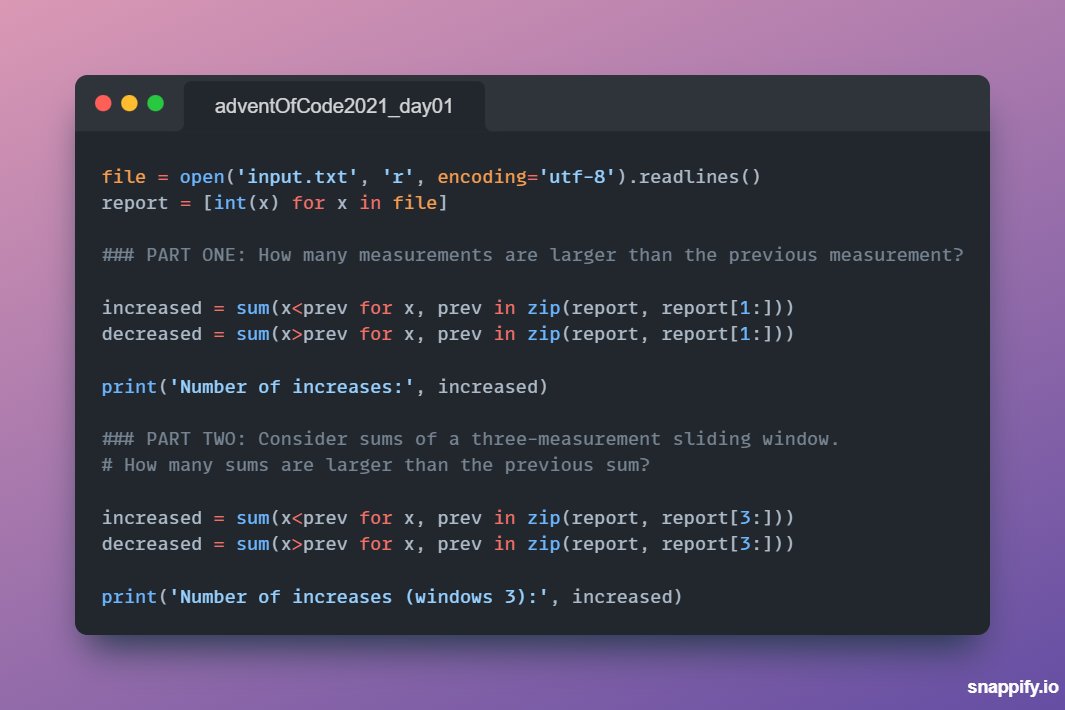
English
@MakadiaHarsh 👋Hey, this looks cool! Would love to take a look at it :)
English

I curated 50+ best resources to learn programming by playing games.
Resources include games for:
• CSS
• Javascript
• Git
• Regex
• Python
• Ruby
• SQL
• Online Playgrounds
Steal it now for $0 💰
Drop a 👋🏻 in the comment and I'll DM you the link instantly.

English
🗓 Day 11 & 12 - Datadatadatadata
✅Some Twitter API practice
✅Data analysis on a Google Apps dataset for a @DataCamp project + Sentiment analysis
#100DaysOfCode #Python
English